本文主要是介绍【Linux】-进程间通信-共享内存(SystemV),详解接口函数以及原理(使用管道处理同步互斥机制),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

💖作者:小树苗渴望变成参天大树🎈
🎉作者宣言:认真写好每一篇博客💤
🎊作者gitee:gitee✨
💞作者专栏:C语言,数据结构初阶,Linux,C++ 动态规划算法🎄
如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧!
文章目录
- 前言
- 一、共享内存的原理
- 二、直接代码
- 2.1关于共享内存的四大接口
- 2.2如何通信
- 三、扩展知识
- 3.1 看看维护共享内存的结构体属性
- 3.2 使用管道来实现同步互斥机制
- 四、总结
前言
今天我们来讲进程间通信的的另一个通信方式,在第一篇讲解进程间通信的博客中,博主就提到了SystemV标准的通信方式,我们前面讲解的匿名管道和命名管道都是基于文件的,但是共享内存不是基于文件的,他的所有进程间通信最快的,因为他的拷贝少,共享内存的难点就在于他的接口多,复杂,因为SystemV标准下不止一个共享内存,还有消息队列和信号量,都需要类似的接口,为了可以更好的复用接口函数,接下来博主就来带大家学习共享内存。
讲解逻辑:
- 直接原理,讲解周边问题
- 通过原理,写一部分代码,认识系统接口,进行测试
- 扩展代码去讲解
一、共享内存的原理
使用共享内存的目的是让进程间进行通信,但是进程间通信的本质是让不同的进程看到同一份资源,由共享内存这个名字可知,这篇共享的资源是一块内存,计算机中我们一般由的地址要不是虚拟地址,要不是物理地址,想形成可执行程序里面的地址我们目前不谈,而虚拟地址是每个进程特有的,所以我们猜测这块共享内存是物理内存的一块,因为有了前面的两次通信方式的铺垫,我们已经慢慢找到规律了,那博主就以一份图给大家讲解一下共享内存的原理。
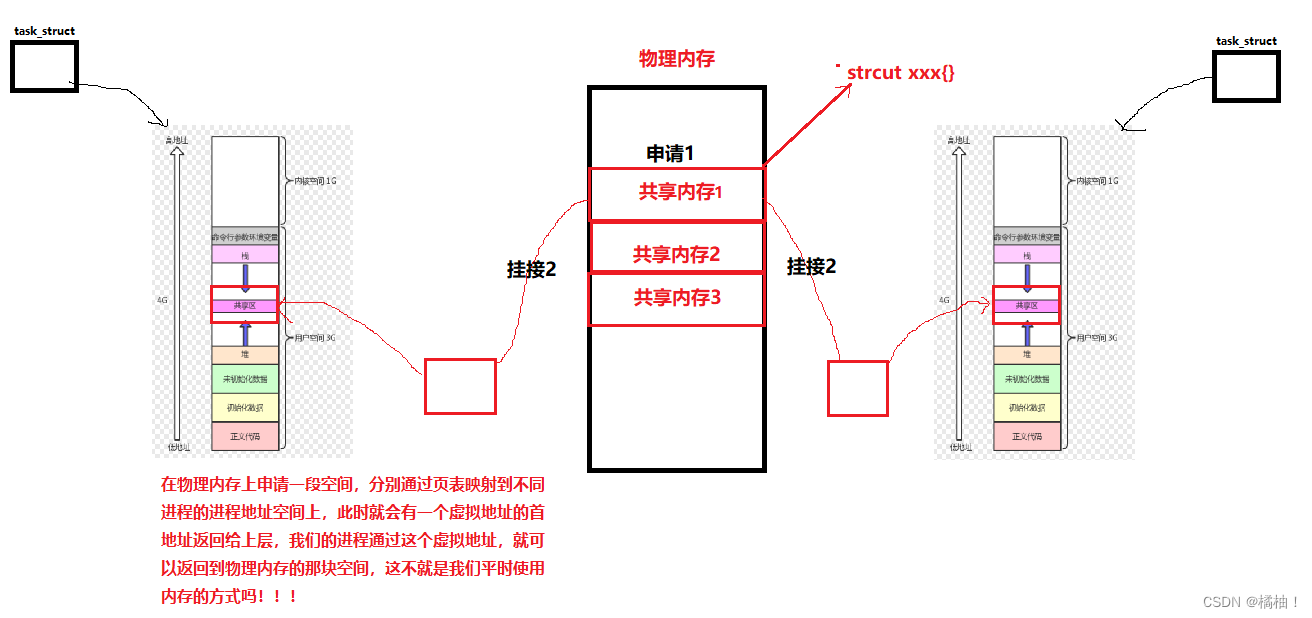
共享内存的原理很简单,就上幅这个图片,但是博主要讲一些周边问题:
- 释放共享内存,先去挂接,再释放内存,是相反的操作
- 上面的操作都是进程直接做的吗??不是,是直接由os去做的,原因涉及到物理内存了。
- 那既然有os去操作的,那么我们去创建,使用或者释放都需要经过系统调用接口去让os帮助我们实现
- 我们的不同进程通过共享内存进行通信,另外的进程也需要通过共享内存来进行通信,那么共享内存就不止一块,由许多快,那么这块共享内存都是需要管理起来的,所以先描述再组织,就对应我们上图的struct结构体。里面存放的是对共享内存的管理属性。
所以我们一会对共享内存的使用里面肯定会涉及到这个结构体里面的属性,等会遇到了一个讲一个,现在都讲解出来读者大概率不会理解。
二、直接代码
我们通过刚才的原理分析,而且这些操作是需要通过系统调用接口的,所以我们一步步的来介绍这些系统调用接口。
2.1关于共享内存的四大接口
一、申请共享内存接口

- 返回值(用户层)shmid:此函数申请一块共享内存,返回共享内存标识符,可以先理解为和文件描述符唯一标志文件一样的道理。
- 第二个参数,是申请共享内存的大小。单位是字节
- 第三个参数:共享内存是为了给不同的进程使用,那么使用这块内存之前,只要由一个进程创建,其他进程拿来用就行了,那这个参数就是控制对共享内存的权限操作,来看我们自己要掌握的权限
(1)IPC_CREAT:(单独使用)如果你申请的共享内存不存在就创建,存在就获取返回
(2)IPC_CREAT | IPC_EXCL:如果你申请的共享内存不存在就创建,存在就报错,这是保证了你创建的共享内存是最新的。IPC_EXCL不单独使用
(3)第三个就是传我们对应的权限,如0666上面的方式我们再讲解文件操作的时候就讲解过了,write函数里面需要传这样的参数,这些大写字母起始就是对应的宏。
- 第一个参数:通过第三个参数,我们怎么知道这个共享内存存不存在,就好比你怎么保证让不同的进程看到同一份共享内存是一样的,此时就有了我们的第一个参数,接下来谈谈这个key。
(1)key是一个数字,这个数字是多少不重要。关键在于他必须再内核中具有唯一性,能够让不同的进程进程唯一标识
(2)第一个进程可以通过key来创建共享内存。第二个进程之后的进程,只要拿着这个key就可以和第一个进程看到同一个共享内存了
(3)对于一个已经创好的共享内存,key在哪??大家还记得一个说管理共享内存的结构体吗,key就在共享内存的描述对象里
(4)通过第一点想要key去唯一标识共享内存,大家再回想一下命名管道是怎么唯一标识的,是不是通过就和文件名,所以这个key应该也类似于命名管道的标识方式。
(5)通过第二点,我们通过key创建共享内存,那么第一次创建的时候,这个key怎么有???我们总结出四个结论和一个问题,问题来到了这个key一开始时怎么产生的了,按照第四点的结论,我们来介绍一下这个函数
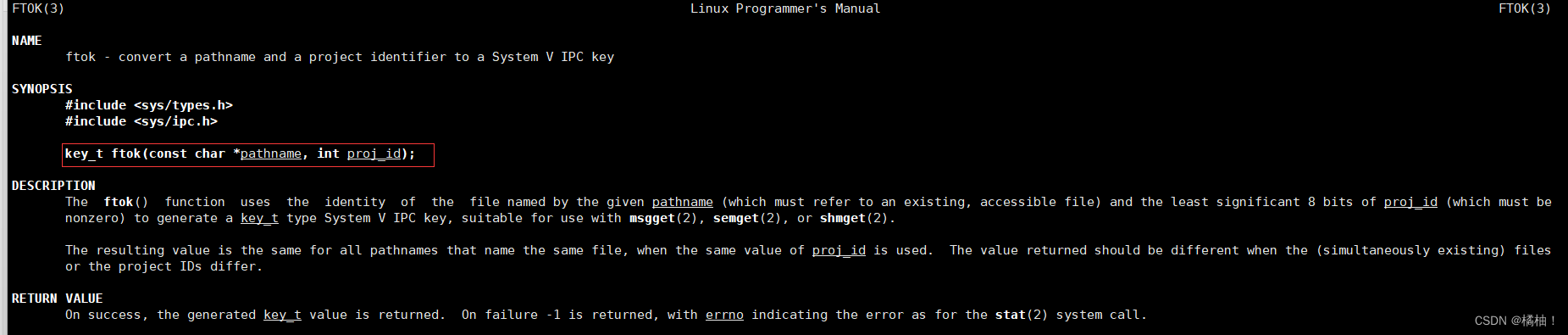
ftok
第一个参数:路径这个随便写
第二个参数,这个是工程id,我们可以随便去指定是一个数字
返回值(内核层):是一个共享内存标识符我们上面的两个参数都是由用户自己去定义的,所以可能会和系统中的key产生冲突,这个函数是通过一个算法将两个参数进行运算的出来的这样的一个key,每次生成的结果都是不一样的,不是你每次传的参数一样计算出来的结果就是一样的。这样为什么就可以做到key是唯一的呢,我们的路径是唯一的,而且第二个参数是我们自己传,大概率也是唯一的,这样就导致我们的key是唯一的,而且一旦创建这个key就是这个共享内存所独有了,如果再生成这个key,只能获取,不会再创建一个新的了
为什么key不由os自己创建呢,我们自己创建还有可能造成key冲突的问题??
(1)再谈谈key的时候的第二点我们知道这个我们通过创建共享内存是由一个进程去创建另一个进程去使用就可以,如果这个key是os生成的,创建好的共享内存,那另一个没有关系的进程怎么获取这块共享内存,因为共享内存不是唯一的,所以os里面的key也不是唯一的,所以没有办法给另一个进程让他获取啊,有的人说传给另一个进程,这样就出现蛋生鸡的问题,另一个进程要key才能进行通信,但是要key必须先通信,如果共享内存的个数是唯一的,那么可以让os自己生成,大家自己理解一下
(2)这个key的获取可以说是用户的约定,和哪个进程通信只有用户知道,就是程序员知道,两个进程使用ftok这个相同的方式就可以获取唯一的key,因为这两个参数是唯一的
(3)有的人会说我们将系统自己生成的key通过管道传给另一个进程就可以了,答案确实可以,但是这样我们学习共享内存的成本就搞了,还要先学习管道,这样也不嫩恶搞保证共享内存是一个独立通信模块了大家看到这里对于key的理解应该到位了,但是有一个关键的点,key vs shmid
这两个都是共享内存的标识符,他两有一个不就行了,key是内核中唯一标识的,shmid只有再进程里唯一标识的,我们操作共享共享内存的函数都是使用shmid。

通过上面的一系列分析,我们来申请一块共享内存:shmget+ftok
sham.hpp:
#ifndef __COMM_HPP__
#define __COMM_HPP__#include <iostream>
#include <string>
#include <cstdlib>
#include <cstring>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/types.h>
#include <sys/types.h>
#include <sys/stat.h>#include "log.hpp"using namespace std;Log log;const int size = 4096;
const string pathname="/home/xdh";
const int proj_id = 0x6666;key_t GetKey()
{key_t k = ftok(pathname.c_str(), proj_id);if(k < 0){log(Fatal, "ftok error: %s", strerror(errno));exit(1);}log(Info, "ftok success, key is : 0x%x", k);return k;
}int GetShareMemHelper(int flag)
{key_t k = GetKey();int shmid = shmget(k, size, flag);if(shmid < 0){log(Fatal, "create share memory error: %s", strerror(errno));exit(2);}log(Info, "create share memory success, shmid: %d", shmid);return shmid;
}int CreateShm()//创建共享内存得到标识符shmid,进行了封装
{return GetShareMemHelper(IPC_CREAT | IPC_EXCL | 0666);
}
#endif
processa.cc:
#include"sham.hpp"
//这是进程a,有这个进程创建共享内存
int main()
{//申请共享内存int shmid=CreateShm();sleep(5);return 0;
}
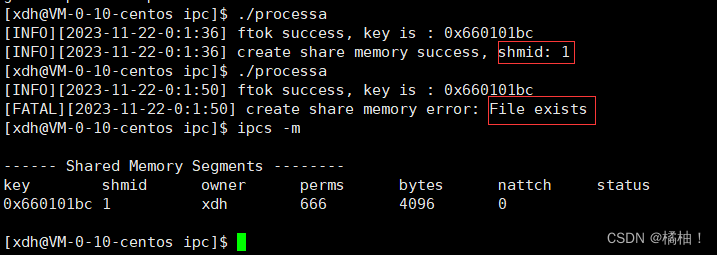
通过结果我们发现,我们第一次运行程序的时候申请了一块共享内存获得了共享内存标识符,但是第二次运行的时候显示就存在了,我们使用
ipcs -m查看共享内存,我们得出结论,进程结束了,我们的共享内存还是存在的,共享内存的生命周期是随着内核的,不是随着进程的,通过原理图也不难理解这点,没有关闭共享内存,这也可能会造成内存泄漏,类似于malloc。这里面我们再来研究一个点,我们申请4097个字节大小的空间看看效果
我们看到大小是4097,在内核里面,我们的os实际上会给我们的4096*2大小的空间,但是我们只能使用4097,这个大家要记住,所以建议还是申请4096点整数倍,折合人民币我们内存的页宽有关系,大家先不用了解。

二、.挂接共享内存:shmat函数
我们的共享内存申请好了,我们就需要将其挂接到我们的地址空间上,就是原理图上的第二步
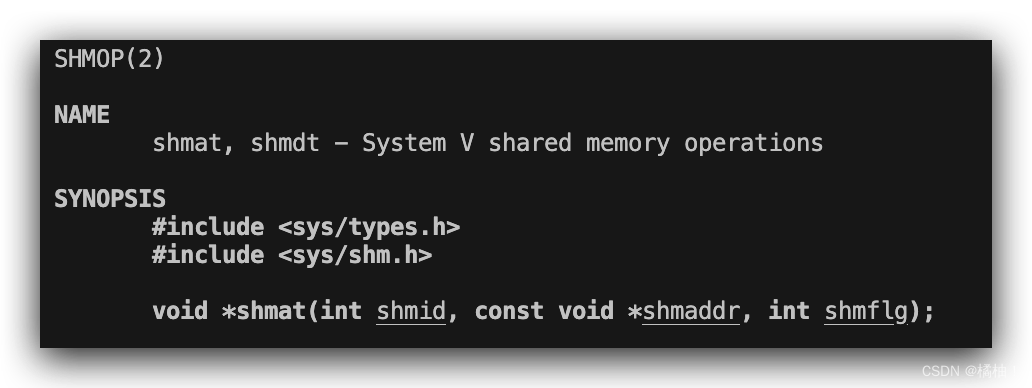
- 第一个参数:就是传刚才使用shmget函数的返回值即可是共享内存的唯一标识符
- 第二个参数:指定挂接到那个位置,我们申请好了共享内存,要挂接到我们进程的地址空间的共享群位置,这么多位置总要找到一个位置的其实位置吧,这样也方便我们页表进行映射,所以需要制定,我们在这里传空指针就好了,意思让系统自己决定
- 第三个参数:是挂接的方式
我们在这里传0进去就好了
- 返回值:我们就是把挂接到地址空间的那块位置的首地址返回出来,让用户能拿到,进行操作,所以返回值是void需要强转,和malloc类似,失败就返回(void)-1

我们来看代码实现:
//将共享内存挂接到自己的地址空间char* shmaddr=(char*)shmat(shmid,nullptr,0);if(*shmaddr<0){log(Fatal,"shmat flase:%s",strerror(errno));exit(3);}log(Info,"shmat sucessful:%s",strerror(errno));sleep(3);
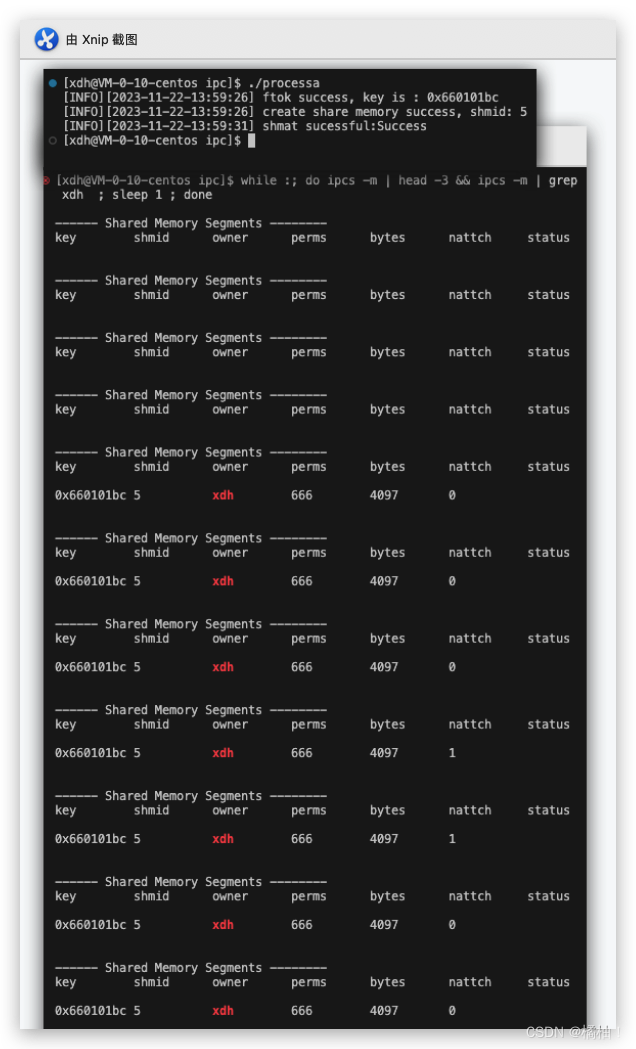
我们来观察一下nattch这个属性,他就是表示这块共享内存当前的挂接树,没调用这个shmat函数之前为0,调用之后为1,而且当进程退出他的挂接数自然的就减少了1
三.去掉挂接关系:shmdt
刚才是因为程序结束,挂接数减少了,但我们有时候程序没结束就像去挂接,怎么做??我们通过shmdt来去挂接,来看文档
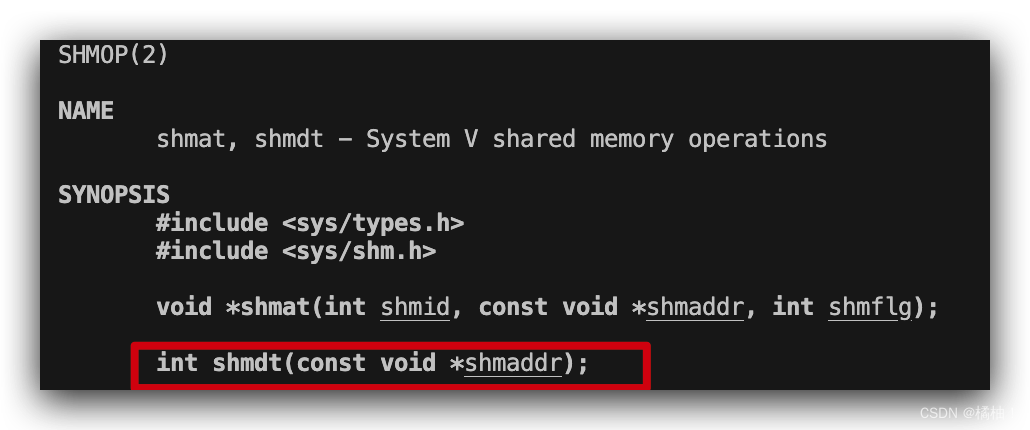
这个函数非常的简单,就是传刚才挂接函数返回值就可以了,我们直接来看使用效果:
我们分析,我们3秒后创建共享内存,5秒后挂接进程,挂接数变成1,3秒后,去挂接,挂接数变成1,在3秒后程序终止,
int n=shmdt(shmaddr);if(n<0){log(Fatal,"shmdt flase:%s",strerror(errno));}log(Info,"shmdt sucessful:%s",strerror(errno));sleep(3);
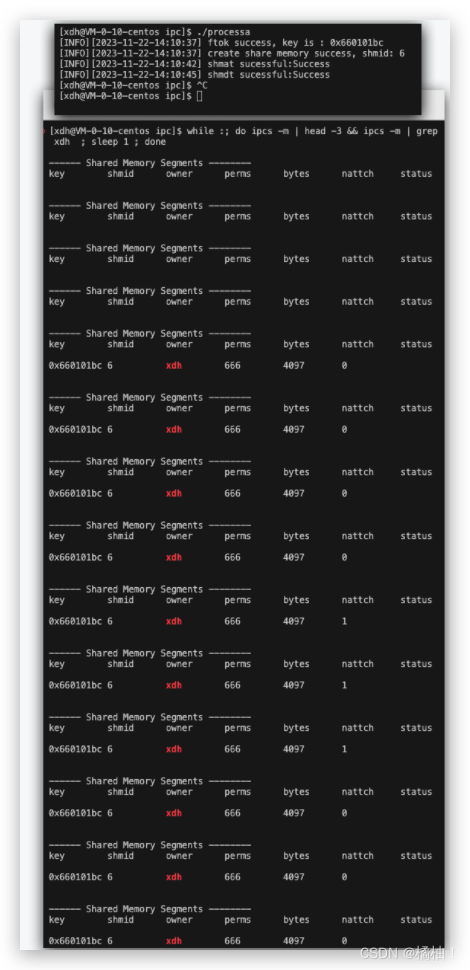
和我们预测的一样,我们的挂接数不一定非得在程序结束才会减1
四.释放共享内存:shmctl
我们想要将我们的共享概念内存释放掉使用shmctl
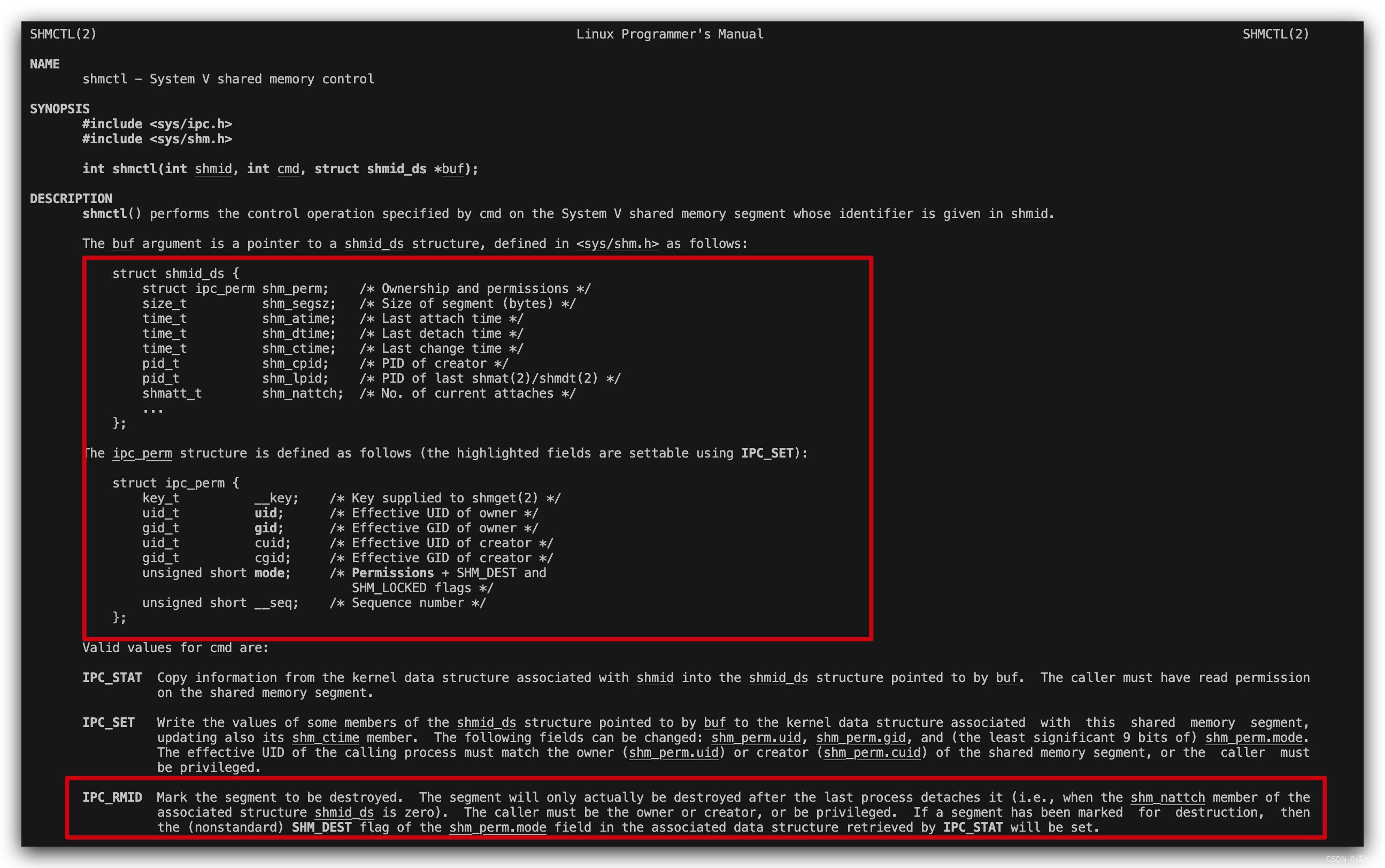
第一个参数:共享内存唯一标识符
第三个参数:是一个描述共享内存的状态和访问权限的数据结构,也就是我们开头说的描述共享内存的结构图,看到key在里面了吧,对于这个参数我们可以传一个null,因为不需要将状态获取到,这是一个输出型参数和status一样。
第二个参数:将要采取的动作,就是对第三个参数实行什么样的操作,有三个操作
我们关注的是最后一个,删除共享内存

来看操作:
int n1=shmctl(shmid,IPC_RMID,nullptr);if(n1<0){log(Fatal,"shmctl flase:%s",strerror(errno));}log(Info,"shmctl sucessful:%s",strerror(errno));sleep(3);
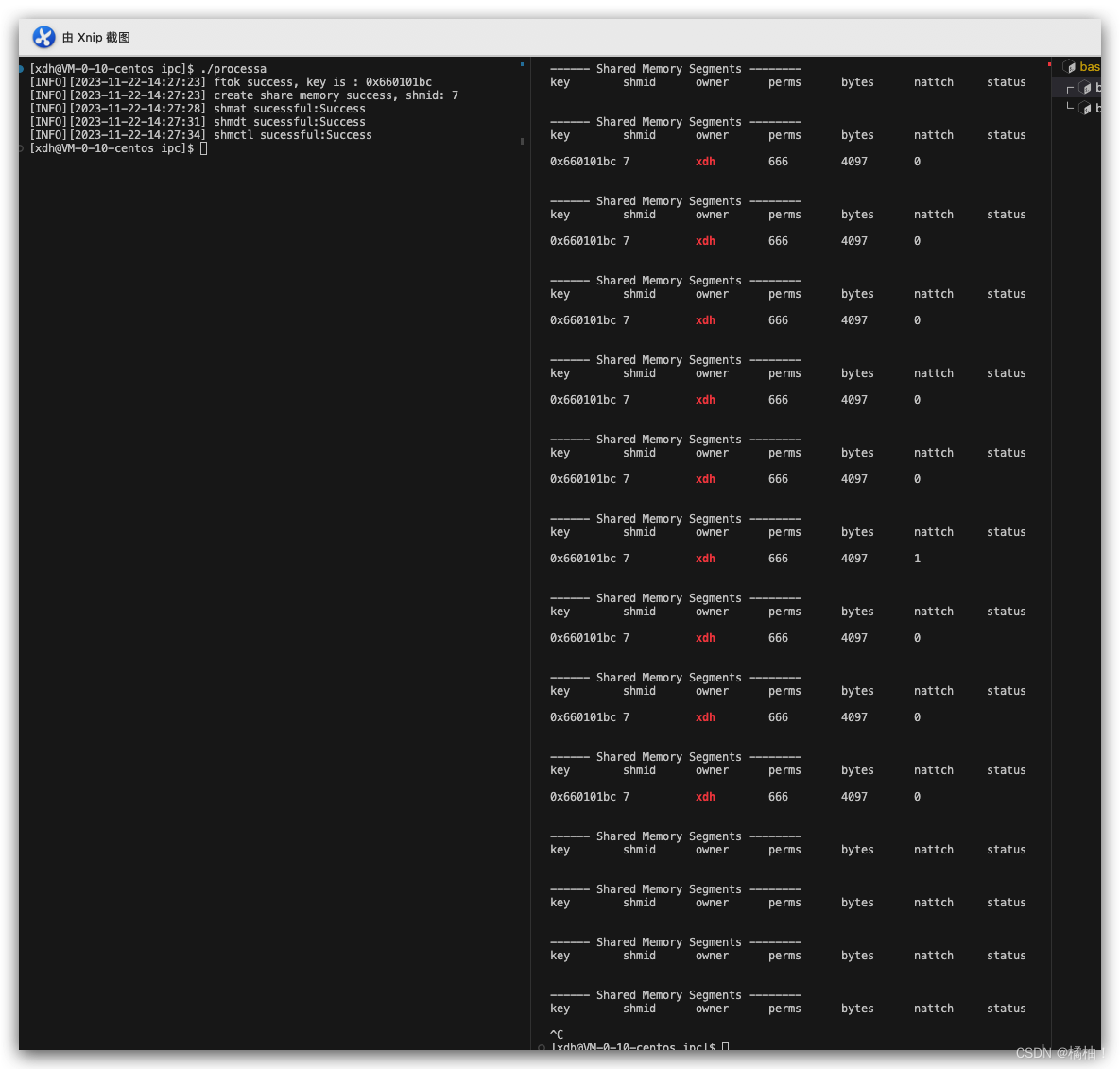
通过结果验证我们的讲解,我们也可以通过
ipcrm -m +shmid来删除共享内存,这个大家下去试试,但是shmctl传进去的操作不一样,功能就不一样,如果传IPC_STAT,就可以查看属性。
我们将另一个进程也挂接到这个共享内存上吧,因为申请和释放进程a帮助我们做了,我们做的就是挂接和去挂接就可以了,来看进程b的代码:
先展示进程a的代码:
#include"sham.hpp"
//这是进程a,有这个进程创建共享内存
int main()
{sleep(3);//申请共享内存int shmid=CreateShm();sleep(5);//将共享内存挂接到自己的地址空间char* shmaddr=(char*)shmat(shmid,nullptr,0);if(*shmaddr<0){log(Fatal,"shmat flase:%s",strerror(errno));exit(3);}log(Info,"shmat sucessful:%s",strerror(errno));sleep(3);//去挂接int n=shmdt(shmaddr);if(n<0){log(Fatal,"shmdt flase:%s",strerror(errno));}log(Info,"shmdt sucessful:%s",strerror(errno));sleep(3);//释放共享内存int n1=shmctl(shmid,IPC_RMID,nullptr);if(n1<0){log(Fatal,"shmctl flase:%s",strerror(errno));}log(Info,"shmctl sucessful:%s",strerror(errno));sleep(3);return 0;
}
进程b:
#include "sham.hpp"int main()
{sleep(3);int shmid=GetShm();//这个函数在sham.hpp里面写就行了,获取shmidsleep(5);//将共享内存挂接到自己的地址空间char* shmaddr=(char*)shmat(shmid,nullptr,0);if(*shmaddr<0){log(Fatal,"shmat flase:%s",strerror(errno));exit(3);}log(Info,"shmat sucessful:%s",strerror(errno));sleep(3);//去挂接int n=shmdt(shmaddr);if(n<0){log(Fatal,"shmdt flase:%s",strerror(errno));}log(Info,"shmdt sucessful:%s",strerror(errno));sleep(3);return 0;
}
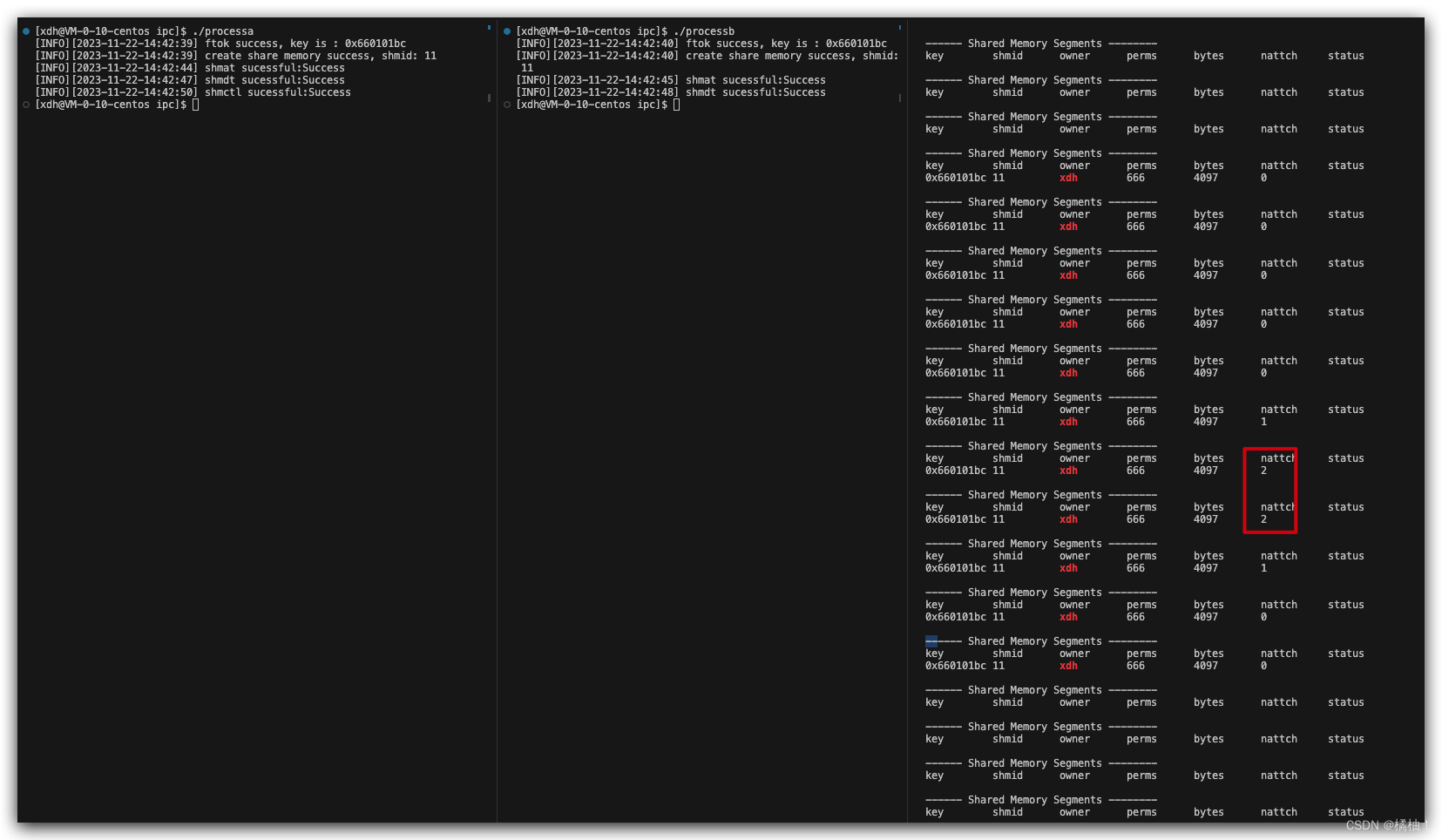
我们也成功看到了挂接数变成了2,上面讲解的一切都是让两个不同的进程之间看到同一份资源,还没有开始通信
2.2如何通信
我们通过上面一系列的操作终于实现我们再原理图讲的内容了,该说不说,确实太复杂的,但是这一系列的操作,让他的通信显得非常的简单,我们共享内存就是一块物理内存,映射到我们进程的地址空间上,我们程序通过这块地址空间上的地址就可以直接访问这块物理空间,此时他就很想malloc申请空间,然后去使用这块空间的方法很想,我们一起来看操作,让b写,a读
a:
while(true){cout<<"a say@"<<shmaddr<<endl;sleep(1);}
b:
while(true){cout<<"b enter@";fgets(shmaddr,4096,stdin);sleep(1);}
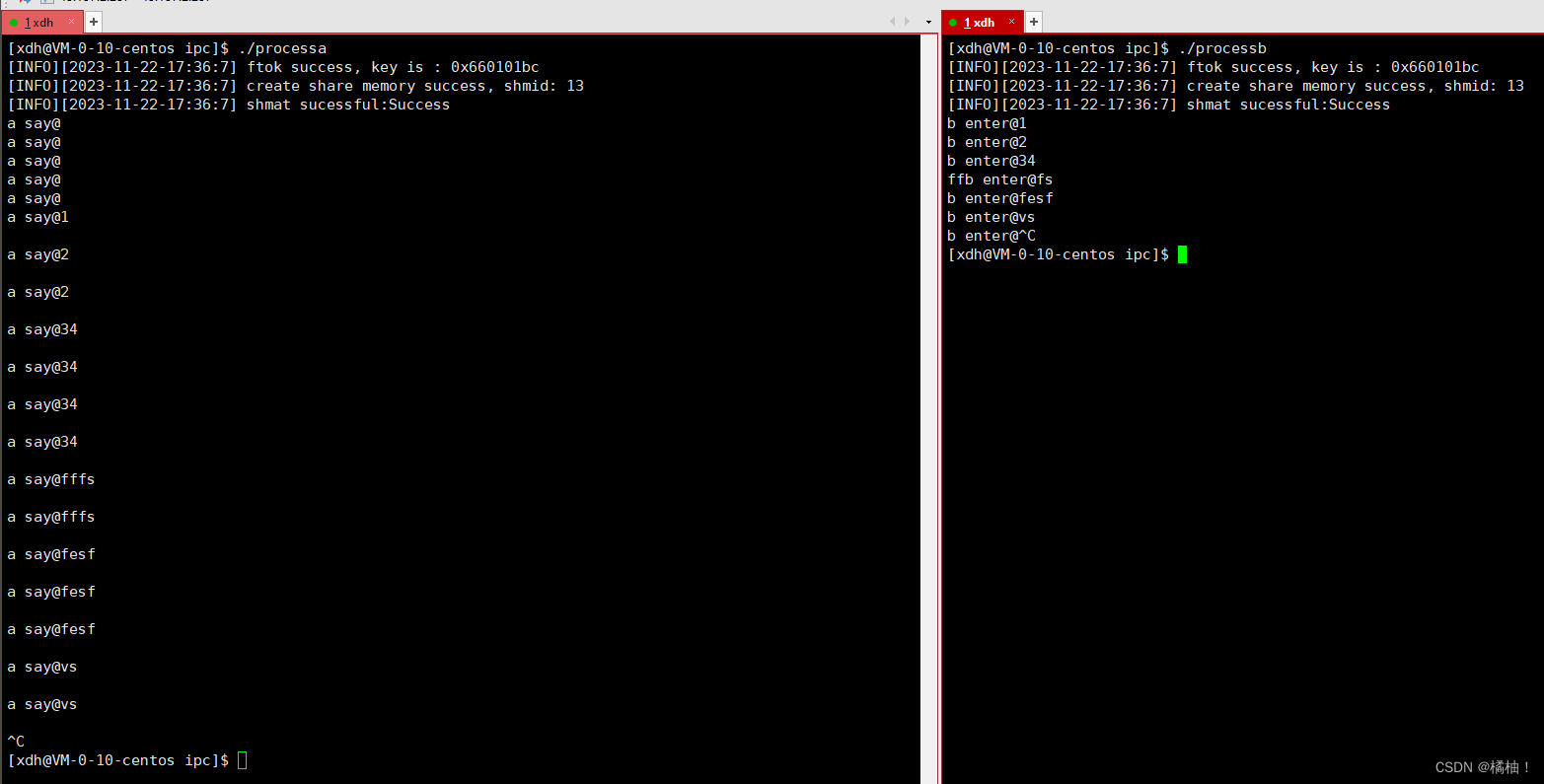
结论:
- 我们我们两个进程对这块空间的操作是你搞你的我搞我的,两者不受任何影响,所以说明共享内存间是没有同步互斥机制的
- 我们的共享内存是所有进程中通信速度最快,因为拷贝少
- 我们的共享内存的数据是用户自己去维护的,所以这些看到和管道有不同的地方,没有清空数据,这是需要用户自己去决定的。
但是我们确实实现了两个进程间通信了,有问题我们一会来解决。
三、扩展知识
3.1 看看维护共享内存的结构体属性
我们刚才的参数都是为了描述共享内存的,所以维护共享概念给内存的属性有哪些呢,刚才其实也大致看到了一些。
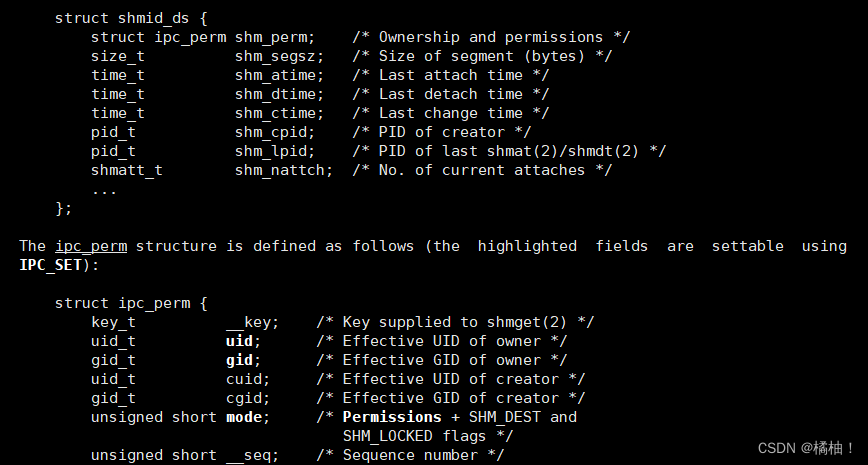
我们通过代码看看我们刚才提到一下属性:
再a进程把通信代码改成下面的
int count=0;struct shmid_ds shmds;while(true){sleep(1);if(count==0){shmctl(shmid, IPC_STAT, &shmds);cout << "shm size: " << shmds.shm_segsz << endl;cout << "shm nattch: " << shmds.shm_nattch << endl;printf("shm key: 0x%x\n", shmds.shm_perm.__key);cout << "shm mode: " << shmds.shm_perm.mode << endl;}count++;}

3.2 使用管道来实现同步互斥机制
我们因为目前只学了System V的共享内存,我们想要解决这个问题,还可以使用信号量,但是这个我们不做重点介绍,等有机会我们在给大家讲解信号量是怎么解决共享内存的这个缺点,我们今天,就使用管道去解决这个问题吧,因为是不相关的进程,所以使用命名管道。
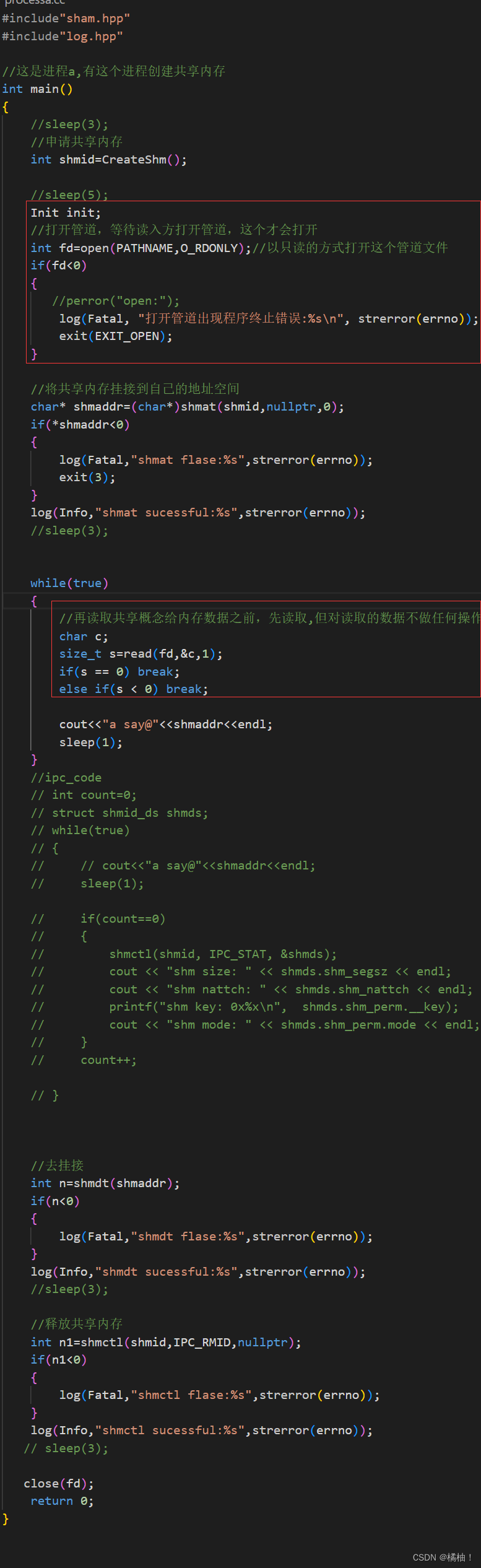
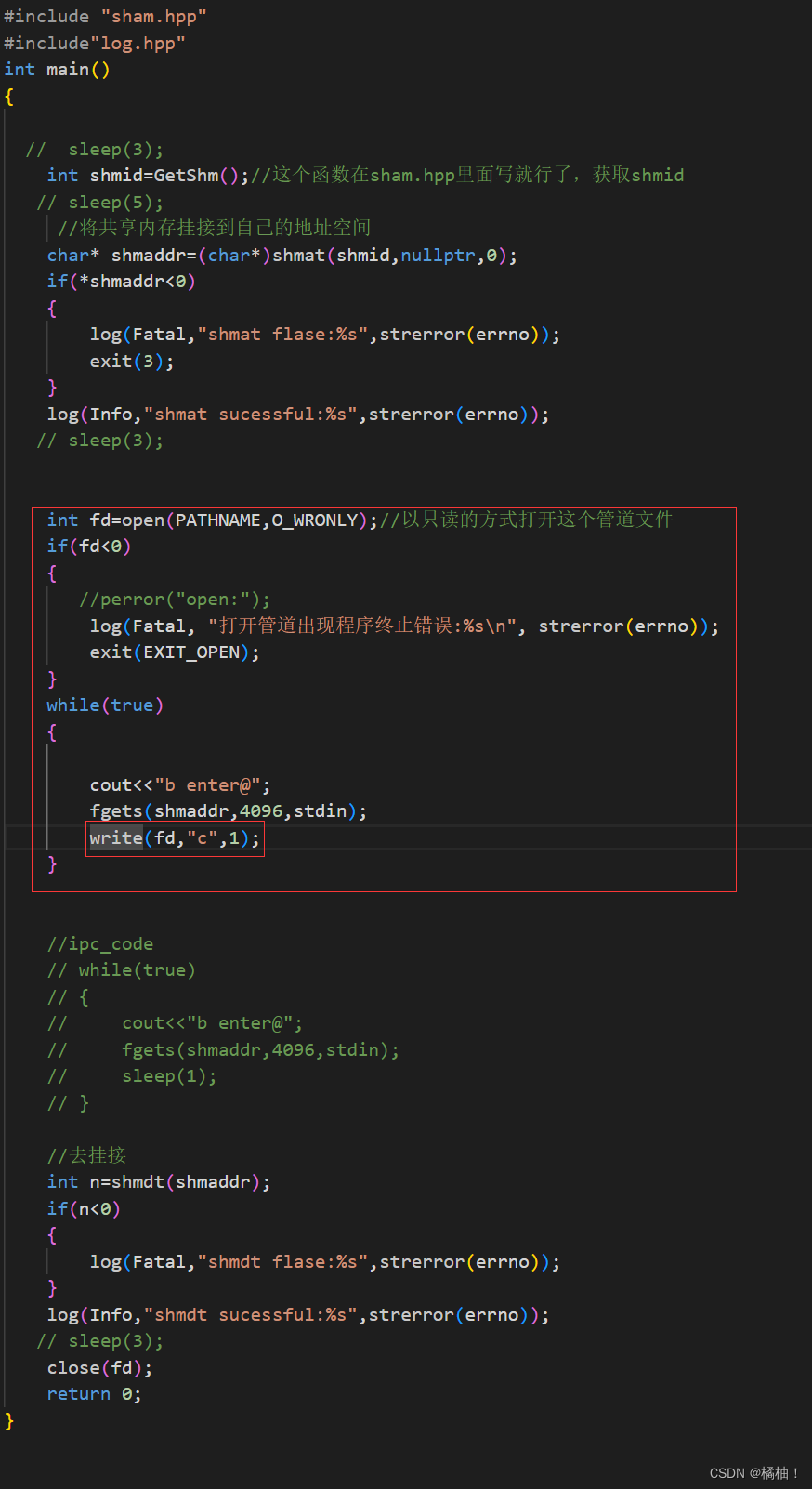
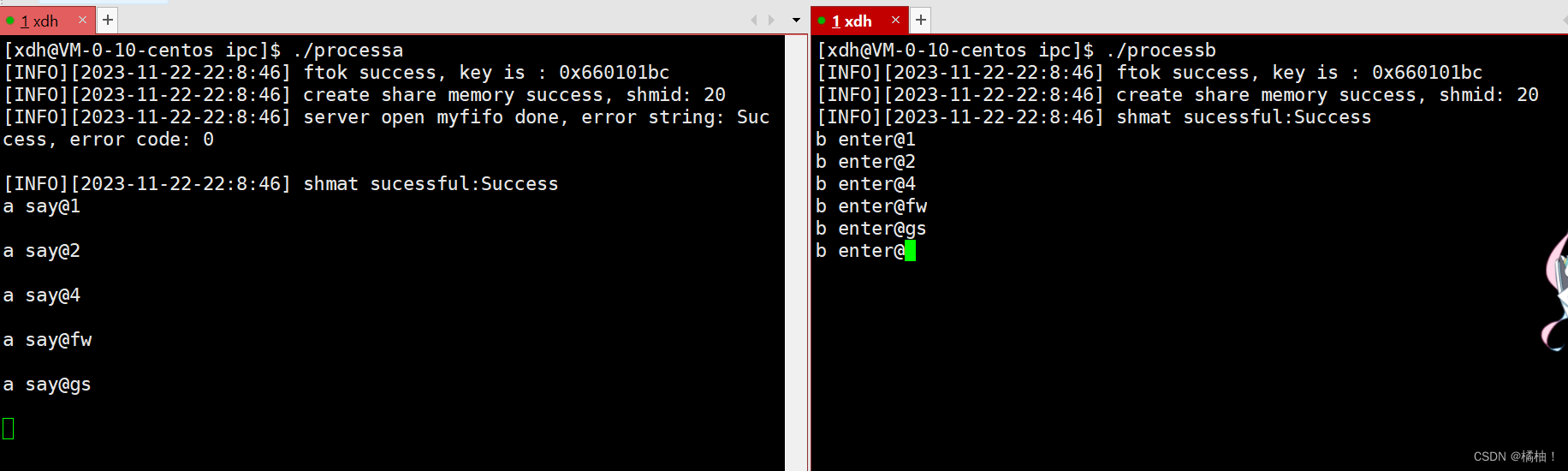
这个使用管道的方法其实和共享内存是一点关系没有,之根据他会阻塞就不会执行下面的代码,这样间接控制了。我们后面会简单介绍一下信号量是怎么解决这个问题的,但是知识带大家了解一下。
四、总结
今天我们学习了共享内存,学习成本和前面两个差不多,前面是原理的铺垫大家不容易理解,但是使用简单,二共享内存有了前面的原理铺垫,理解起来不难,但是后面的使用接口对大家来说可能是一个难度,大家下去好好把四大接口函数理解一下,这对博主下一篇讲解消息队列以及信号量有很大帮助,希望大家下来可以去自己实现博主这篇博客上面的内容,我们下篇再见
这篇关于【Linux】-进程间通信-共享内存(SystemV),详解接口函数以及原理(使用管道处理同步互斥机制)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






