本文主要是介绍数据改版 | CnOpenData中国工商企业进入退出信息统计数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CnOpenData中国工商企业进入退出信息统计数据
一、数据简介
在改革开放、建设中国特色社会主义市场经济体制的时代背景下,各行业、各经济性质的市场主体积极投身市场活动,为中国乃至全世界的市场经济发展提供着源源不断的动力支持。
根据我国相关法律规定,设立公司须依法向公司登记机关申请设立登记,相关市场主体的基本信息也随之披露,这类公开信息包括企业主营业务分类、注册地址、注册资金、注册日期等,为研究中国企业生存状况、行业覆盖和市场活力等方面的问题提供了极佳的研究数据支撑。
但同时学者在使用这些数据时常常面临诸多困难:工商注册企业基本信息数据之复杂堪比恒河沙数,如此大规模的数据量在获取、使用时都太过费时费力。
为便于学者研究,CnOpenData对工商注册企业基本信息数据进行统计处理,为研究人员提供了各个维度的统计数据。
二、数据特点
- 从覆盖地域看:本数据详细统计了中国34个省份/直辖市/自治区/特别行政区对应的372个城市、2972个区县的工商注册企业数量;
- 从时间区间看:本数据详细统计了1950年至今长达72年的工商注册企业数量,足以展现中国建国以来工商业的发展情况;
+ 从企业性质来看:本数据详细统计了个体工商户、民营企业、集体所有制企业、外商投资企业、国有企业、事业单位的数量;
+ 从覆盖行业来看:本数据详细统计了批发和零售业、住宿和餐饮业、制造业等20个行业中的企业信息;- 本数据不仅统计了各地区、各年度、各行业、各企业性质的新增企业数量,还统计了注销企业数量,得出存续企业数量;
- 本数据从二维、三维、四维的角度分别进行统计处理,字段丰富,表格完整,覆盖了各维度的统计需求。
三、数据规模
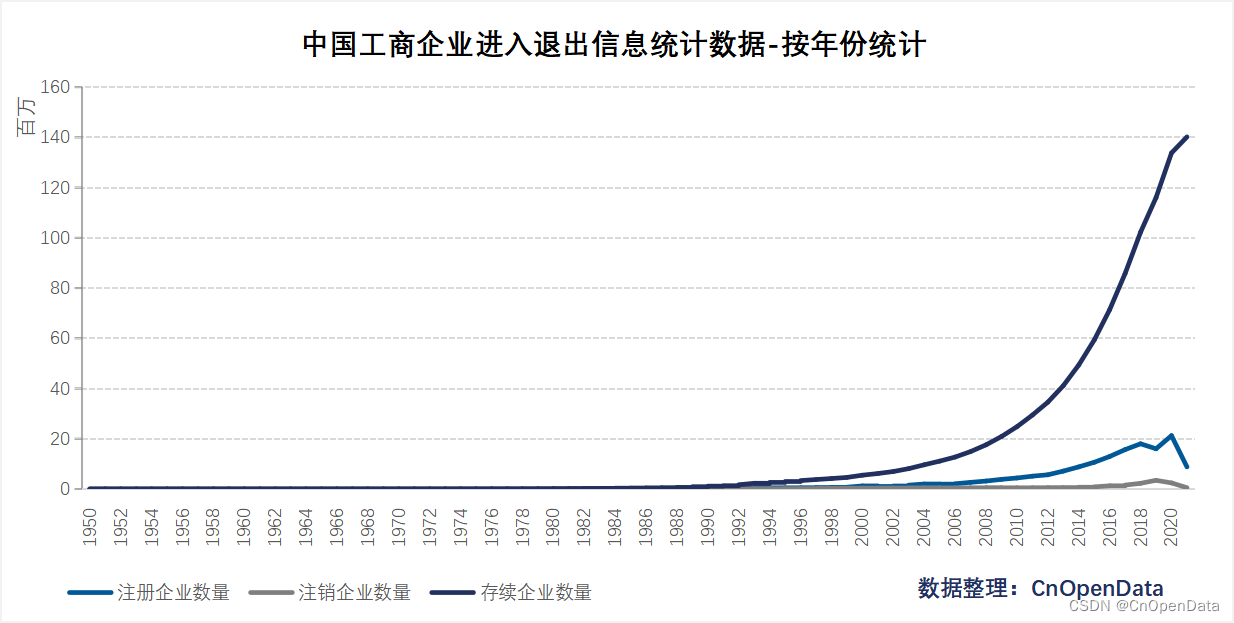
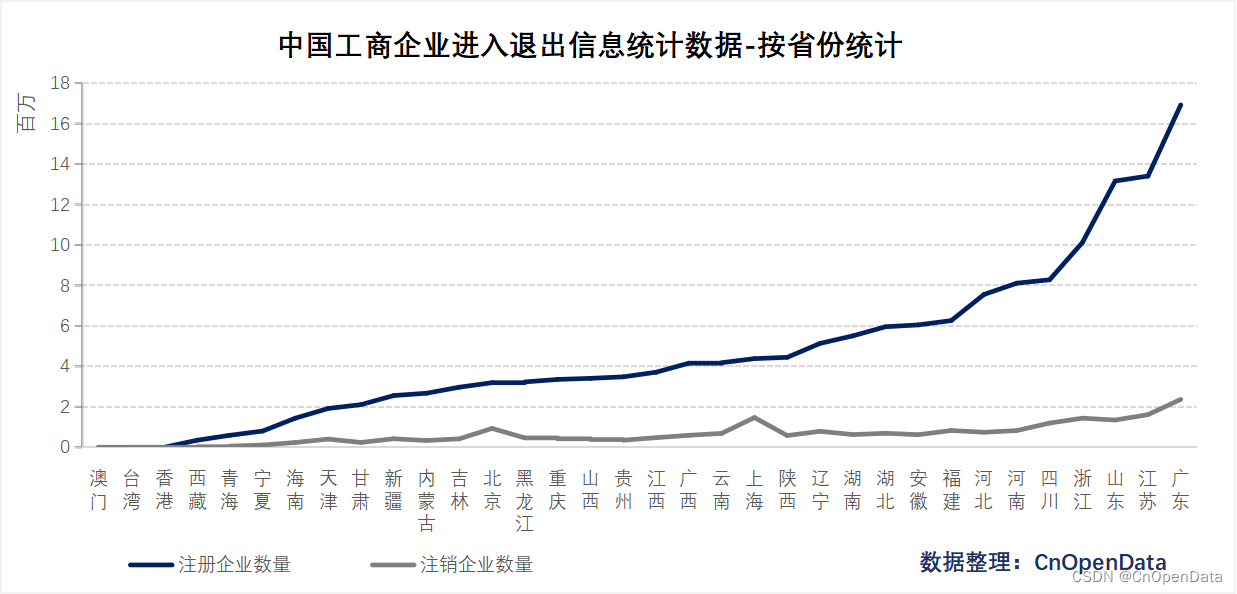
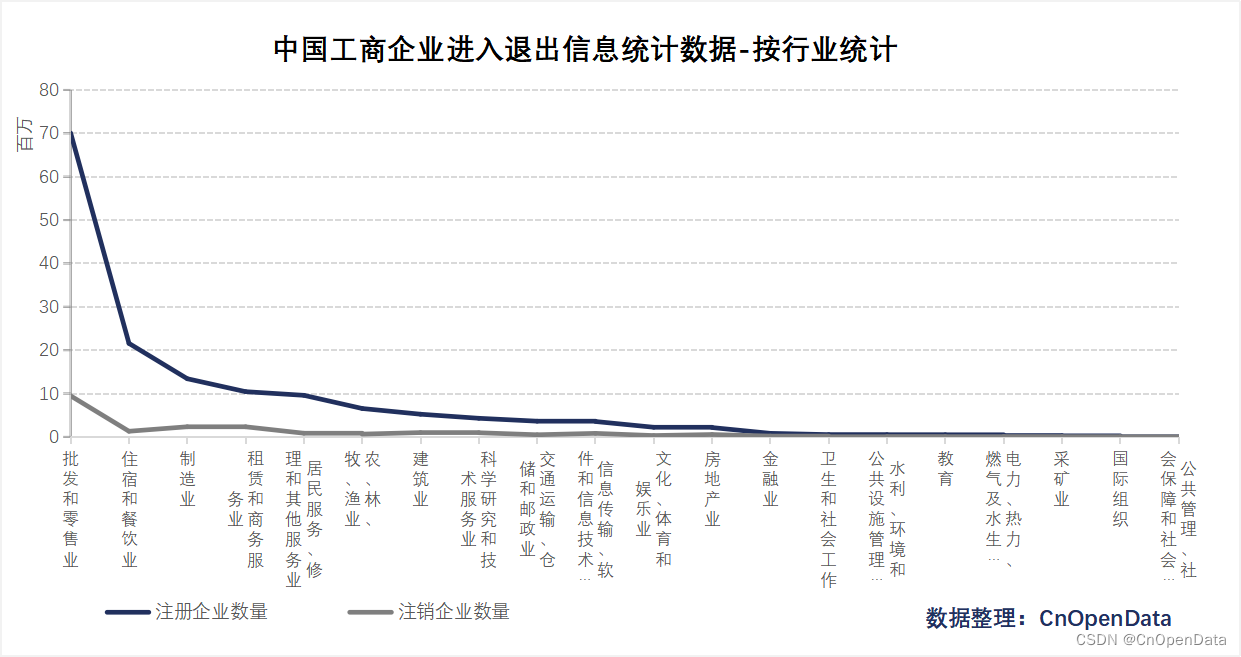
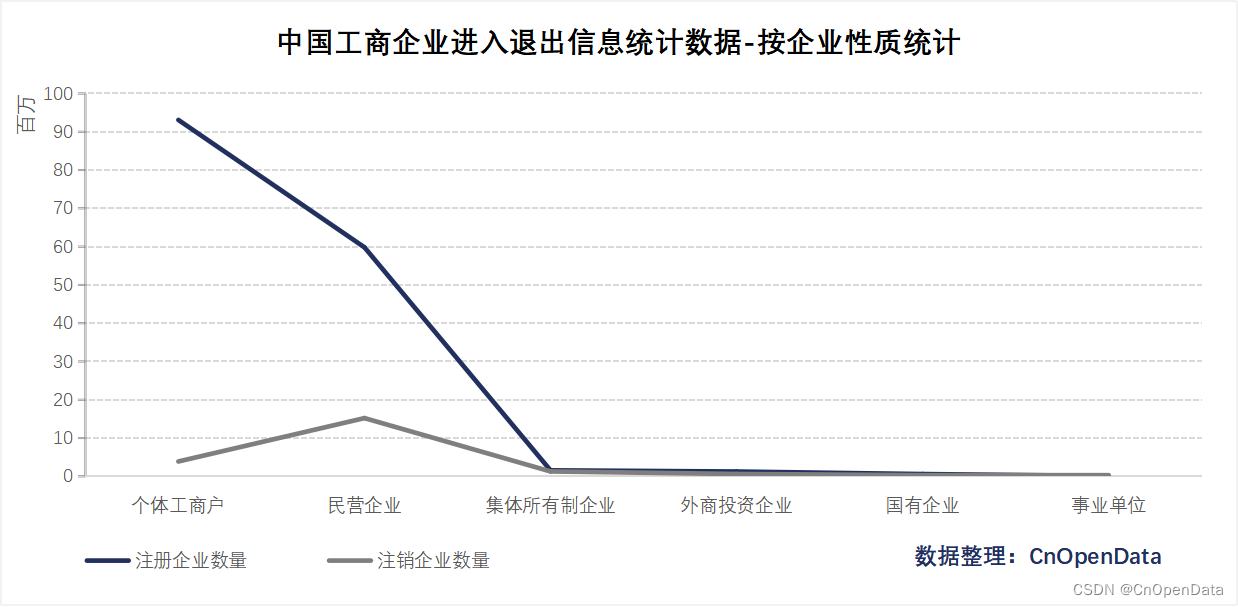
四、时间区间
195
这篇关于数据改版 | CnOpenData中国工商企业进入退出信息统计数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






