本文主要是介绍分布式分析型数据库:星环科技ArgoDB 3.2正式发布,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Transwarp ArgoDB是星环科技自主研发的高性能分布式分析型数据库,在PB级数据量上提供极致的数据分析能力。多模型数据库ArgoDB支持标准SQL语法、分布式事务和存算解耦,提供高并发高速数据写入、复杂查询、多模分析和数据联邦等能力。通过一个ArgoDB数据库,就可以打造离线数据仓库、实时数据仓库、数据集市和联邦计算平台等数据分析系统,提供全面、便捷、智能和安全的数据服务能力。
2021年6月信通院发布《数据库发展研究报告(2021年)》,报告指出数据库技术不断发展,向三个方向演进—易用性、性能和安全。ArgoDB 3.2重点围绕这三个方面进行迭代增强与优化升级并正式发布。
提升易用性、降低使用成本
原生支持大对象数据存储,增强多模型数据处理能力,满足更多“一库多用“场景
在后关系型数据库阶段,数据结构越来越灵活多样、业务类型越来越复杂多变,为应对此类现状,越来越多的用户选择通过多模型数据库实现“一库多用“,将各种类型的数据进行集中存储、查询和处理,满足对结构化、半结构化和非结构化数据的统一管理需求。
在已有的数据类型基础上,多模型数据库ArgoDB 3.2 原生支持大对象数据类型Blob和Clob,可以用来存储、查询和处理图片、电子文档、音频、视频等非结构化数据,满足了更多数据模型处理场景,简化系统架构、减少开发运维成本和提升用户体验,满足更多复杂业务需求。
以国内某三甲医院为例,经过十多年的信息化建设,该医院已经初步建立了HIS(医院信息系统)、LIS(实验室信息管理系统)、PACS(影像归档和通信系统)、电子病历等多套信息系统,并积累了大量的临床数据。除了结构化、半结构化数据,还有海量、高价值的医疗影像等非结构化数据。为了存储、查询和处理这些不同类型的数据,这些系统独立建设、缺乏集成、元数据不统一和标准不统一,给数据的查询和处理带来重重困难。为了解决这些问题,加速医院业务数字化发展,医院基于多模型数据库ArgoDB建设了临床数据中心底层大数据平台,将医院中各种类型的数据(例如电子病历、医疗影像、检验报告、生物样本和文献等)集中在ArgoDB中存储、查询和处理,并能够满足跨不同数据模型的复杂分析需求,从而充分发掘医疗数据的宝贵价值,最终提高医疗质量、降低医疗成本。
新增智能建表功能,简化建表流程,降低业务迁移成本
随着业务形态越来越复杂多样,在建表时如何设置参数使得数据查询和分析效率最大化成为一个问题。在业务迁移时,庞大的库表数量也需要耗费精力来配置参数。ArgoDB自主研发多模型数据库优化器Gluon,自研多种计算优化技术,在建表时可以通过设置一些参数来提升数据查询和分析效率。
为了在最大化数据查询和分析效率的同时简化建表流程,ArgoDB 3.2新增智能建表算法,在建表时能够自动设置参数,用户无需手动配置参数就能够体验ArgoDB的极致性能表现。在某集团业务迁移过程中,智能建表功能为数万张表自动配置合适的参数,帮助用户大大降低了业务迁移成本。
开箱即用的运维工具,新增两种典型场景监控,增强运维监控能力
随着数据量越来越多和业务越来越复杂,数据库运维管理人员面临的挑战也越来越大。为了帮助运维管理人员提升运维效率和降低运维成本,ArgoDB提供开箱即用的数据库运维工具,运维管理人员可以通过界面化的方式进行日常操作。
为了方便发现、定位和排查风险,ArgoDB3.2新增两种典型场景监控:小文件合并状态监控与数据分布状态监控,进一步丰富了监控指标,用户可以结合业务需求灵活地调整数据管理策略,从而保障数据库系统稳定、高效的运行。

高达7倍的性能提升
高达5倍的OLAP性能提升
面对业务形态多样、商业模式多变、需求变化频繁,如何在海量数据中高效完成数据分析,成为快速获取商业洞察的关键所在。ArgoDB 3.2针对OLAP场景做了许多性能优化工作并提升了性能表现,例如典型窗口函数计算场景性能可提升5倍;新增智能多表复杂Join算法,能够自动识别Join过程中的大小表,选择最佳的Join优化算法,从而提升Join效率。
存算解耦场景性能提升7倍
存算解耦是未来数据库架构演进的重要趋势。存算解耦,顾名思义就是存储引擎和计算引擎可以独立按需进行扩容和缩容,要多少计算扩容多少计算,要多少存储扩容多少存储,避免浪费,提高分析效率。例如星环数据云平台(TDC)可以利用ArgoDB存储和计算解耦合的特性,灵活合理地按需分配资源。
在存算解耦合场景中,计算任务与数据可能不在同一节点上,此时计算任务会远程读取非本地节点的数据并导致查询和分析性能下降。为了提升存算解耦合场景的查询和分析效率,ArgoDB3.2计算任务对非本地节点的数据读取性能提升了7倍。该优化增强了存算解耦场景下的性能表现,能够帮助用户更好地应对复杂多变的业务需求。
性能测试
TPC是全球最知名非盈利的数据管理系统评测基准标准化组织,TPC-H和TPC-DS是业界常用的性能测试基准之一,主要用于评测数据库的分析型查询能力。
在TPC-H 1T测试中,ArgoDB产品性能是ClickHouse的5.7倍。在TPC-DS 1T测试中,ArgoDB产品性能是Spark的1.6倍。
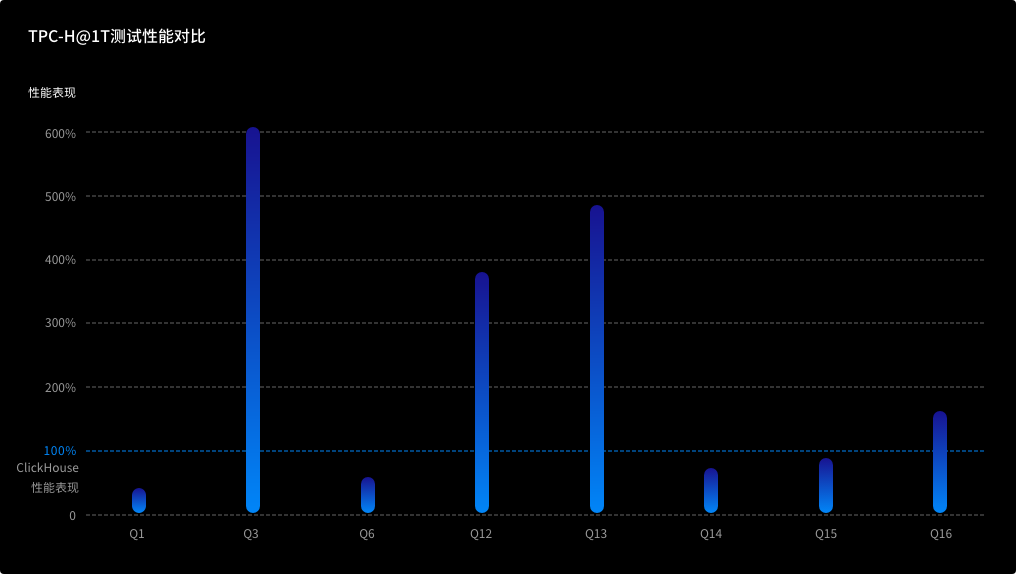
TPC-H 1T测试性能对比
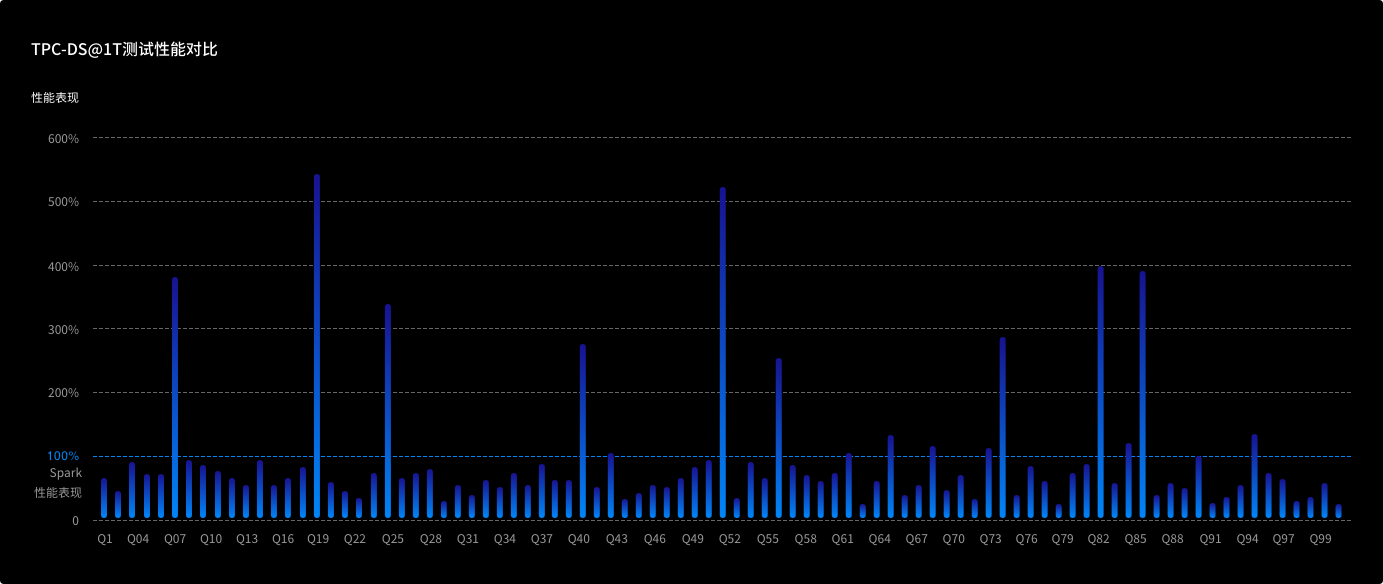
TPC-DS 1T测试性能对比
更多认证机制,保障数据安全
支持多种安全认证机制,灵活应对数据安全需求
2021,我国第一部关于数据安全的法律《中华人民共和国数据安全法》正式实施,如何做好数据安全建设成为各行业最为关注的问题之一。为了充分保障用户业务安全,ArgoDB提供完整的数据安全防护体系,包括用户识别,权限控制,安全审计,数据加密,数据脱敏、数据备份、容灾等。
为了满足更多场景的数据安全需求,ArgoDB3.2在Kerberos、LDAP、CAS等认证机制基础上,新增Oauth 2.0认证机制,提供更丰富的认证机制,帮助用户灵活应对不同场景的数据安全需求。
以上便是星环科技多模型数据库ArgoDB3.2特性介绍:便捷易用的产品体验,不断提升的性能表现,灵活强大的安全防护能力。未来,星环科技多模型数据库ArgoDB将继续坚持自主研发与技术创新,围绕易用性、产品性能、数据安全等方面不断打磨。在降低平台复杂性和IT总拥有成本的同时,让用户更全面、更便捷、更智能、更安全地运用数据。
典型案例
ArgoDB广泛应用于金融、政府、能源、交通、运营商等各行业。国家邮政局是副部级国家局单位,负责拟订邮政行业政策和规划,以及承担邮政(含快递公司)监管责任。为了推进邮政寄递渠道安全监管“绿盾“工程建设,国家邮政局基于星环实时流计算引擎Slipstream和分布式分析型数据库ArgoDB构建了实时邮政监管平台。平台为多个应用系统提供实时的数据采集、存储、查询和处理等服务,满足了离线业务、在线业务、即席查询、报表查询等需求,支持了7大业务板块,完成了对全国37家快递企业的实时监管。不同快递企业和电商平台的快递面单、电商数据等不同类型数据通过Slipstream流计算引擎实时写入ArgoDB,写入性能达到了数百万记录/秒,每天接入70亿业务数据,累计接入了PB级海量数据。在高并发高速写入数据时,通过分布式事务处理能力保证每天接入的70亿业务数据不丢失不重复,数据入库即可进行查询和分析。业务人员直接使用标准SQL和传统数据库方言进行复杂检索、统计和分析,降低了数据使用门槛,提升了业务效率。在业务高峰时,能够支撑数百名业务人员同时交互式复杂查询分析。
来源:https://www.transwarp.cn/product/argodb
这篇关于分布式分析型数据库:星环科技ArgoDB 3.2正式发布的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






