本文主要是介绍TV-Unet:使用连接施加的 U-net 分割 covid-19 肺部感染区域 CT 图像,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明
不定期更新自己精度论文,通俗易懂,初级小白也可以理解
涉及范围:深度学习方向,包括 CV、NLP、Data Fusion、Digital Twin

论文标题:COVID TV-Unet: Segmenting COVID-19 chest CT images using connectivity imposed Unet
论文链接:https://doi.org/10.1016/j.cmpbup.2021.100007
论文代码:
发表时间:2021年4月
创新点
1、提出了一种新的分割框架(TV U-net)用于 covid-19 肺部病变区域分割
2、开发了一种基于 2D 各向异性总变化的合适的正则化方法
Abstract
新型冠状病毒病 (COVID-19) 大流行已在全球 200 多个国家/地区引发重大疫情,对全球许多人的健康和生活造成严重影响。到 2020 年 10 月,超过 4400 万人被感染,超过 100 万人死亡。计算机断层扫描 (CT) 图像可用作耗时的 RT-PCR 测试的替代方法,以检测 COVID-19。
在这项工作中,我们提出了一个分割框架来检测 CT 图像中被 COVID-19 感染的胸部区域。采用类似于 U-net 模型的架构来检测体素级别的毛玻璃区域。由于受感染区域倾向于形成连接的组件(而不是随机分布的体素),因此开发了基于 2D 各向异性总变化的合适正则化项并将其添加到损失函数中。因此,所提出的模型被称为“ TV-Unet ”。在大约 900 张图像的相对大规模 CT 分割数据集上获得的实验结果,与从头开始训练的 Unet 相比,结合这个新的正则化项可使整体分割性能提高 2%。
我们的实验分析,从预测分割结果的视觉评估到分割性能的定量评估(精确度、召回率、Dice 分数和 mIoU),证明了识别 COVID-19 相关肺部区域的能力,实现了 mIoU 超过99%,骰子分数约为 86%。
Method

U-net的网络架构如上图所示。
在编码器部分,模型获取图像作为输入并应用多层卷积、最大池和 ReLU 激活,并将数据压缩到潜在空间中;
在解码器部分,网络尝试使用转置卷积操作(反卷积)解码来自潜在空间的信息,并生成图像的分割掩码;
最后,其余操作与前面提到的编码器部分的操作类似。
U-net 网络和普通编码器-解码器模型之间的一个区别是使用跳跃连接将信息从编码器的相应高分辨率层发送到解码器,这可以帮助网络更好地捕获高分辨率中存在的小细节。
---------------------------------------------------------------------------------------------------------------------------------
连通性正则化
作者在实验过程中发现,在损失函数中加入明确的正则化项可以大大提高预测分割区域的准确性,因此开发处了连通性正则化方法,属于严谨的数学推导,感兴趣的可以看一下原文,具体公式如下:

最终,损失函数被定义为:

Experiments
实验目标:不同结构,分割效果图对比
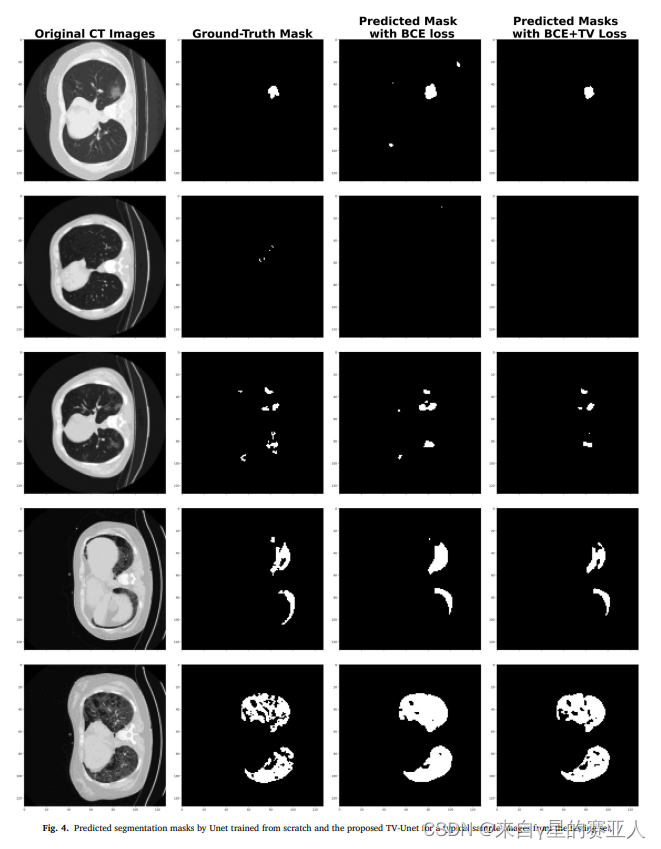
这篇关于TV-Unet:使用连接施加的 U-net 分割 covid-19 肺部感染区域 CT 图像的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




