本文主要是介绍基于NioEventLoop线程夯住问题了解线程池工作流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题现象
近期我们使用NioEventLoop出现一个奇怪的现象,在消息密集的情况下,服务端处理会断断续续的,一会性能看着又没问题,一会又会阻塞很久再处理消息。经过不断的摸索排查发现是线程池使用不当导致的,我们不妨来看看这个问题的代码。
代码演示
在演示代码之前,我们不妨先来了解一下这个需求,如下图,客户端和服务端建立连接之后,会向该通道不断发送消息。然后服务端收到消息,会将消息提交到业务线程池中异步处理。
先来看看客户端的代码,就是一套标准的模板代码,设置好对应参数以及业务处理器之后,直接向服务端的9999端口发起连接。
public class Client9 {static final int MSG_SIZE = 256;public void connect() throws Exception {EventLoopGroup group = new NioEventLoopGroup(8);Bootstrap b = new Bootstrap();b.group(group).channel(NioSocketChannel.class).option(ChannelOption.TCP_NODELAY, true).handler(new ChannelInitializer<SocketChannel>() {@Overridepublic void initChannel(SocketChannel ch) throws Exception {//业务处理器ch.pipeline().addLast(new ClientHandler());}});ChannelFuture f = b.connect("127.0.0.1", 9999).sync();f.channel().closeFuture().addListener(new ChannelFutureListener() {@Overridepublic void operationComplete(ChannelFuture future) throws Exception {group.shutdownGracefully();}});}public static void main(String[] args) throws Exception {new Client9().connect();}
}
再来看看客户端的业务处理器,代码逻辑也很简单,和服务端建立了连接之后,创建一个线程,无限循环,每隔1毫秒发送消息给服务端。
public class ClientHandler extends ChannelInboundHandlerAdapter {@Overridepublic void channelActive(ChannelHandlerContext ctx) {new Thread(() -> {//无限循环,每隔一毫秒发送一次消息while (true) {ByteBuf firstMessage = Unpooled.buffer(Client9.MSG_SIZE);for (int i = 0; i < firstMessage.capacity(); i++) {firstMessage.writeByte((byte) i);}ctx.writeAndFlush(firstMessage);try {TimeUnit.MILLISECONDS.sleep(1);} catch (Exception e) {e.printStackTrace();}}}).start();}@Overridepublic void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {cause.printStackTrace();ctx.close();}
}
了解了客户端代码之后,我们再来看看服务端的代码,首先自然是启动类,就是典型的一套启动类模板,配置声明主从reactor,设置参数,以及配置业务处理器。最终阻塞监听等待连接。
public class Server9 {public static void main(String[] args) throws Exception {//声明主从reactorEventLoopGroup bossGroup = new NioEventLoopGroup(1);EventLoopGroup workerGroup = new NioEventLoopGroup();ServerBootstrap b = new ServerBootstrap();b.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).option(ChannelOption.SO_BACKLOG, 100).childHandler(new ChannelInitializer<SocketChannel>() {@Overridepublic void initChannel(SocketChannel ch) throws Exception {//追加业务处理器ChannelPipeline p = ch.pipeline();p.addLast(new ServerHandler());}});//监听9999端口ChannelFuture f = b.bind(9999).sync();f.channel().closeFuture().addListener((ChannelFutureListener) future -> {bossGroup.shutdownGracefully();workerGroup.shutdownGracefully();});}
}
而业务处理器的代码如下,可以看到笔者在服务端收到消息之后将消息提交到业务线程池中,该线程池我们假设已经达到服务器可以达到的最大值了,而拒绝策略我们也配置为当任务处理不过来时,用当前调用线程池的线程处理当前任务。
注意笔者下面的if判断有一个逻辑判断Thread.currentThread() == ctx.channel().eventLoop(),这个就是笔者为了重现该问题而特地加的一个判断,读者现在留意到即可,我们会在后文详述原因。
public class ServerHandler extends ChannelInboundHandlerAdapter {static AtomicInteger sum = new AtomicInteger(0);static ExecutorService executorService = new ThreadPoolExecutor(1, 3, 30, TimeUnit.SECONDS,new ArrayBlockingQueue<Runnable>(1000), new ThreadPoolExecutor.CallerRunsPolicy());public void channelRead(ChannelHandlerContext ctx, Object msg) {//通过原子类记录收到的第几个消息SimpleDateFormat simpleDateFormat=new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");String date = simpleDateFormat.format(new Date());System.out.println("--> Server receive client message : " + sum.incrementAndGet()+"time: "+date);//将消息提交到业务线程池中处理executorService.execute(() -> {ByteBuf req = (ByteBuf) msg;//其它业务逻辑处理,访问数据库if (sum.get() % 100 == 0 || (Thread.currentThread() == ctx.channel().eventLoop()))try {//访问数据库,模拟偶现的数据库慢,同步阻塞15秒TimeUnit.SECONDS.sleep(15);} catch (Exception e) {e.printStackTrace();}//转发消息,此处代码省略,转发成功之后返回响应给终端ctx.writeAndFlush(req);});}@Overridepublic void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {cause.printStackTrace();ctx.close();}
}
自此我们的代码都编写完成,我们不妨将服务端和客户端代码都启动。通过控制台可以发现,1毫秒发送的消息,会时不时的卡15s才能继续处理消息。

排查过程
这类问题我们用jvisualvm看看GC情况是否正常,看看是不是频繁的Full GC导致整个进程处于STW状态导致消息任务阻塞。
监控结果如下,很明显GC没有问题,我们只能看看CPU使用情况。

很明显的CPU使用情况也是正常,没有什么奇奇怪怪的任务导致使用率飙升。

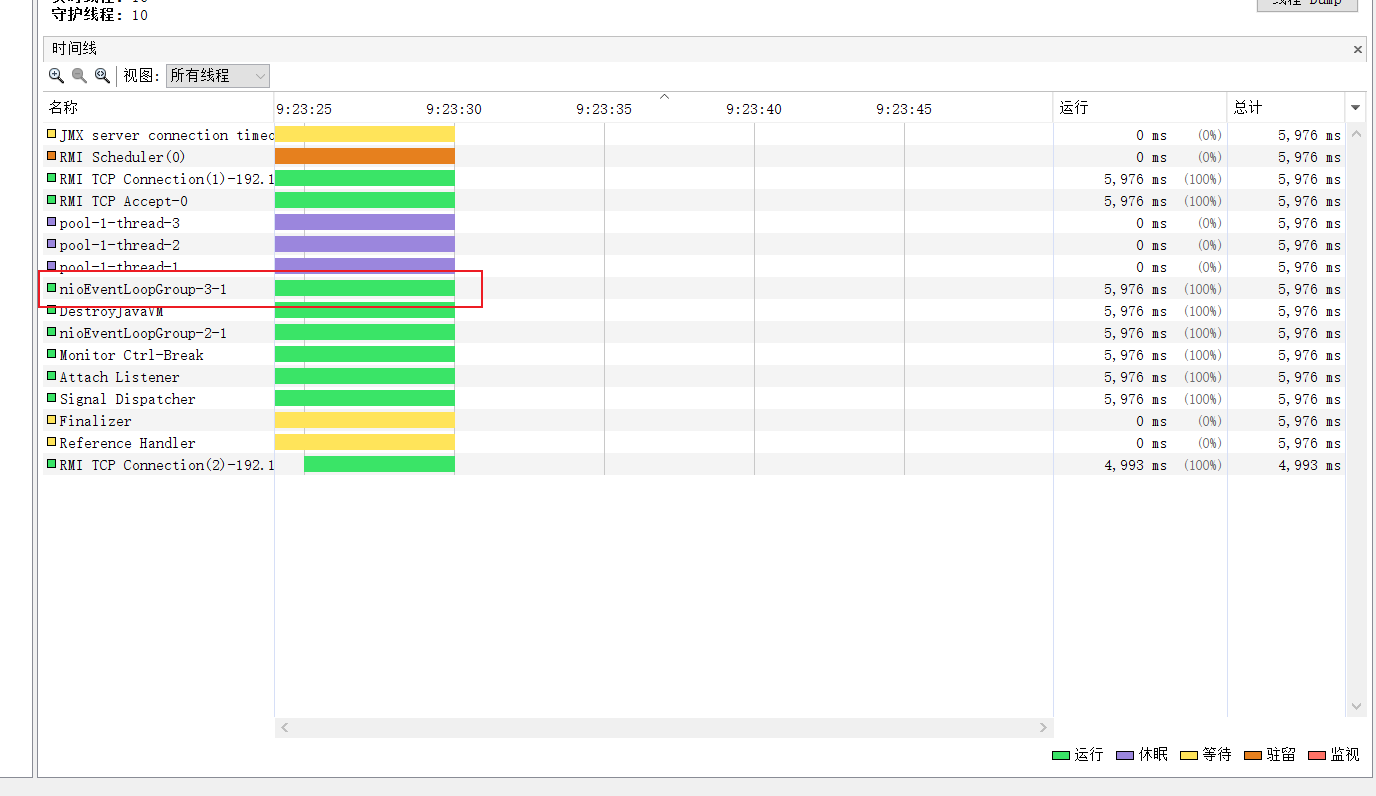
所以我们只能看看线程使用情况了,果然,我们发现NioEventLoop居然长时间的处于休眠状态。

所以我们用jps定位Java进程id后键入jstack查看线程使用情况
jstack -l 17892
自此我们终于找到了线程长期休眠的原因,从下面的堆栈我们可以看出,正是任务量巨大,导致业务线程池无法及时处理消息,最终业务线程池走到了拒绝策略,这就使得业务线程池一直走到CallerRunsPolicy,也就是说业务线程池忙不过来的时候会将任务交由NioEventLoop执行。而一个连接只会有一个NioEventLoop的线程执行,使得原本非常忙碌的NioEventLoop还得分神处理一下我们业务线程池的任务。

为了验证这一点,我们不妨在业务线程池中打印线程名:
//将消息提交到业务线程池中处理executorService.execute(() -> {System.out.println(" executorService execute thread name: "+Thread.currentThread().getName());ByteBuf req = (ByteBuf) msg;//其它业务逻辑处理,访问数据库if (sum.get() % 100 == 0 || (Thread.currentThread() == ctx.channel().eventLoop()))try {//访问数据库,模拟偶现的数据库慢,同步阻塞15秒TimeUnit.SECONDS.sleep(15);} catch (Exception e) {e.printStackTrace();}//转发消息,此处代码省略,转发成功之后返回响应给终端ctx.writeAndFlush(req);});
最终我们可以看到,线程池中的任务都被nioEventLoopGroup这个线程执行,所以这也是笔者为什么在模拟问题时在if中增加 (Thread.currentThread() == ctx.channel().eventLoop())的原因,就是为了模仿那些耗时的业务被nioEventLoopGroup的线程执行的情况,例如:一个耗时需要15s的任务刚刚好因为拒绝策略被nioEventLoopGroup执行,那么Netty服务端的消息处理自然就会阻塞,出现本文所说的问题。

解决方案
从上文的分析中我们可以得出下面这样一个结果,所以解决该问题的方式又两种:
- 调整业务线程池大小。
- 调整拒绝策略。

由于我们当前的线程池大小已经假设为最大值了,所以如果我们能够保证消息幂等,我们建议将拒绝策略改为直接丢弃。
static ExecutorService executorService = new ThreadPoolExecutor(1, 3, 30, TimeUnit.SECONDS,new ArrayBlockingQueue<Runnable>(1000), new ThreadPoolExecutor.DiscardOldestPolicy());
自此之后我们再查看控制台输出和NioEventLoop线程状态,发现运行都没有阻塞,那些实在无法处理的消息都被丢弃了。
反思总结
自此我们对于本次的事件总结出以下几点要求和建议:
- 耗时操作不要用NioEventLoop,尤其是本次这种高并发且拒绝策略配置为用执行线程接收忙碌任务的方式。
- 服务端收不到消息时,建议从CPU、GC、线程等角度分析问题。
- 建议使用两个NioEventLoop构成主从Reactor模式。
参考
Java性能调优 6步实现项目性能升级
这篇关于基于NioEventLoop线程夯住问题了解线程池工作流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








