本文主要是介绍iOS人工智能交流模型4-用CC_ANN实现DNN网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大纲
- 神经网络学习
- 常用模型分析
- iOS中的CoreML等闭源库
- 通过bench_ios中的CC_ANN使用激活函数ReLU和Sigmoid实现DNN网络。
- caffe、tensorflow等对比
目录:
- 介绍一个CC_ANN使用例子
- 回顾神经网络的构成
- 进行一次完整计算
CC_ANN是用oc封装的一层和多层神经网络例子,支持激活函数Sigmoid和ReLU
调用例子
//一次乘法的学习
//创建一个ANN网络
CC_ANN *ann=[[CC_ANN alloc]init];//学习100次
int count=100
[ann autoTrainTwoToOne:@[@[@[@(0.2),@(0.6)],@(0.12)],@[@[@(0.4),@(0.6)],@(0.24)],@[@[@(0.3),@(0.4)],@(0.12)]] activeFunction:ActiveFunctionTypeSigmoid trainTimes:count];
double predict1=[ann calWithInput:@[@(0.2),@(0.6)]];
double predict2=[ann calWithInput:@[@(0.4),@(0.6)]];
double predict3=[ann calWithInput:@[@(0.3),@(0.4)]];
double predict4=[ann calWithInput:@[@(0.4),@(0.5)]];
NSLog(@"p1=%f p2=%f p3=%f p4=%f",predict1,predict2,predict3,predict4);
//打印结果
p1=0.121306 p2=0.237448 p3=0.122096 p4=0.208426
耗时0.002秒
//学习1000次
int count=1000
//打印结果
p1=0.120000 p2=0.239999 p3=0.120001 p4=0.209638
耗时0.026秒
//学习10000次
int count=10000
//打印结果
p1=0.120000 p2=0.240000 p3=0.120000 p4=0.209638
耗时0.28秒
例子结论:
- 学习次数越多,对例子的还原越正确。如2*6越来越接近12
- 学习次数到达一定次数后,对预测的精确度不会再提高。如我们没有教过4*5,但是预测答案接近20,在学习1000次后,达到20.9638,但是学习10000次也没有将精度再次提高
这个例子符合神经网络的特征
下面看下如何构建一层神经网络,具体的计算方法。

线性函数和sigmoid函数
LinearRegression模型: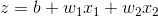
sigmoid函数: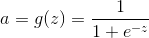
隐层决定了最终的分类效果

可以看到,隐层越多,分类效果越好,因为可以转折的点更多。实际上,Kolmogorov理论指出:双隐层感知器就足以解决任何复杂的分类问题。
但是,过多的隐层和神经元结点会带来过拟合问题,不要试图降低神经网络参数量来减缓过拟合,用正则化或者dropout。
神经网络结构

传递函数/激活函数
每一层传递使用wx+b,对每一个输出使用sigmoid、tanh、relu等激活函数使线性的结果非线性化。
为什么需要传递函数?
简单理解上,如果不加激活函数,无论多少层隐层,最终的结果还是原始输入的线性变化,这样一层隐层就可以达到结果,就没有多层感知器的意义了。所以每个隐层都会配一个激活函数,提供非线性变化。
BP算法
一个反馈网络,类似生物的反馈网络,和人走路不会摔倒一样,每一次输出都会有反馈去修正误差,使下一次结果更接近理想结果。

以三层感知器为例做计算:
网络结构

可以用到的公式为:


代入参数:

两个输入;
隐层: b1, w1, w2, w3, w4 (都有初始值) 计算一个合理的初始值可以使用前面提到的HE初始化、随机初始化和pre-train初始化
输出层:b2, w5, w6, w7, w8(赋了初始值)
这里使用sigmoid激活函数

用E来衡量误差大小,为反馈提供支持:
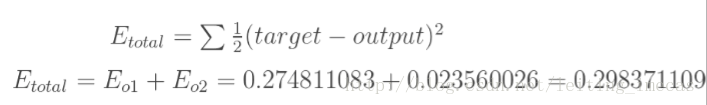
获得E后反向计算误差:
对E求导就可计算出误差梯度

计算出w5、w6、w7、w8的误差梯度:
误差梯度乘以学习率即是需要调整的误差值

同理,再向上一级推导出w1-w4的误差值:

完成一次反向传播:
求误差对w5的偏导过程 参数更新: 求误差对w1的偏导 注意,w1对两个输出的误差都有影响
通过以上过程可以更新所有权重,就可以再次迭代更新了,直到满足条件。
可以提供的数学函数:
@interface CC_Math : NSObject+ (double)sign:(double)input;/*** 激活函数*/
+ (double)sigmoid:(double)input;
+ (double)reLU:(double)input;/*** 双s曲线*/
+ (double)doubleS:(int)input;/*** 标准正态分布*/
+ (double)randn:(double)input;/*** 获得初始化权重* length w个数*/
+ (NSMutableArray *)getW_positive_unitball:(int)length;
/*** weight = np.random.randn(in_node, out_node)/np.sqrt(in_node)*/
+ (NSMutableArray *)getW_XavierFiller:(int)length;
/*** Xavier论文中使用的激活函数是tanh函数,而神经网络中使用较广泛的是relu激活函数,所以提出此方法。weight = np.random.randn(in_node, out_node)/np.sqrt(in_node/2)*/
+ (NSMutableArray *)getW_MSRAFiller:(int)length;@end
可以提供的ANN函数
typedef enum : NSUInteger {ActiveFunctionTypeReLU,ActiveFunctionTypeSigmoid,//如使用sigmoid 输入输出范围在[-1,1]
} ActiveFunctionType;@interface CC_ANN : NSObject/*** 训练结束后可计算结果*/
- (double)calWithInput:(NSArray *)input;//- (double)calWithInput_twolevel:(NSArray *)input;/*** 一层深度学习* samples 学习样本 多个样本以数组形式例:@[@[@[@(0.2),@(0.6)],@(0.12)],@[@[@(0.4),@(0.6)],@(0.24)]]* weights 初始化权重 一层深度 2个输入1个输出需要权重 2^2+2=6个初始值* learningRate 学习率 选一个较小值 如0.4* activeFunction 激活函数* times 训练次数*/
- (void)trainTwoToOne:(NSArray *)samples weights:(NSArray *)weights learningRate:(double)learningRate activeFunction:(ActiveFunctionType)activeFunction trainTimes:(int)times;/*** 一层深度学习 自动寻找最佳学习率 自动获取初始化权值w* activeFunction 激活函数* times 训练次数*/
- (void)autoTrainTwoToOne:(NSArray *)samples activeFunction:(ActiveFunctionType)activeFunction trainTimes:(int)times;/*** 一层深度学习 自动寻找最佳学习率 自动获取初始化权值w* errorRate 到最小错误率前不会停止学习*/
- (void)autoTrainTwoToOne:(NSArray *)samples activeFunction:(ActiveFunctionType)activeFunction untilErrorRate:(double)errorRate;- (void)trainTwoToOne:(NSArray *)samples trainTimes:(int)times deep:(int)deep;
- (void)trainTwoToOne:(NSArray *)samples trainTimes:(int)times;@end
demo下载
https://github.com/gwh111/bench_ios
这篇关于iOS人工智能交流模型4-用CC_ANN实现DNN网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





