本文主要是介绍理解长短时记忆网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
发表于2015年8月27日
循环神经网络
人类并不是每秒钟都重启他们的思维. 就像阅读这篇文章时, 你对每个字的理解都基于对前面一系列字的理解.你并不是把已知的信息都抛弃然后从头开始思考. 人类的思维是具有连续性的.
传统的神经网络没有连续性, 这看起来是一个重大的缺陷. 例如, 你想对电影发生的事件类型进行分类. 传统神经网络无法通过电影中先前事件的经验去推理后面事件的类型。
循环神经网络就是为解决这个问题而产生的.循环神经网络是由网络循环组成, 允许信息在网络里持续传递.
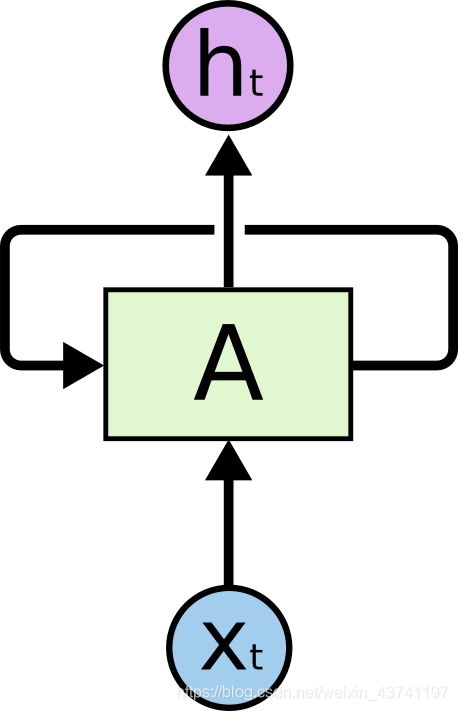
循环神经网络
在上图中, 一组神经网络A有输入Xt和输出ht. 循环过程可以将信息传递到下一步计算中去.
这些循环使神经网络看起来有点神秘。 但是,如果您再想一想,就会发现它们与普通的神经网络并没有什么不同。 循环神经网络可以包括了同一网络的多个副本,每个副本都将消息传递给后继者。 想一想如果展开循环会发生什么:
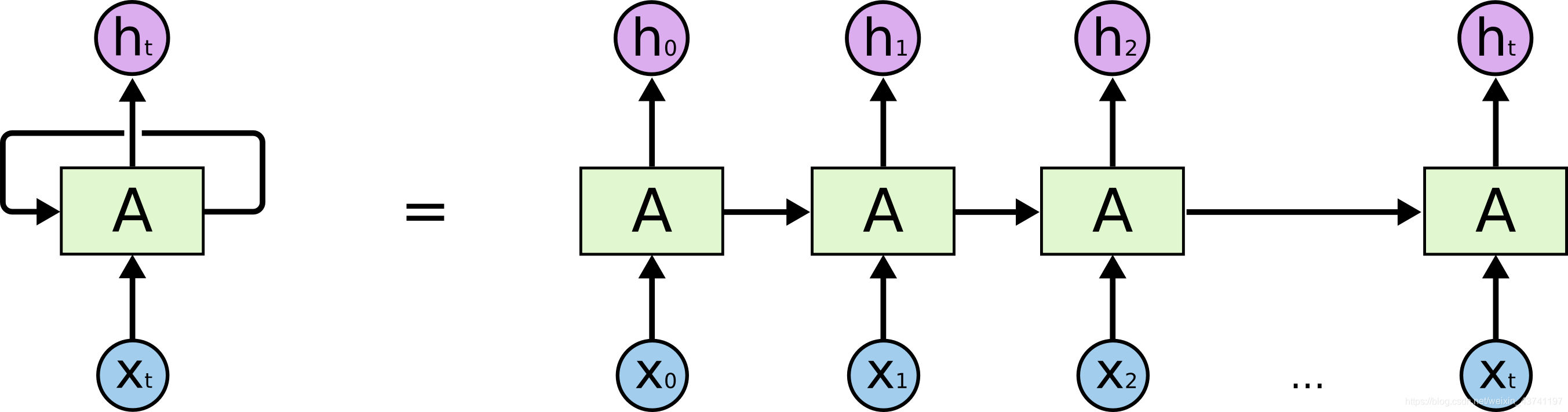
展开的循环神经网络
上图中的链条形状揭示了循环神经网络与序列和列表是密切相关的. 循环神经网络的架构本质上就与序列和列表数据而生的.
循环神经网络的确落地应用了. 近年来, 循环神经网络在解决很多问题上都取得了显著的成功, 例如语音识别, 语言建模, 翻译, 图像描述等, 应用的场景还在不断增加. 这里就不讨论循环神经网络种种令人惊讶的特性了, 大家可以到 Andrej Karpathy的博客"The Unreasonable Effectiveness of Recurrent Neural Networks"去看. 但循环神经网络真的很棒.
LSTM是取得这一系列成功的关键, 它是一种非常特殊的循环神经网络, , 在许多任务上都超过标准版的循环神经网络. 几乎所有循环神经网络取得成果都是应用LSTM. 这篇文章正是要探索LSTM的原理.
长时依赖问题
RNN吸引人的地方之一是它能够将之前的信息与当前的任务联系起来, 例如, 之前的视频帧可以用作理解当前视频帧的内容. 如果RNN可以做到这一点, 它将是非常有用的. 但它可以吗? 这需要看情况.
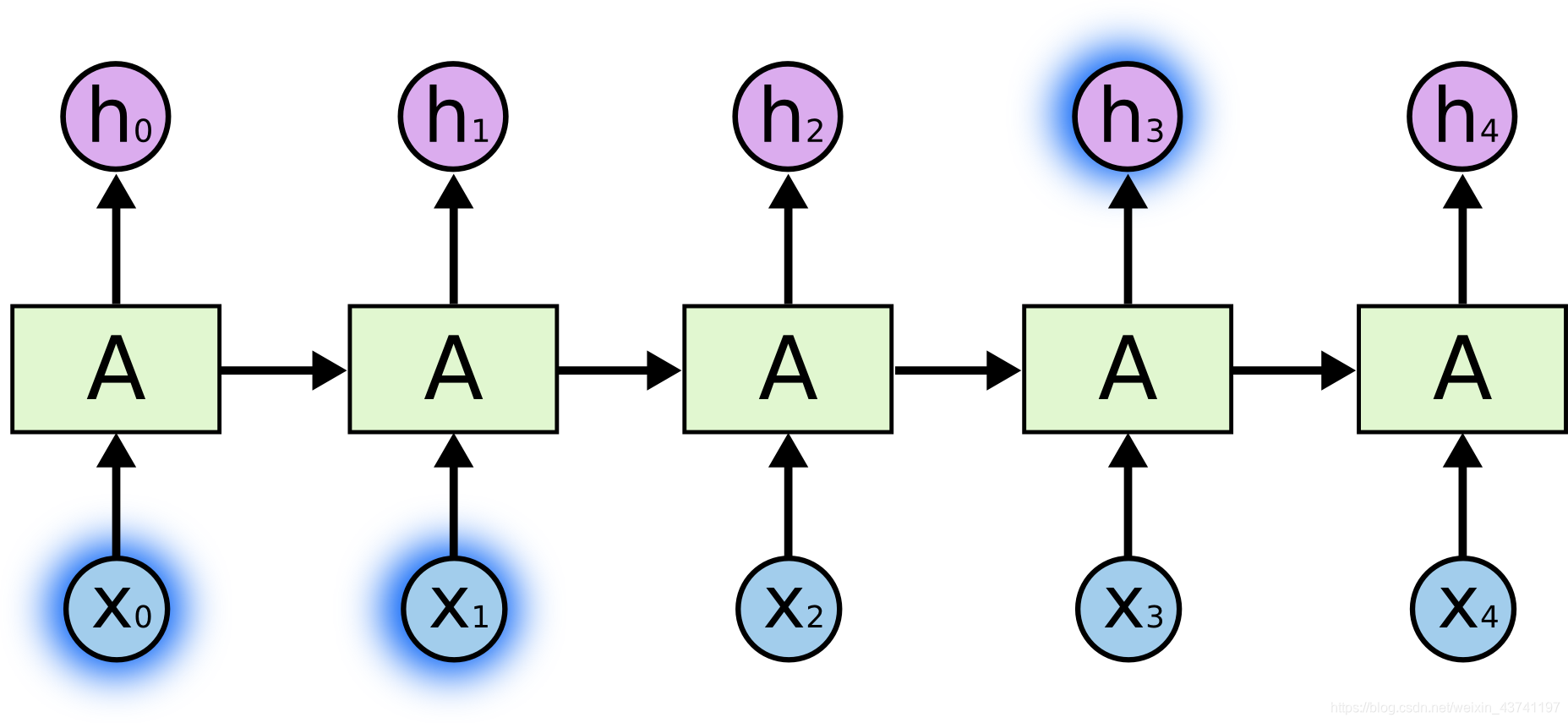
有时, 我们需要使用最近的信息来执行当前的任务. 例如, 一个语言模型试图去通过之前的字词去预测下一个字. 如果我们尝试去预测 “the clouds are in the sky,” 中的最后一个字, 我们不需要任何进一步的上下文—非常明显下一个字就是"sky". 在这种情况, 相关信息和需要预测位置的差距很小, RNN是可以学会使用过去信息的.如下图中, X0, X1 和h3.
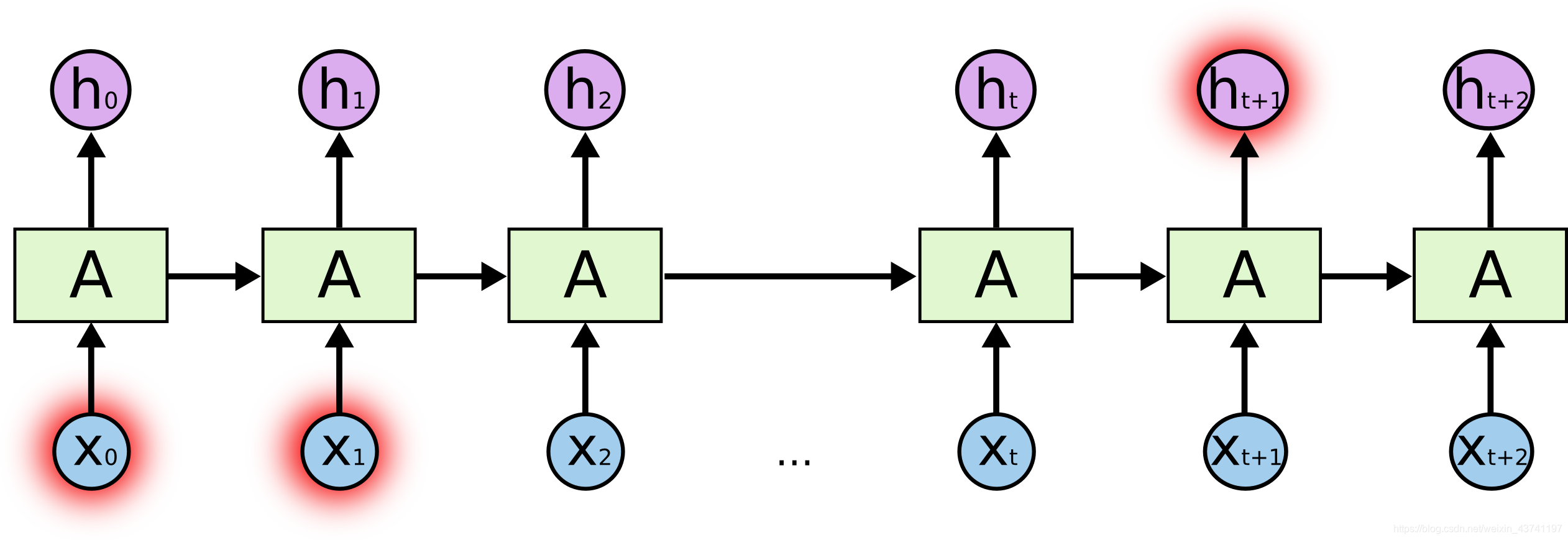
但是还有些场景中我们需要更多的上下文. 考虑尝试预测下面这段文字的最后一个字 “I grew up in France… I speak fluent French.” 最近的信息提示下一个词很可能是一种语言的名字, 但如果我们想要缩小语言的可选范围, 我们需要从最后面追溯到"France"这个上下文. 相关信息与要预测位置的距离可能非常大. 如下图中, X0, X1和ht+1.
不幸的是, 随着差距的增大, RNN变得不能学习到相关的信息.
In theory, RNNs are absolutely capable of handling such “long-term dependencies.” A human could carefully pick parameters for them to solve toy problems of this form. Sadly, in practice, RNNs don’t seem to be able to learn them. The problem was explored in depth by Hochreiter (1991) [German] and Bengio, et al. (1994), who found some pretty fundamental reasons why it might be difficult.
Thankfully, LSTMs don’t have this problem!
从理论上讲,RNN绝对有能力处理这种“长时依赖关系”。 人类可以为RNN仔细选择参数以解决这种初级问题。 可悲的是,在实践中,RNN似乎无法学习它们。 Hochreiter(1991)[German]和Bengio等人对此问题进行了深入探讨。 (1994年),他们发现了为什么RNN很难实现的根本原因。
幸运的是,LSTM没有这个问题!
原文地址:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
这篇关于理解长短时记忆网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







