本文主要是介绍申通单号如何批量跟踪已揽收单号,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一般商家下午会发货,到第二天就会去跟踪下物流信息,看下有没有揽收呢,大量单号要如何去跟踪呢,大家都说跟踪方法很多种,比如一个一个单号复制到百度上去查询,或一次复制10个或20个单号到快递官网上也可以跟踪,这两种方法是适用快递量少,如果每天需要跟踪上千或上万个单号对这两种方法是行不通,有没有什么好的方法可以一次性批量跟踪呢?小编在些分享一个好方法,这时里需要用到一个工具【批量查询高手】软件

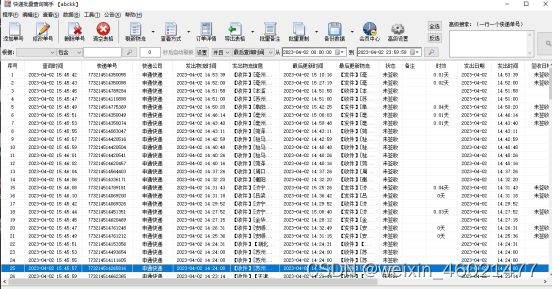
大家先浏览利用这个软件跟踪好了单号是什么样子,软件会显示单号,快递公司名称,发出物流信息,时间,发出物流信息,最后更新时间,最后更新物流,状态,时效等等。
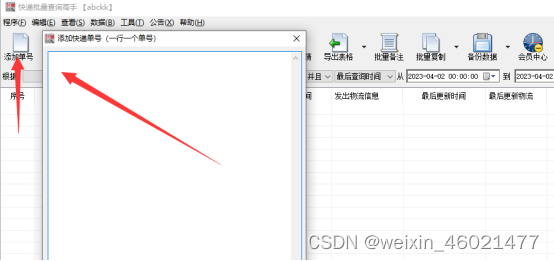
接下来分享下操作方法1、打开【快递批量查询高手】并点击【添加单号】这个功能
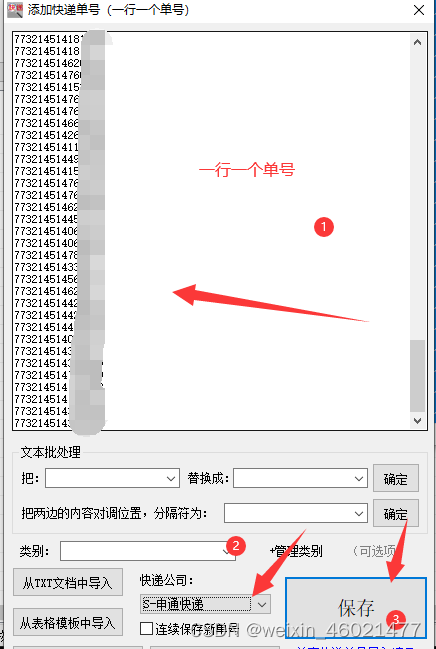
- 把需要查询单号复制粘贴进去一行一个单号保存、粘贴好了选下快递公司名称再点【保存】
-
保存好了软件会自动跟踪每个单号物流信息情况,可以看到软件正在跟踪中
-
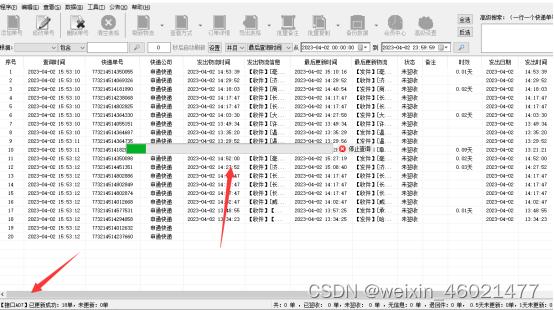
4软件批量跟踪好了
-
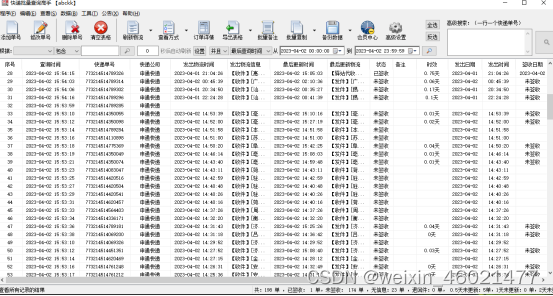
- 先这里说明下,根据自己多年经验来分析出,查询出来单号有物流信息,一般都是有揽收信息,可以任意点一个单号进去看下是否单号是已揽收
-
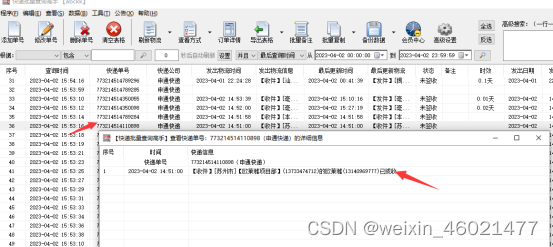
大量单号中如何只看有揽收单号,其他无揽收单号不需要看呢,可以这里面根据发出物流信息关键词【揽收】再点搜索,筛选出来都是已揽收单号
-
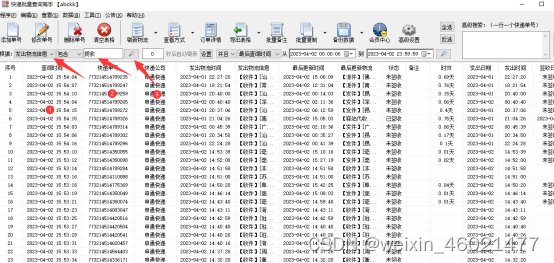
刚才上面有看下有些单号什么是空白没有信息呢,这类单号 一般是没有揽收单号,那么要如何查看这些无揽收单号,并复制出来或导出表格呢,在这里点查看方式 【无物流信息】筛选出来再点右上角【全选】,然后点击【批量复制】再选【批量复制快递单号】
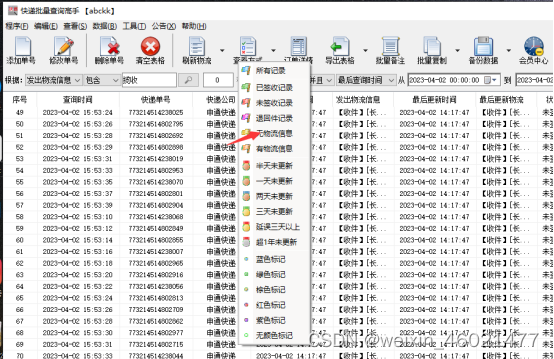
出来单号都是无信息

复制好
可以粘贴到表格或记事本上都很方便哦
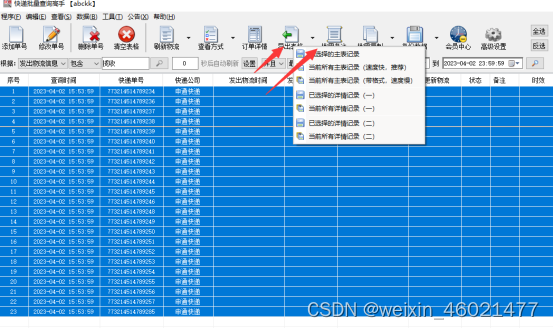
也可以把这些无信息单号导出表格,当然要导出有信息单号也可以,这个是根据自己需要来选导出,这里是导出无信息单号,点【导出表格】,再点击【导出已选的主表记录】
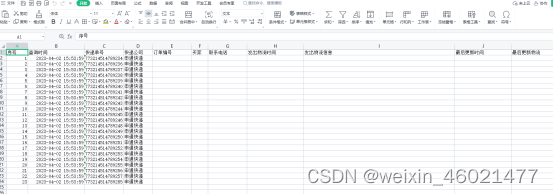
导出好了可以直接打开表格看下
有需要小伙伴可以动动手一起来操作下。欢迎大家一起来交流学习下。
这篇关于申通单号如何批量跟踪已揽收单号的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








