本文主要是介绍python炼丹师_Python连载|Pandas终章,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原标题:Python连载|Pandas终章
在数据挖掘中,我们常需要对数据进行清洗或者转换,以便于认识数据特征,掌握数据间的关系。下面将重点介绍如何使用Pandas来解决数据挖掘中常见的问题。

1 Pandas缺失数据
数据缺失是数据挖掘中最为常见的问题,下面将讲解如何利用pandas进行缺失值处理。
1.1 查找缺失值
对于数值数据,pandas使用浮点值NaN表示缺失数据。我们可以通过isnull和notnull来检测缺失值:
data = pd . DataFrame ({ 'A' :[ 1 , 6 , np . nan , 4 , np . nan ], 'B' :[ 2 , np . nan , 3 , 9 , 5 ], 'C' :[ 5 , 7 , 9 , 8 , 4 ]})
# 通过isnull和notnull函数检查缺失值
print ( data . isnull ) # True表示NaN
print ( data . notnull ) # False表示NaN
输出结果:
# data.isnull
A B C
0 False False False
1 False True False
2 True False False
3 False False False
4 True False False
# data.notnull
A B C
0 True True True
1 True False True
2 False True True
3 True True True
4 False True True
当然,在实际应用中,我们可以通过以下方法来得出每一列(行)的缺失值个数
print ( data . isnull . sum ) # 统计每一列有多少个缺失值
print ( data . isnull . sum ( axis = 1 )) # 统计每一行有多少个缺失值
输出结果:
# data.isnull.sum
A 2
B 1
C 0
dtype : int64
# data.isnull.sum(axis=1)
0 0
1 1
2 1
3 0
4 1
dtype : int64
除此之外,还可以查找出具有缺失值的行的index
print ( data . index [ data . isnull . sum ( axis = 1 )> 0 ])
输出结果:
Int64Index ([ 1 , 2 , 4 ], dtype = 'int64' )1.2 删除缺失值
通过dropna函数可对缺失值进行删除,具体参数说明如下
dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
axis: 默认为0,删除包含缺失值的行;当为1时,删除包含缺失值的列
how: 默认为any,只要有缺失值出现,就删除;为all时,所有的值都缺失才删除
thresh: axis中至少有thresh个非缺失值,否则删除
subset: 在哪些列中查看是否有缺失值
inplace: 是否在原数据上操作
删除存在空值的行,how默认情况下为any
data . dropna
# 结果为:
A B C
0 1.0 2.0 5
3 4.0 9.0 8
同样,可以删除存在缺失值的列
data . dropna ( axis = 1 ) # 删除存在缺失值的列
# 结果为:
C
0 5
1 7
2 9
3 8
4 4
当how参数设置为all时,只有列中的数据都为空时才删除
data . dropna ( axis = 1 , how = 'all' )
# 结果为:
A B C
0 1.0 2.0 5
1 6.0 NaN 7
2 NaN 3.0 9
3 4.0 9.0 8
4 NaN 5.0 4
也可根据实际需求来设置thresh参数
print ( data . dropna ( axis = 1 , thresh = 4 )) # 每一列的非空值个数>=4,否则删除
data . dropna ( axis = 1 , thresh = 4 , inplace = True ) # 在原数据上操作
print ( data )
输出结果
# data.dropna(axis = 1,thresh = 4)
B C
0 2.0 5
1 NaN 7
2 3.0 9
3 9.0 8
4 5.0 4
# data
B C
0 2.0 5
1 NaN 7
2 3.0 9
3 9.0 8
4 5.0 41.3 缺失值填补
除了对缺失值进行删除外,我们还可以使用fillna函数来对缺数值进行填补。具体参数说明如下
fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
value:用于填充缺失值的标量值或字典对象
method:插值方式。如果函数调用时未指定其他参数的话,默认为‘ffill’
axis:待填充的轴,默认为0
inplace:是否在原数据上操作
limit:对于前向和后向填充,可以连续填充的最大数量
可以使用0值或者均值来填补缺失值
data = pd . DataFrame ({ 'A' :[ 1 , 6 , np . nan , 4 , np . nan ], 'B' :[ 2 , np . nan , 3 , 9 , 5 ], 'C' :[ 5 , 7 , 9 , 8 , 4 ]})
print ( data )
print ( data . fillna ( 0 )) # 使用0来填充缺少值
print ( data . fillna ( data . mean )) # 用均值来填补缺失值
输出结果:
# data
A B C
0 1.0 2.0 5
1 6.0 NaN 7
2 NaN 3.0 9
3 4.0 9.0 8
4 NaN 5.0 4
# data.fillna(0)
A B C
0 1.0 2.0 5
1 6.0 0.0 7
2 0.0 3.0 9
3 4.0 9.0 8
4 0.0 5.0 4
# data.fillna(data.mean)
A B C
0 1.000000 2.00 5
1 6.000000 4.75 7
3 4.000000 9.00 8
此外,还可以传入字典,对不同列的缺失值进行填补
print ( data . fillna ( value = { 'A' : 0.5 , 'B' : 0.4 })) # 用0.5来填补A列的空值,0.4来填补B列的空值
# 结果为:
A B C
0 1.0 2.0 5
1 6.0 0.4 7
2 0.5 3.0 9
3 4.0 9.0 8
4 0.5 5.0 4
也可以通过向前填充和向后填充来对缺失数据进行填补
print ( data . fillna ( method = 'pad' )) # 将缺失值按照前面一个值进行填充。pad/fill 填充方法向前
print ( data . fillna ( method = 'bfill' )) # 将缺失值按照后面一个值进行填充。bfill/backfill 填充方法向后
print ( data . fillna ( axis = 1 , method = 'bfill' )) # 修改轴方向,用后面列的值来填充
输出结果
# data.fillna(method='pad')
A B C
0 1.0 2.0 5
1 6.0 2.0 7
2 6.0 3.0 9
3 4.0 9.0 8
4 4.0 5.0 4
# data.fillna(method='bfill')
A B C
0 1.0 2.0 5
1 6.0 3.0 7
2 4.0 3.0 9
3 4.0 9.0 8
4 NaN 5.0 4
# data.fillna(axis=1,method='bfill')
A B C
0 1.0 2.0 5.0
1 6.0 7.0 7.0
2 3.0 3.0 9.0
3 4.0 9.0 8.0
4 5.0 5.0 4.0
limit参数限制填充个数
df = pd . DataFrame ({ 'A' :[ 1 , 6 , np . nan , np . nan , np . nan ], 'B' :[ 2 , np . nan , 3 , 9 , 5 ], 'C' :[ 5 , 7 , 9 , 8 , 4 ]})
print ( df )
print ( '==================' )
print ( df . fillna ( method = 'pad' , limit = 1 )) # 限制向前填充个数为1
输出结果
A B C
0 1.0 2.0 5
1 6.0 NaN 7
2 NaN 3.0 9
3 NaN 9.0 8
4 NaN 5.0 4
==================
A B C
0 1.0 2.0 5
1 6.0 2.0 7
2 6.0 3.0 9
3 NaN 9.0 8
4 NaN 5.0 41.4 数据替换
pandas中还可使用replace来进行数据替换
replace(self,to_replace = None,value = None,inplace = False,limit = None,regex = False,method ='pad' )
将to_replace替换成value
to_replace:被替换的值
value:用于替换的值,可以是标量,字典,列表等
inplace:是否在原数据上操作
limit:向前或向后填充的最大间隔
下面举例来介绍replace的使用方法
df = pd . DataFrame ({ 'one' :[ 10 , 20 , 30 , 40 , 50 ],
'two' :[ 1000 , 0 , 30 , 40 , 50 ]})
print ( df . replace ( 0 , 100 )) # 将0替换成100
# 结果为:
one two
0 10 1000
1 20 100
2 30 30
3 40 40
4 50 50
也可以传入字典、列表来对数值进行替换
print ( df . replace ({ 0 : 666 , 1000 : 888 })) # 用字典形式来替换多个数值,字典的key为原值,value为替换后的值
print ( df . replace ([ 0 , 50 ],[ 666 , 5 ])) # 用列表的形式替换多个数值,传入两个列表,第一个列表中的值为原值,第二列表中的值为替换值
输出结果
# df.replace({0:666,1000:888})
one two
0 10 888
1 20 666
2 30 30
3 40 40
4 50 50
# df.replace([0,50],[666,5])
one two
0 10 1000
1 20 666
2 30 30
3 40 40
4 5 5
使用正则表达式来替换,将所有大写英文替换成N。在使用正则表达式替换时,必须将regex设置为True
print ( df . replace ( r '[A-Z]' , 'N' , regex = True ))
# 结果为:
one two
0 10 1000
1 20 N
2 30 30
3 40 40
4 N N2. 长宽表转换
长格式数据:每一行数据记录的是ID的一个属性,形式为key:value
宽格式数据:每一行数据为是一条完整的记录,记录着ID的各种属性
长格式数据和宽格式数据的形式如下
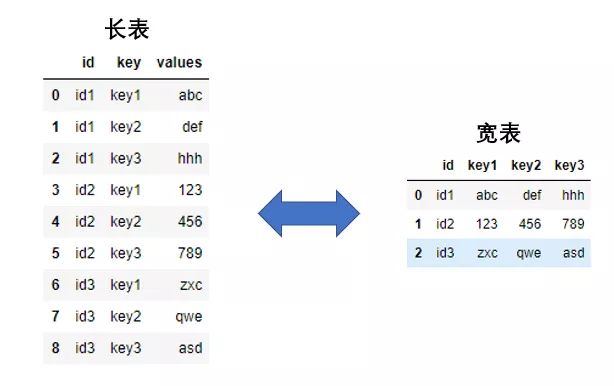
2.1 长表转宽表
使用pivot可将长格式数据转换成宽格式数据,参数columns是长格式数据中的key键对应的列名;参数values是长格式数据中的value对应的列。
data = pd . DataFrame ({
'id' :[ 'id1' ]* 3 + [ 'id2' ]* 3 + [ 'id3' ]* 3 ,
'Introduction' :[ 'int1' , 'int2' , 'int3' ]* 3 ,
'Message' : [ 'abc' , 'def' , 'hhh' , '123' , '456' , '789' , 'zxc' , 'qwe' , 'asd' ]
})
print ( data ) # 长表
data_p = data . pivot ( index = 'id' , columns = 'Introduction' , values = 'Message' )
print ( data_p ) # 转成宽表
输出结果
# data
id Introduction Message
0 id1 int1 abc
1 id1 int2 def
2 id1 int3 hhh
3 id2 int1 123
4 id2 int2 456
5 id2 int3 789
6 id3 int1 zxc
7 id3 int2 qwe
8 id3 int3 asd
# data_p
Introduction int1 int2 int3
id
id1 abc def hhh
id2 123 456 789
id3 zxc qwe asd
此外,也可以使用pivot_table将长表格转换成宽表格,但有一点需要注意,由于pivot_table函数对values进行计算(求和、平均等),所以values要为数值型数据
data2 = pd . DataFrame ({
'Company' :[ 'C1' ]* 3 + [ 'C2' ]* 3 + [ 'C3' ]* 3 + [ 'C4' ]* 3 ,
'Year' :[ '2017' , '2018' , '2019' ]* 4 ,
'Sale' :[ 2000 , 1500 , 3000 , 3500 ]* 3
})
print ( data2 )
data2_pt = data2 . pivot_table ( index = 'Company' , columns = 'Year' , values = 'Sale' )
print ( data2_pt )
输出结果
# data2
Company Year Sale
0 C1 2017 2000
1 C1 2018 1500
2 C1 2019 3000
3 C2 2017 3500
4 C2 2018 2000
5 C2 2019 1500
6 C3 2017 3000
7 C3 2018 3500
8 C3 2019 2000
9 C4 2017 1500
10 C4 2018 3000
11 C4 2019 3500
# data2_pt
Year 2017 2018 2019
Company
C1 2000 1500 3000
C2 3500 2000 1500
C3 3000 3500 2000
C4 1500 3000 35002.2 宽表转长表
在pandas中,只需使用melt函数,即可将宽表转成长表
wide_data = pd . DataFrame ({
'id' :[ 'id1' , 'id2' , 'id3' ],
'name' :[ '小李' , '小何' , '小周' ],
'sex' :[ 'male' , 'male' , 'female' ],
'score' :[ 89 , 60 , 76 ]
})
print ( wide_data )
wide_data = wide_data . melt ( id_vars = 'id' ,
var_name = 'Introduction' , value_name = 'Message' )
print ( wide_data )
输出结果
# 转换前
id name sex score
0 id1 小李 male 89
1 id2 小何 male 60
2 id3 小周 female 76
# 转换后
id Introduction Message
0 id1 name 小李
1 id2 name 小何
2 id3 name 小周
3 id1 sex male
4 id2 sex male
5 id3 sex female
6 id1 score 89
7 id2 score 60
8 id3 score 763. pandas0.25新功能 3.1 Groupby的命名聚合
可以直接为指定的聚合输出列命名
# 创建样例数据
data1 = pd . DataFrame ({ '列1' :[ 'aa' , 'bb' , 'aa' , 'bb' ],
'列2' :[ 8.1 , 6.0 , 10.5 , 34.0 ],
'列3' :[ 7.9 , 7.5 , 9.9 , 50.0 ]})
print ( data1 )
列 1 列 2 列 3
0 aa 8.1 7.9
1 bb 6.0 7.5
2 aa 10.5 9.9
3 bb 34.0 50.0
在Pandas0.25中,命名聚合支持中文变量名
data1 . groupby ( '列1' ). agg (
最低 = pd . NamedAgg ( column = '列2' , aggfunc = 'min' ),
最高 = pd . NamedAgg ( column = '列2' , aggfunc = 'max' ),
平均 = pd . NamedAgg ( column = '列3' , aggfunc = np . mean ),
总和 = pd . NamedAgg ( column = '列3' , aggfunc = np . sum )
)
输出结果:
最低 最高 平均 总和
列 1
aa 8.1 10.5 8.90 17.8
bb 6.0 34.0 28.75 57.53.2 Groupby聚合支持多个lambda函数
以 list 方式向 agg 函数传递多个 lambda 函数
data1 . groupby ( '列1' ). agg ([
lambda x : x . iloc [ 0 ] - x . iloc [ 1 ],
lambda x : x . iloc [ 0 ] + x . iloc [ 1 ]
])
输出结果:
列 2 列 3
< lambda_0 > < lambda_1 > < lambda_0 > < lambda_1 >
列 1
aa - 2.4 18.6 - 2.0 17.8
bb - 28.0 40.0 - 42.5 57.53.3 explode方法
Series 与 DataFrame 增加了 explode 方法,将list形式的值转换为单独的行
df = pd . DataFrame ([{ '变量1' : 'a,b,c' , '变量2' : 1 },
{ '变量1' : 'd,e,f' , '变量2' : 2 }])
var_list = df [ '变量1' ]. str . split ( ',' )
var_explode = df [ '变量1' ]. str . split ( ',' ). explode
print ( var_list )
print ( var_explode )
输出结果:
# var_list
0 [ a , b , c ]
1 [ d , e , f ]
Name : 变量 1 , dtype : object
# var_explode
0 a
0 b
0 c
1 d
1 e
1 f
Name : 变量 1 , dtype : object3.4 Query支持列名空格
data = [
{ '姓 名' : '张三' , '城 市' : '北京' , '年 龄' : 18 },
{ '姓 名' : '李四' , '城 市' : '上海' , '年 龄' : 19 , '爱 好' : '打游戏' },
{ '姓 名' : '王五' , '城 市' : '广州' , '年 龄' : 20 , '财务状况' : '优' }
]
data = pd . DataFrame ( data )
上方示例数据的列名是有空格的,只需用反引号(`)括住列名,就可以进行查询了
data . query ( '`年 龄` < 19' )
姓 名 城 市 年 龄 爱 好 财务状况
0 张三 北京 18 NaN NaN
至此,本次分享已结束
如果你喜欢的话,可以转发或者点个“在看”支持一下~
点击原文链接,可以下载《Python工具代码速查手册》,可以点个star支持一下哦~简介:浩彬老撕 好玩的数据炼丹师, 曾经的IBM数据挖掘攻城狮, 还没开始就过气数据科学界的段子手, 致力于数据科学知识分享,不定期送书活动
责任编辑:
这篇关于python炼丹师_Python连载|Pandas终章的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








