本文主要是介绍万里之行头一步——MySQL连接参数init_connect的简单使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作为Mysql的一个连接参数,init_connect本身并不十分抢眼,官方手册中对其介绍只有几行,只简单指出了init_connect的一些基本规则:
- 只有在普通用户的客户端连接时才能执行这个参数,超级用户或有连接管理权限的用户会跳过这个设置;
- 一个init_connect可以带一个或多个sql语句;
- init_connect的sql语句中若包含错误,则会导致连接失败。
用于审计
从具体的使用角度讲,在网上能查到的init_connect使用率最高的,就是结合mysql自身的日志进行的审计功能,而init_connect则是被用来记录普通用户的登录信息,追踪业务操作时,可以根据记录的用户线程编号,用户名等基本信息,跟踪日志中该用户的所有操作。下面我们通过mysql单机版本,简述该审计功能的实现过程和最终效果。
我们选择的mysql是8.0.23,mysql的编译、安装、初始化等操作这里不做过多描述,相关内容请读者自行搜索学习。

网上很多资料写的是通过general-log的内容进行审计跟踪,但由于general-log会记录用户登录后的所有内容,因此存在IO占用和资源消耗的问题,所以还通过binlog的进行,改变数据库的SQL语句执行结束时,将在binlog的末尾写入一条记录,同时通知语句解析器,语句执行完毕,我们可以根据这个信息,对binlog能够记录的内容进行审计跟踪。

在配置文件中配置binlog的位置,系统根据执行的持续,自动生成.000001及以后的文件。
接下来我们来看init_connect的设置:
首先我们需要在cnf文件中增加init_connect参数,value是向一个记录用户登录信息的表中写入该登录用户的线程编号,登录时间等基本内容,具体语句为:
init_connect='insert into auditdb.access(thread_id,login_time,localname,matchname) values (connection_id(),now(),user(),current_user());'
由语句显示,每一个登录服务器的普通用户,都会自动把自己的thread_id,当前时间,用户名,匹配规则等内容,记录到auditdb库的access表中。如果需要记录其他更多的内容,可根据业务需要和系统函数所能提供的功能,调整这个表以及字段。
create database auditdb;
create table auditdb.access(
id int not null auto_increment,
thread_id int not null,
login_time timestamp,
localname varchar(50) default null,
matchname varchar(50) default null,
primary key (id)
) comment '审计用户登录信息';
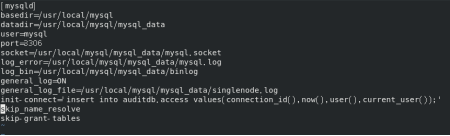
修改了cnf文件,根据情况需要重启MySQL服务,使参数在本次启动中生效。
数据库管理员登录,创建实际存储普通用户登录记录的库和表。
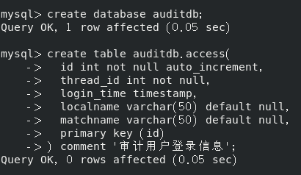
根据实际使用需要,创建存储业务数据的库。
create database testDB;
创建一个普通用户,要求这个用户的所有操作被审计。
CREATE USER 'user1'@'%' IDENTIFIED BY '123456'; --创建用户user1
GRANT ALL ON testDB.* TO 'user1'@'%'; --首先授权user1可以通过任何位置访问testDB库的所有操作
GRANT insert on auditdb.access to 'user1'@'%'; --此步最关键,授权user1对访问记录表有写入权限,因为在init_connect中设置了普通用户要对这个表进行写入,因此如果不设定这个权限,user1永远不能访问任何一个库。
flush privileges; --刷新所有用户权限生效
检验审计效果:
使用刚刚创建的普通用户user1登录。
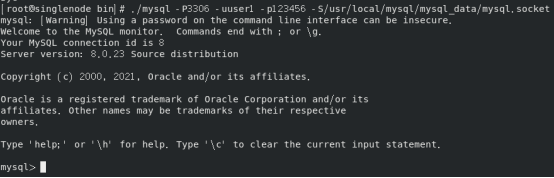
登录成功,说明init_connect中,写入记录表的操作成功了。
有了thread_id,该用户在数据库里的所有被记录在binlog中的操作就都能被跟踪了。
查看binlog有两种方法,一个是在登录mysql的状态下,通过show命令,可以有格式的查看记录:

使用 show binlog events in ‘binlogfile’;
其中Pos和End_log_pos成对出现,可以理解为一个事务的开始和结束,下面的截图中可以看到,从10292到10323,完成一个提交,10402到10479是一个事务开始,10479到10531查询的是testDB.tb3这个表,10531到10575对这个表(id都是128)执行了写入,最后从10575到10606做提交。
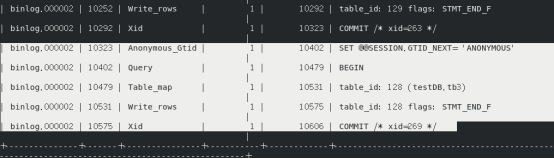
那么如何知道这些操作是谁完成的能,则需要通过mysqlbinlog查看具体信息:
mysqlbinlog binlog.000002

找到刚才10402到10479开始事务的位置,看到有一个thread_id=33,这个就是执行接下来操作的用户ID,登录状态下,可以直接执行select connection_id();查看当前用户的这个值。而init_connect要做的,就是把每次用户登录时他的thread_id记录下来。
具体能审计的内容受binlog中的内容限制,对于二进制文件可以通过mysqlbinlog打开然后重定向到文件,再进行文本过滤。
对于init_connect的扩展使用:
如前面所讲,init_connect的功能其实本身非常简单,无非就是让普通用户在连接服务器的时候能够自动执行SQL语句,那么除了做审计记录登记的功能,可能还有的用途就是给普通用户做某些功能的初始化或清理某些数据,当然比较复杂的功能我们完全可以写成存储过程或函数,init_connect执行一个call,自动执行一大批任务。下面我们来简单尝试一下:
无论是初始化数据还是清理数据,我们都可以看作是一系列操作,具体如何操作其实我们并不十分关心,我们考虑把一系列操作或多条SQL语句放在一个存储过程中,而使用init_connect调用存储过程来简化执行的步骤。
假设当前mysql系统中包含一个testDB库,其中包含一个tb1(id int primary key auto_increment,time timestamp, comment text)表。
我们编写一个存储过程,自动向这个表里写一些内容。
DELIMITER //
CREATE PROCEDURE init_insert()
begin
insert into testDB.tb1 (time,comment) values (now(),’insert by procedure’);
end //
DELIMITER ;
由于这个存储过程是在testDB这个库中创建的,因此在登录状态下,尝试了使用
use testDB;
call init_insert();
和登录后直接
call testDB.init_insert();
的方式都是可以正常执行的,考虑init_connect的时候没有use库,所以我们按call testDB.init_insert()的方式写。
![]()
普通用户登录,查询testDB.tb1,

我们进一步看,一个init_connect中顺序执行多条SQL语句的用法。
还用刚才的testDB库,再创建一个tb2(a int,b int);,同样的思路,继续给用户user1在tb2上的写入权限。
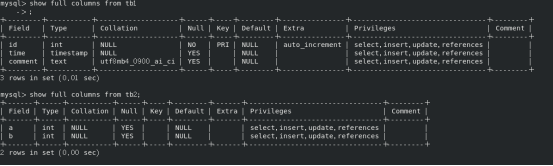
在cnf的init_connect中写为两个SQL的形式
![]()
尝试普通用户连接并查看相关表记录。

综上所述,init_connect的功能相对简单,只是让普通用户在连接时自动执行一些语句,甚至DBA都不关心当时执行返回了哪些结果,而直接的效果就是成功执行则可以use下去,不成功执行则会报类似

的错误。
使用注意
init_connect的功能虽然简单,官方文档介绍的篇幅也不大,但是在验证上面的功能时,发现了一个比较麻烦的问题,就是init_connect虽然是控制客户端连接时执行的内容,但是这个设定需要在初始化data目录的时候就设置好,单纯的重启已有的库,对于参数修改是没有效果的,也可能因为这个小功能上,mysql本身没有给予太多的关注,所以在使用上多少有点儿限制,但总之init_connect功能比较简单,可做的事情也非常有限,我们利用好他提供的用户登录信息记录,做好审计相关的内容就足够了,这也是目前在网上关于这个参数讨论最多的用法。
这篇关于万里之行头一步——MySQL连接参数init_connect的简单使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



