本文主要是介绍一个很棒的数据包分流方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前段时间看流量分类方向的论文,看了许多中科大王伟老师的论文。受益匪浅,尝试着去学习借鉴。
因为流量分类的基本单元一般就是单个包,整条流或者双向流。通常使用双向流Bi-Flow作为基本单元,而通过网卡接口抓取的pcap文件或者pcapng文件一般都有很多个session组成。所以分流一般都是预处理过程的第一步。
1.获取流量数据集
首先使用了开源数据集ISCX VPN and NO-VPN。
ISCX开源数据集集合
2.pcapng转pcap
解压得到完整的pcap文件之后,首先要把其中的pcapng文件转化为pcap文件,可以通过脚本,或者直接用转化工具。包含的行为类型可以划分为以下几种:
聊天,邮件,文件传输,P2P,流媒体,语音电话共六种类型。
3.ps脚本批量处理
通过powershell脚本批量拆分pcap文件,得到每个session对应的单一文件。
脚本
 实现pcap拆分的ps脚本是1_Pcap2Session.ps1。
实现pcap拆分的ps脚本是1_Pcap2Session.ps1。

即对1_Pcap中的pcap文件,调用开源工具splitcap根据TCP和UDP将其拆分为多个文件,每个session对应一个文件。splitcap在同一级目录的0_Tool文件夹中。除此之外如果在命令行后面加入-y L7代表仅提取了应用层数据。
4.常见问题
如果在windows powershell中执行ps文件出错,输入Set-ExecutionPolicy Unrestricted来改变执行权限即可。如果出现找不到文件,出现no such directory,说明文件路径有误,建议绝对路径。

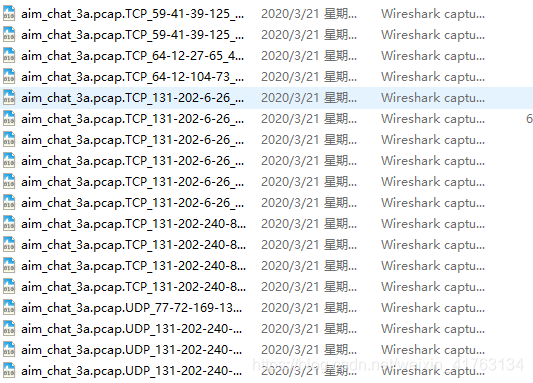
输出的结果为每个以原pcap文件名-ALL/L7命名的文件夹中都有许多的pcap文件。
5.后续
这里的pcap文件对应着各自的五元组信息。得到这部分文件之后,还需要进行接下来的处理工作,因为并不是所有的会话文件都适合作为训练数据。但是分流任务的完成表示着预处理的第一步算是完成了。接下来要通过这些较为原始的文件,根据自己的需要来处理为训练输入。通过AllLayer得到的数据可以选择剔除某些部分的原始字节信息,操作更加灵活。对于后面的ProcessSession以及session2png等脚本就不介绍了,ProcessSession就涉及了王伟老师论文的实验思想,其中包括截断784个字节,padding,然后784->28*28->png,还有数据集划分等操作。
个人接下来的数据预处理更倾向于特征映射,不是原始字节转img。
这篇关于一个很棒的数据包分流方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




