本文主要是介绍手把手教你C语言‘数据的存储‘[doge],希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
@[toc](目录)
想来学完大多语法后,大家都对整型,浮点型,字符型都有了大概的认识,简而言之,大概知道是什么.
对其相关的了解想要更进一步,那就必须要知道这些类型在内存中是如何存储的了.
彳亍,那我们接下来就浅谈这几种类型的存储.
目录
数据类型
整型,浮点型的存储
大小端讲解
例题巩固
数据类型
想想到现在我们学了什么? 好像啥也没学
那从最基本的类型说起,下面是我们学过的几种类型
short 2
int 4
long 4
long long 8float 4
double 8char 1他们的类型决定了我们看待内存的视角,也就是我们怎么看它,像一个标签一样
而要讨论他们在内存中的存在方式,肯定要讨论它的大小了
大小(所占字节数)决定了他们的精度,也决定了取值的范围

自然类型的意义就出来了:
1.类型决定了看待内存的角度
说人话:计算机怎么看它的,我们又是怎么看它的
2.类型决定了他们的使用范围
简单点:一个桶子只能装1L的水,你装1.1L就会溢出
下面我们就具体分一下类
Q:啥?上面不是分了?
A:那只是概述
具体分类如下
整型:char: (别急后面解释为啥放这)unsigned char
signed charshort:
unsigned short
signed shortint:
unsigned int
signed intlong:
unsigned long
signed longlong long :
unsigned long long
signed long longchar字符型放在‘整型家族’的原因是char存的不是字符,而是字符的ASCII值,是个数字
浮点型:float
double构造类型:数组,struct,enum,union (注意是数组和结构体,后面的枚举和联合知道有它就行了)指针:
char*
int*
float*
double*
void* 等等等等
指针类型太多在这不一一列举了空类型:
void
函数返回值,函数参数,指针类一般都可以见到它
现在你应该明白数据的分类了.
那么归好类,就得讲讲这个东西是怎么存的了
整型和浮点型的数据存储方式不同
所以小白时期明明感觉没错,但是打印的结果很奇怪,有一部分就是这个问题没有解决
先说整型:
整型在内存里存的是补码
我们进行的加减乘除全是操作补码
计算机里表示一个数有三种方法--原码,反码,补码
原码--符号位+二进制序列
第一位是符号位 0代表正,1代表负
例:
5的二进制101,如果放进int里面,int是32位
那么就写成
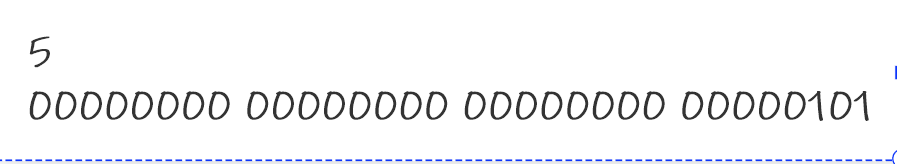
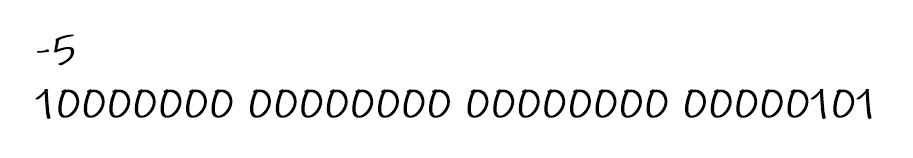
正数的原反补三码相同,写出原码就等价于写出补码
负数复杂一点
反码==原码符号位不动,其余位按位取反
解释:第一位不动,其余位0变成1,1变成0
补码==反码+1
例:

这就是整型,long,longlong之类的都可以类推
值得一提的是char类型,一个字节,八位,所以取值范围:-128-127
下面推导char的类型(有符号的char)

1000 0001是几?
由计算机算出来是127,加上符号位的1表示负数,所以是-127

那最后11111111是几?
显然是-1,可以自己动笔推算一下
由以上就可以知道char类型的取值是一个循环
假若我们从0开始
那就是0 -> 127 -> (-128) -> (-1) -> 0
这是有符号的char的范围:-128-127
注:127+1==-128
127是百尺竿头,再进一步就是-128
同理也可知道无符号的char: 0 - 255
到这里,我们就知道了整型在内存种的存储方式,存的是补码,我们也要知道怎么表示他们
同时也推导了char的取值范围,整型到这就告一段落了
---------------------------
整型,浮点型的存储
下面我们谈谈浮点型:
来一道典型的例题看看:
int main()
{int n = 9;float *pFloat = (float *)&n;printf("n的值为:%d\n",n);printf("*pFloat的值为:%f\n",*pFloat);*pFloat = 9.0;printf("num的值为:%d\n",n);printf("*pFloat的值为:%f\n",*pFloat);return 0; }猜猜这四个打印的值是多少?
想好了没?
公布答案:

小朋友是不是有很多的问号?

哈哈哈哈哈哈,说回正题
具体介绍下浮点型咋存的,再来解释打印的结果
float
记住这么几个数字 :1-8-23
double
记住这么几个数字: 1-11-52
这几个数字意义是什么:
从前往后:符号位 -指数- 有效数字(S-E-M)
E是一个无符号数,后面解释为什么
例:


S:0表示正数,1表示负数(这点和整型对应上了)
E有八位,第八位是符号位吗?前面说过转换过程+127所以一定是正数,
所以E的第八位不是符号位,这是一个无符号数
上面是E不全为0或者不全为1
那如果E(指数)是全0或者全1呢,属于特殊情况,分类讨论
全0:说明这个数很小,想想+127都是0了,那读取的时候应用规则:E取1-127的值或者1-1023的值
全1:这个数的绝对值很大,趋于无穷(指数不能决定正负)
到此我们知道了浮点数的存储方式
十进制的浮点数->写成二进制->转换成指数形式->根据规则确定存入的S-E-M的值,再按规则取出来
这就是浮点数的存储
那么我们来解释一下最开始的例题:
不用往上翻了

从内存入手:
先看这四句话:
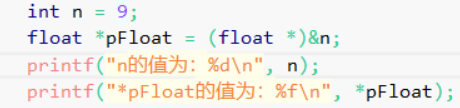
n以%d(整型的方式读取)打印肯定是9,没问题
float*和int*都操作四个字节,都可以拿到32位,不存在截取的问题
所以%f就是以浮点数的读取方式读取整型,由补码入手:

E全是0,无限接近0的一个数,float默认打印小数点后6位,
自然结果:

那再看后面两行:

第一行赋值为9.0,float型指针,以浮点数的方式存进去
那就有:

以%d的形式打印,也就是以整型的办法去读取:
正数,所以直接补码==原码

读取的十进制数也就是计算器所呈现的1091567616
以%f,也就是浮点型的方式去读取它,自然是9.000000
我们再比对一下结果:

ohhhhhhhh,一样的对吧.
------------------
到这里我们就知道了浮点数的存储方式,进度条过半
-----------------
大小端讲解
接下来就是大小端的问题了
先给定义:


int check(int a)
{char* tmp = (char*)&a;if (*tmp & 1 == 1){return 1;}return 0;
}int main()
{int a = 1;if (check(a)){printf("小端\n");}else{printf("大端\n");}

例题巩固
//输出什么?
#include <stdio.h>
int main()
{char a= -1;signed char b=-1;unsigned char c=-1;printf("a=%d,b=%d,c=%d",a,b,c);return 0; }因为是第一题,讲详细一点
某些编译器默认char是有符号的signed char,有些又当作unsigned char处理。VS默认signed char
char a==signed char a (VS编译器下)
有符号的char:



2.
2.
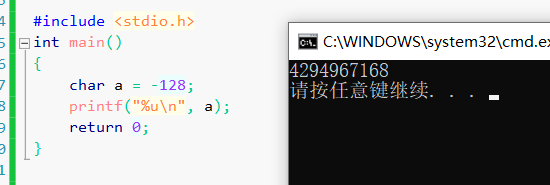
#include <stdio.h>
int main()
{char a = -128;printf("%u\n",a);return 0; }-128在这个范围内,但是注意是无符号数打印(%d打印那就是-128),所以还是从补码入手



int i= -20;
unsigned int j = 10;
printf("%d\n", i+j);
//按照补码的形式进行运算,最后格式化成为有符号整数


------------------终于写完了!-------------

能看到这真的强:

----------------------------
感谢阅读,如果有帮助别忘了点赞,这对我帮助很大,下次再见!
这篇关于手把手教你C语言‘数据的存储‘[doge]的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





