本文主要是介绍【脚踢数据结构】链表(2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- (꒪ꇴ꒪ ),Hello我是祐言QAQ
- 我的博客主页:C/C++语言,Linux基础,ARM开发板,软件配置等领域博主🌍
- 快上🚘,一起学习,让我们成为一个强大的攻城狮!
- 送给自己和读者的一句鸡汤🤔:集中起来的意志可以击穿顽石!
- 作者水平很有限,如果发现错误,可在评论区指正,感谢🙏
【脚踢数据结构】链表(1)_祐言QAQ的博客-CSDN博客
接上文:
2.单项循环链表
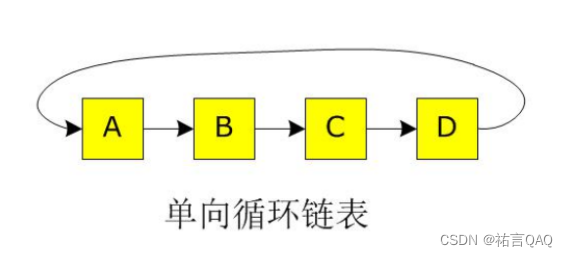
单向循环链表和普通单向链表的操作逻辑几乎一样,唯一就是初始化和结尾判断有区别(单向循环链表里面每一个节点的next都要有指向,最后一个节点的next指向head节点)。
(1)初始化
//初始化(区别于普通单向链表)
singly_list init(void)
{singly_list head = malloc(sizeof(listnode));if (head != NULL){head->next = head;}return head;
}(2)尾插法
//尾插法插入新节点(有区别)
void insert_tail(singly_list head, singly_list new)
{if (head == NULL || new == NULL){return;}//(1)找到原来链表中最后一个节点singly_list p = head;//定义一个临时指针变量p,用来遍历链表,找到最后节点while(p->next != head){p = p->next;//一个一个往后找}//(2)将原来链表中最后一个节点的后继指针next设置为new(新节点地址)p->next = new;//(3)将新的尾部节点 new 的next指向头节点headnew->next = head;
}(3)其他算法和单向链表几乎一样
只需要将原来判断结尾的 p->next == NULL 改为 p->next == head 和将p->next != NULL换成p->next != head。
3.单项循环链表小练习
据说犹太历史学家 Josephus有过以下的故事:在罗马人占领乔塔帕特后,犹太人与Josephus及他的朋友躲到一个洞中,族人决定宁愿死也不要被敌人找到,于是决定了一个自杀方式,所有人排成一个圆圈,由第1个人 开始报数,每报数到第3人该人就必须自杀,然后再由下一个重新报数,直到所有人都自杀身亡为止。
然而Josephus 和他的朋友并不想死,Josephus要他的朋友先假装遵从,他将朋友与自己安排在两个特殊的位置,于是逃过了这场死亡游戏。现在假设有n个人形成一个单向循环链表,求最后剩余的两个节点。
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>//数据域
typedef int Database;//链表的节点定义
typedef struct Node
{Database data; //数据域struct Node *next; //指针域
}node;//初始化链表
node *init_list()
{node *head = malloc(sizeof(node));if (head!=NULL){head->data = 1;head->next = head;}return head;
}//创建节点
node *create_node(Database data)
{node *new = malloc(sizeof(node));if (new!=NULL){new->data = data;new->next = NULL;}return new;
}//尾插
void insert_tail(node *head, node *new)
{node *p = head;while(p->next!=head){p = p->next;}p->next = new;new->next = head;
}void delete_node(node *head)
{node *p = head;while(p->next->next!=p){node *dele = p->next->next;p->next->next = dele->next;free(dele);p = p->next->next;}printf("%d %d\n", p->data, p->next->data);
}void display(node *head)
{node *p = head;while(p->next!=head){printf("%d ", p->data);p = p->next;}printf("\n");
}int main(int argc, char const *argv[])
{node *head = init_list();int num;scanf("%d", &num);for (int i = 2; i <= num; ++i){insert_tail(head, create_node(i));}delete_node(head);return 0;
}运行结果:

不难推算出,当有十个人时,第4个和第10个人会幸存。

4.双向循环链表
双向循环链表是一种常见的链表数据结构,它在单向链表的基础上进行了扩展,允许链表中的节点以双向方式连接,并且链表的尾节点指向头节点,形成一个闭环,从而形成循环。

双向循环链表由节点构成,每个节点包含三个部分:
数据域:用于存储节点的数据;
前驱指针(prev):指向链表中的前一个节点,使得节点之间可以双向连接;
后继指针(next):指向链表中的后一个节点,同样用于双向连接。
双向循环链表的特点包括:
尾节点的后继指针指向头节点,头节点的前驱指针指向尾节点,形成循环;
每个节点都有一个前驱和一个后继,除了头节点的前驱指针指向尾节点,尾节点的后继指针指向头节点,其他节点之间通过prev和next指针连接;
可以从头节点或尾节点开始遍历整个链表,并且可以进行前驱和后继的操作。
双向循环链表相对于单向链表的优点在于:
可以双向遍历链表,更加方便地实现向前或向后遍历节点;
删除操作时,不需要特殊处理链表尾部的节点,因为尾节点的后继指针指向头节点,循环回到链表的开头。
使用双向循环链表的一些注意事项包括:
确保在插入和删除节点时正确地维护prev和next指针,避免出现链表断裂或死循环等问题;
注意在访问节点的前驱和后继指针时,先判断节点是否为头节点或尾节点,避免出现空指针引用的错误;
使用双向循环链表时,需要额外的内存来存储prev指针,所以在内存使用上可能会比单向链表略高。
(1)双向循环链表初始化
//初始化链表
node *init_double_list()
{node *head = malloc(sizeof(node));if (head == NULL){printf("malloc error\n");exit(0);}else{head->prev = head;head->next = head;}return head;
}(2)新建链表
//数据
typedef int DataType;//节点
typedef struct Node
{DataType data; //数据域struct Node *prev; //指针域:前驱指针struct Node *next; //指针域:后继指针
}node;//创建节点
node *create_double_node(DataType data)
{node *new = malloc(sizeof(node));if (new != NULL){new->data = data;new->prev = NULL;new->next = NULL;}return new;
}(3)尾插法
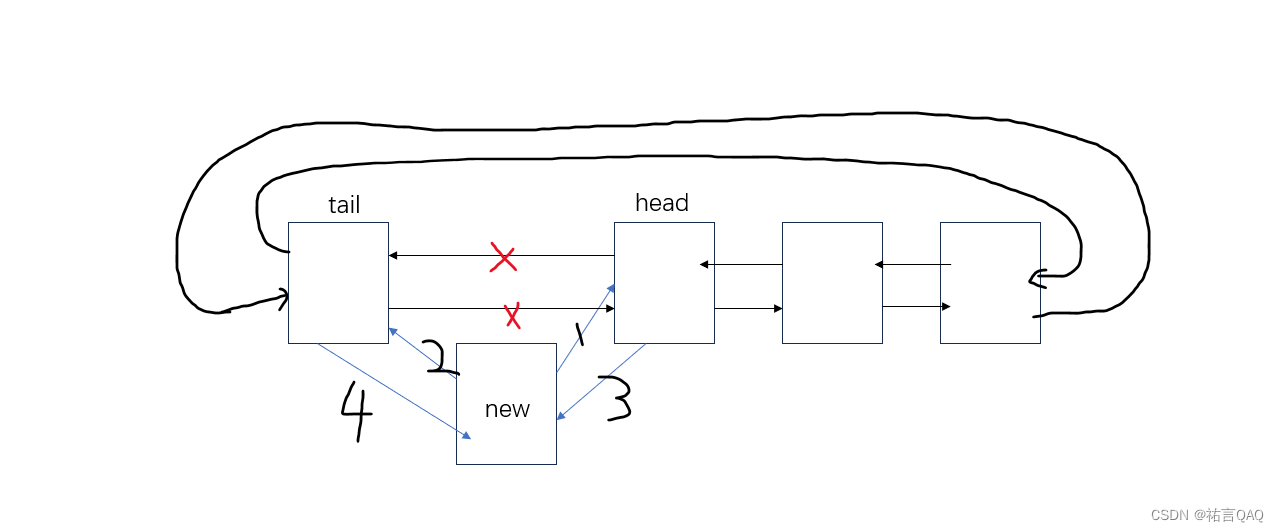
//尾插法,实际是向头节点前一个的节点后面插入,相当于头插
void insert_double_tail(node *head, node *new)
{//拿到头节点的前驱节点node *tail = head->prev;new->next = head; // 1new->prev = tail; // 2head->prev = new; // 3tail->next = new; // 4
}(4)头插法
头插法其实就是尾插法的变形,相当于tail是头(head),而把new放在tail(head)后。
//头插法
void insert_double_head(node *head, node *new)
{node *tmp = head->next;new->next = tmp;new->prev = head;tmp->prev = new;head->next = new;
}(5)遍历
双向链表的遍历有两种常见的方式:前驱遍历和后继遍历。
前驱遍历(正向遍历): 前驱遍历是从链表的头节点开始,沿着后继指针(next)向后遍历到链表的尾节点为止。这种遍历方式是最常见的,它按照链表中节点的顺序,从前向后逐个访问节点的数据。
遍历过程示意图(假设节点数据是整数):
head -> 1 -> 2 -> 3 -> 4 -> tail
void display_next(node *head)
{node *p = head;while(p->next != head){printf("%d ", p->next->data);p = p->next;}printf("\n");
}后继遍历(逆向遍历): 后继遍历是从链表的尾节点开始,沿着前驱指针(prev)向前遍历到链表的头节点为止。这种遍历方式是比较少见的,它按照链表中节点的逆序,从后向前逐个访问节点的数据。
遍历过程示意图(假设节点数据是整数):
tail -> 4 -> 3 -> 2 -> 1 -> head
void display_prev(node *head)
{node *p = head;while(p->prev != head){printf("%d ", p->prev->data);p = p->prev;}printf("\n");
}(6)查找节点
node *find_double_node(node *head, DataType data)
{if (double_isempty(head)){return NULL;}node *p = head;while(p->next!=head){if (p->next->data == data){return p->next;}p = p->next;}return NULL;
}(7)删除节点
bool delete_double_node(node *head, DataType data)
{if (double_isempty(head)){return false;}node *p = head;while(p->next!=head){if (p->next->data == data){node *dele = p->next;dele->next->prev = p;p->next = dele->next;free(dele);dele = NULL;return true;//continue;}p = p->next;}return false;
}(8)更新节点
void update_double_node(node *head, DataType old_data, DataType new_data)
{if (double_isempty(head)){return ;}node *p = find_double_node(head, old_data);if (p!=NULL){p->data = new_data;printf("更新成功\n");}else{printf("更新失败\n");}
}
(9)清空
void clear_double_list(node *head)
{if (double_isempty(head)){return ;}while(head->next != head){node *dele = head->next;dele->next->prev = head;head->next = dele->next;free(dele);dele = NULL;}
}
注意:
(1)双向循环链表的实现相对复杂,需要维护两个指针。
(2)需要特别注意循环条件和指针的正确更新,以避免陷入死循环或产生错误的链接。
更多C语言、Linux系统、ARM板实战和数据结构相关文章,关注专栏:
手撕C语言
玩转linux
脚踢数据结构
6818(ARM)开发板实战
📢写在最后
- 今天的分享就到这啦~
- 觉得博主写的还不错的烦劳
一键三连喔~ - 🎉感谢关注🎉
这篇关于【脚踢数据结构】链表(2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





