本文主要是介绍多维数据下的业绩爆发潜力,每家门店都要进行数字化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

“你的门店近期运营情况如何?”
面对这个问题,最直接的回答是门店营收数字。但如果再深入一步询问:这个月业绩增长或下滑是出于什么原因?有哪些数据支撑你的判断?恐怕很多人未必能够拿出切实可靠的数据。
而如果再进一步,比如在诸如「进店人次」等基础数据之外,给出更专业的进店转化漏斗、店内客流分布情况、顾客旅程图等,恐怕很多店长就「一问三不知」了。
优秀的运营者不满足于表面,而是从更丰富运营数据背后进行深入洞察,制定行之有效的策略,促成门店业绩提升。
他们手中的客流数据如同「杀手锏」,往往都有以下三个共同点,使其遥遥领先于同行门店:
多维、准确、可视化呈现。
在「帷幄数智空间 Whale SpaceSight」中,仅客流分析的关键运营数据维度就达 30+。这些数据由帷幄多年来与上千家标杆品牌合作过程中,不断从真实的运营场景中提炼而来,极具实战价值。
01
掌握门店客流,这些关键数据必不可少
门店客流分析通常包括三个方面:「出入口客流」「店内客流」和「全店客流」。
出入口客流分析的数据维度,除了过店人次、关注人次、进店人次、进店率等基础数据,还包括了进店顾客基础画像分布等,你可以按性别、年龄段等对客群进行占比分析。
出入口客流数据体现着门店争取顾客的能力。你的门店真正做到了因地制宜、因时制宜地尽力吸引顾客了吗?在以上基础数据之外,你需要进一步展开更具经营参考价值的分析,来拉开与竞争者的差距。
这些分析维度,包括进店转化漏斗、各周期分时段趋势对比、不同门店均值对比、周末非周末对比、节假日对比、营销节日对比、气候对比等。
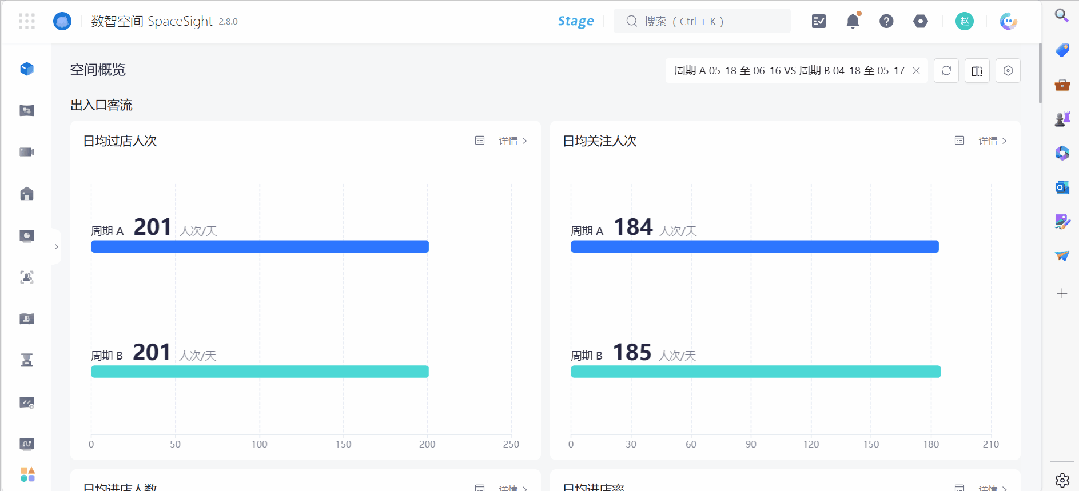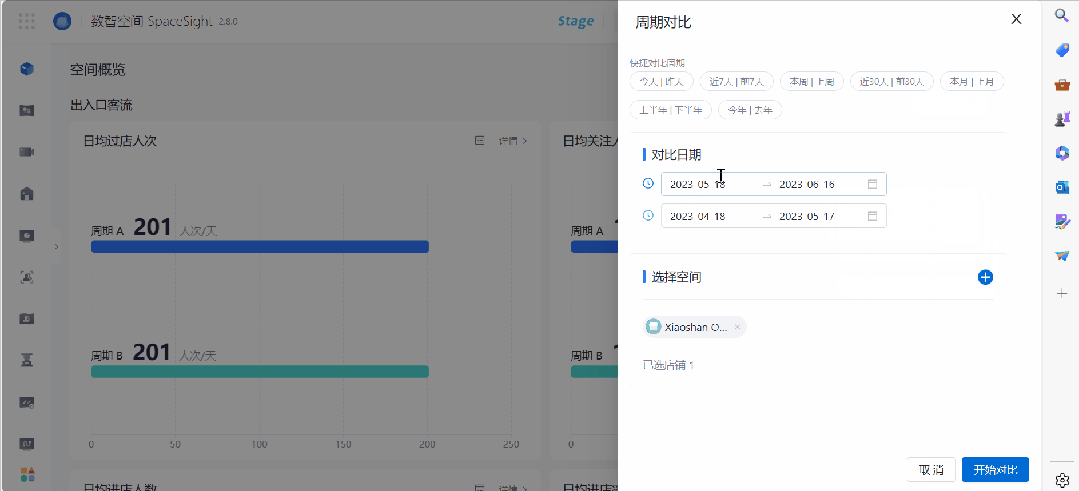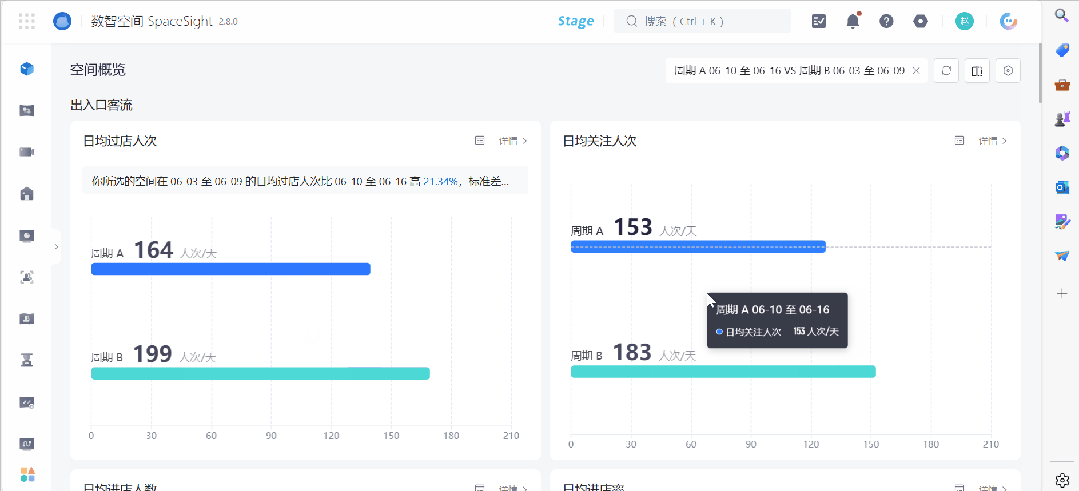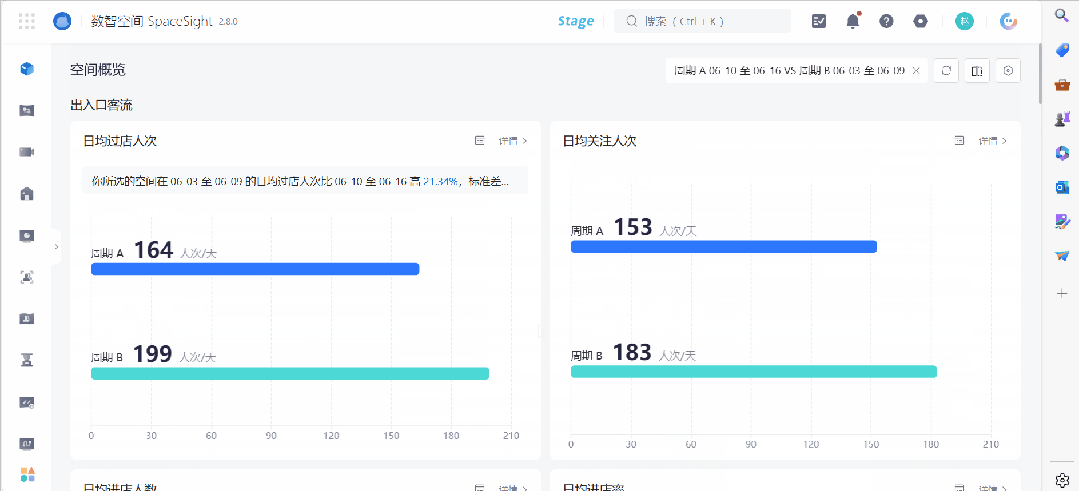
这里既有动态趋势,也有不同维度下的数据对比。通过控制变量展开高级对比,店长及总部运营人员可以更有效识别不同因素对门店业绩的影响力,从而更加灵活地调整策略。
例如,品牌旗下门店在去年不同节假日、促销节日的销售表现如何,运营人员可以自定义这些时段进行对比,并结合销售图表分析,决定今年营销关键节点如何设置。
此外,十一假期不同门店表现如何?同一家门店,在调整促销策略后,出入口客流与此前有何不同?针对这些实际的运营分析需求,品牌都可以进行自定义对比。
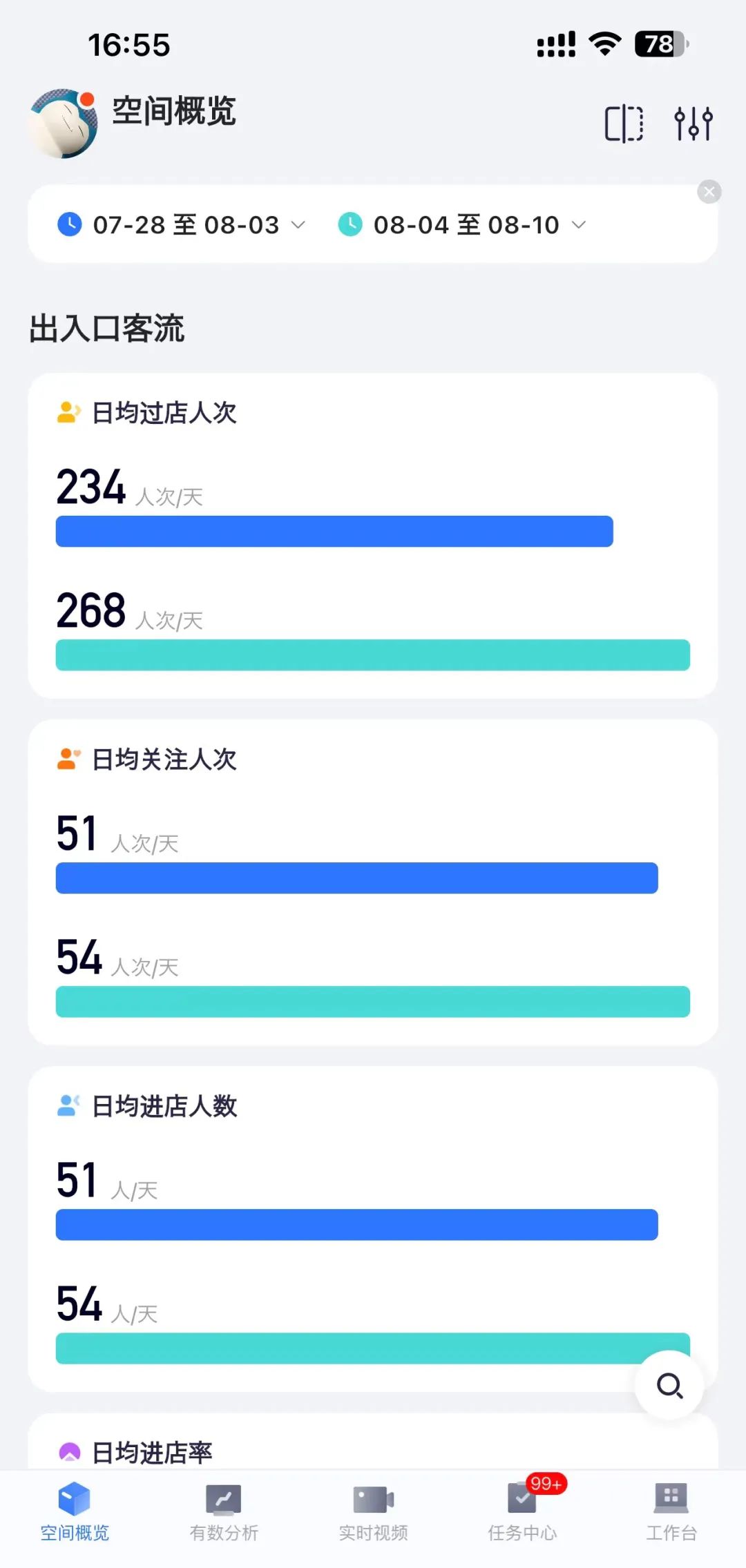
店内客流分析同样需要多维的、精细化的数据,包括实时店内人数、人均逛店时长、人均逛店深度、深访率等。此外是更多复合型、动态数据,例如人均逛店时长和深度的分时段趋势、不同性别及年龄段访客的逛店深度对比。
顾客在店内哪些区域长时间驻留?哪些区域的顾客流失率更高?顾客通常会按照怎样的路径逛店?顾客折返率多高?如果说店内人数多少尚且可以直观感知到,那么以上这些数据则难以感知,却对门店盈亏起着至关重要的作用。
这是因为,门店的货架和商品陈列方案通常会根据季节、产品发布规划、促销方案、消费人群特性等因素进行精心设计。好的设计能够给顾客营造一个满意的逛店环境、激发顾客的购买欲;不理想的设计却会导致顾客体验差,大量流失,或是一些重要区域未被逛到,致使品牌系统的营销方案折戟在最后的门店转化环节。
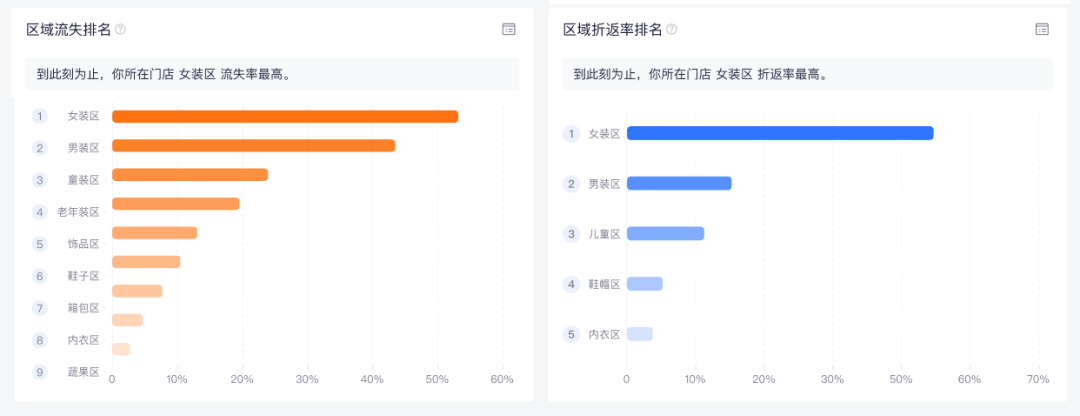
全店客流包括客流分布图、客流动线图、区域关注图、区域关系图、顾客旅程图等,从顾客过店到最终转化这一过程的更加系统全面的数据统计与分析,帮助品牌俯瞰全局,把控门店运营策略整体方向。
多维数据建立后,公司即可通过了解各门店的客流数据变化来优化门店运营。不过,当门店众多时,如果对每家门店都一一检视,需要耗费大量精力。
通过 SpaceSight 中的标签系统,尤其是「动态标签」,即可轻松解决这一问题。
所谓动态标签,即系统根据设定好的条件来动态计算并进行打标。包括天气标签、客流进店标签、人群画像标签等。
通过使用动态标签,品牌不仅可以一键掌握各门店的属性,还可以优化查找门店的步骤。
例如,你可以按照实际运营需求,设置如下规则:给近 7 天进店率小于 10% 的门店打标「进店转化率低」,或给近 7 天进店女性比例大于 60% 的门店打标「女顾客占比高」。接下来,SpaceSight 就会自动为符合条件的门店进行打标。
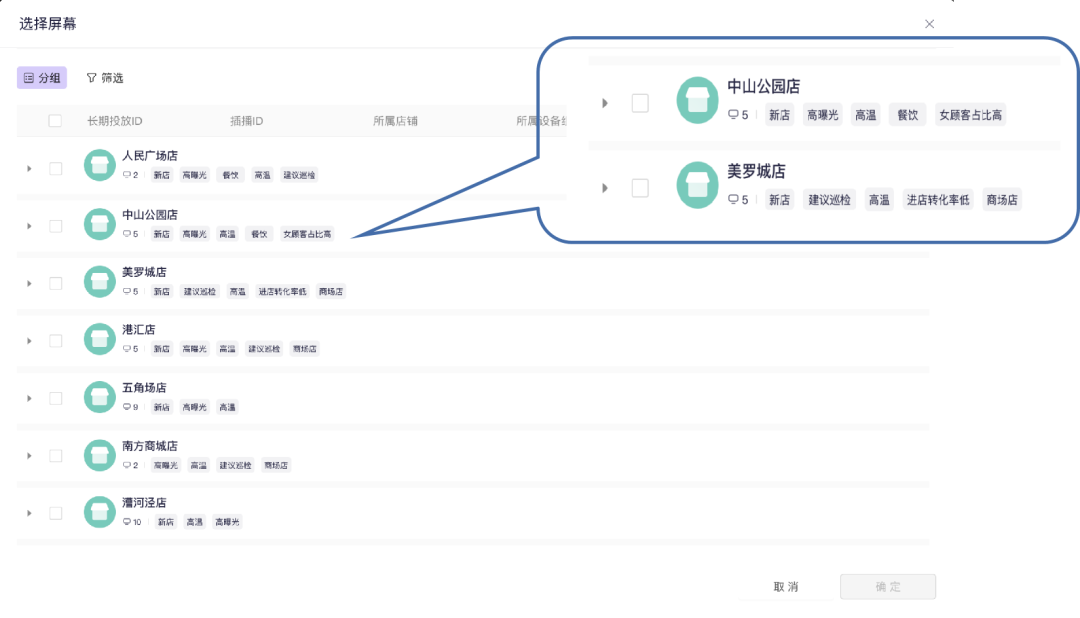
之后,当运营人员需要查找此类门店时,只需筛选相关标签,即可快速找到,从而快速指导这些门店进行运营调整。
02
精准、可视化的数据,让客流分析充分发挥价值
有了多维数据的支撑,我们还需要确保客流数据足够准确,以使其真正「有用」;同时,多维的数据需要清晰简单的可视化呈现,以使其用起来足够「简单方便」。
某汽车品牌总部运营总监 Ken 发现,近期门店、商场展厅的进店客户较多,但留资、成单的客户却不多。经过分析发现,除了「分子」方面销售服务质量有待提升外,另一个原因是:不少「伪客流」被统计进来,导致「分母」过大。
例如,一些所谓的客流其实是店内员工、保洁人员,甚至外卖员,而无论是员工还是顾客,重复进店时会被反复统计。这导致客流统计数据与实际情况出入很大。
准确率太低导致数据失去参考意义,要人工去重又费时费力。而通过 SpaceSight,Ken 即可轻松解决这一烦恼。
SpaceSight 不仅可以有效对店内员工等非顾客人员及重复进店情况进行过滤和去重,同时,你还可以设置停留时长过滤,对于穿行过店、进店问路、进店时长过短等无效客流进行过滤,从而获取有效客流。
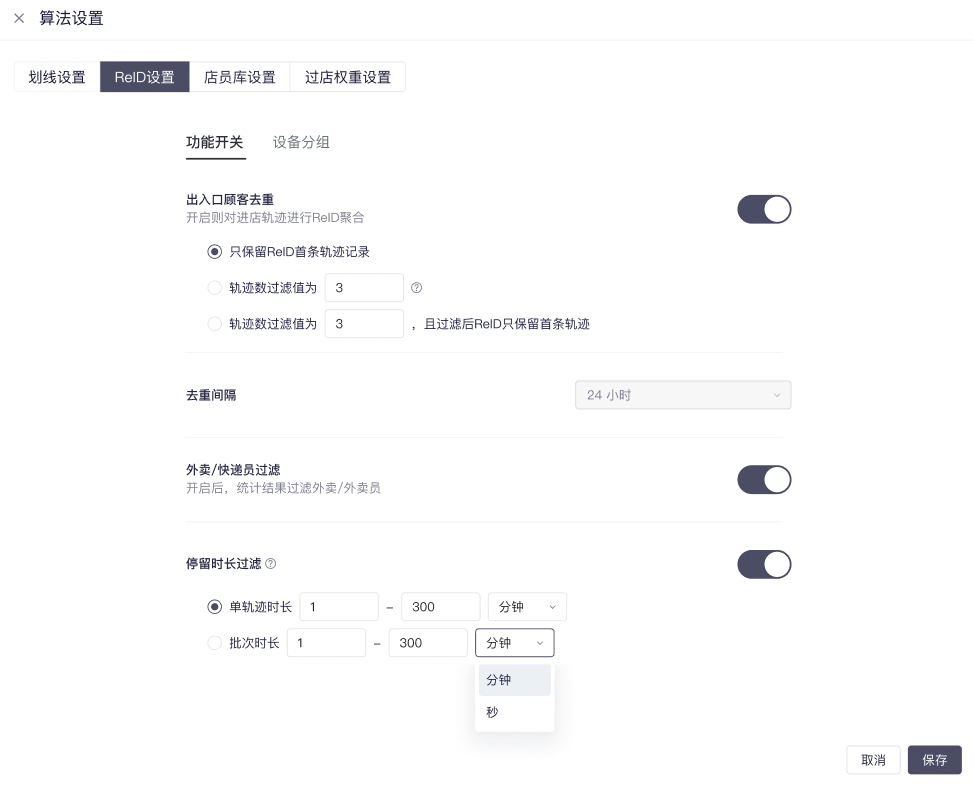
这样一来,店长就可以根据精准客流数据,更有效地复盘分析门店情况、考核店员日常工作、调整排班与销售接待策略,工作大大效率。
数据不仅要多维和准确,还要一目了然。
SpaceSight 不仅在电脑端充分做到了可视化分析,同时创新的「灵动卡片」让手机端交互也同样简单易用。
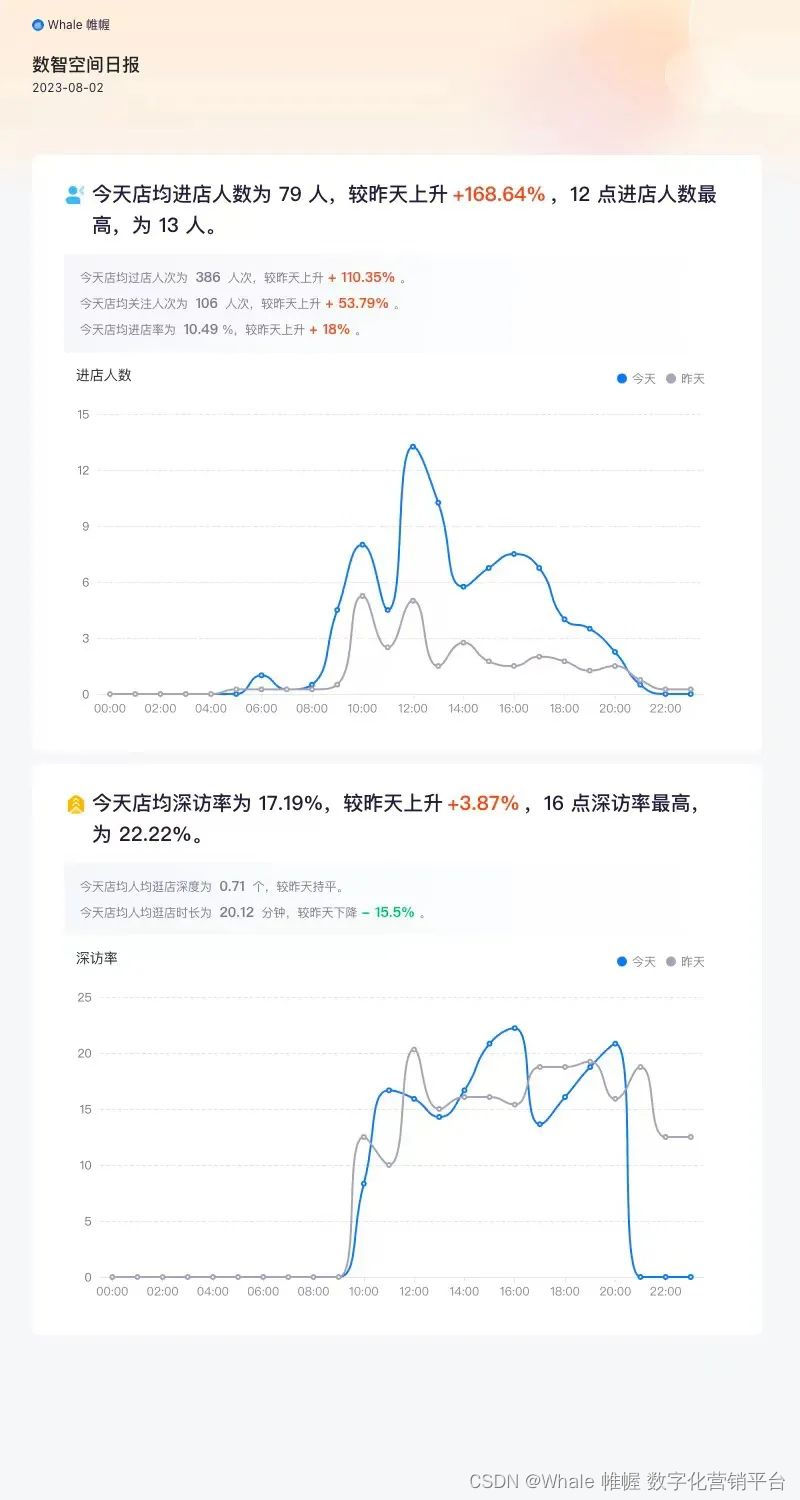
50+ 指标、10+ 类看板,门店运营全链路覆盖。无论何时何地,你都可以在指尖轻松概览门店运营全局。

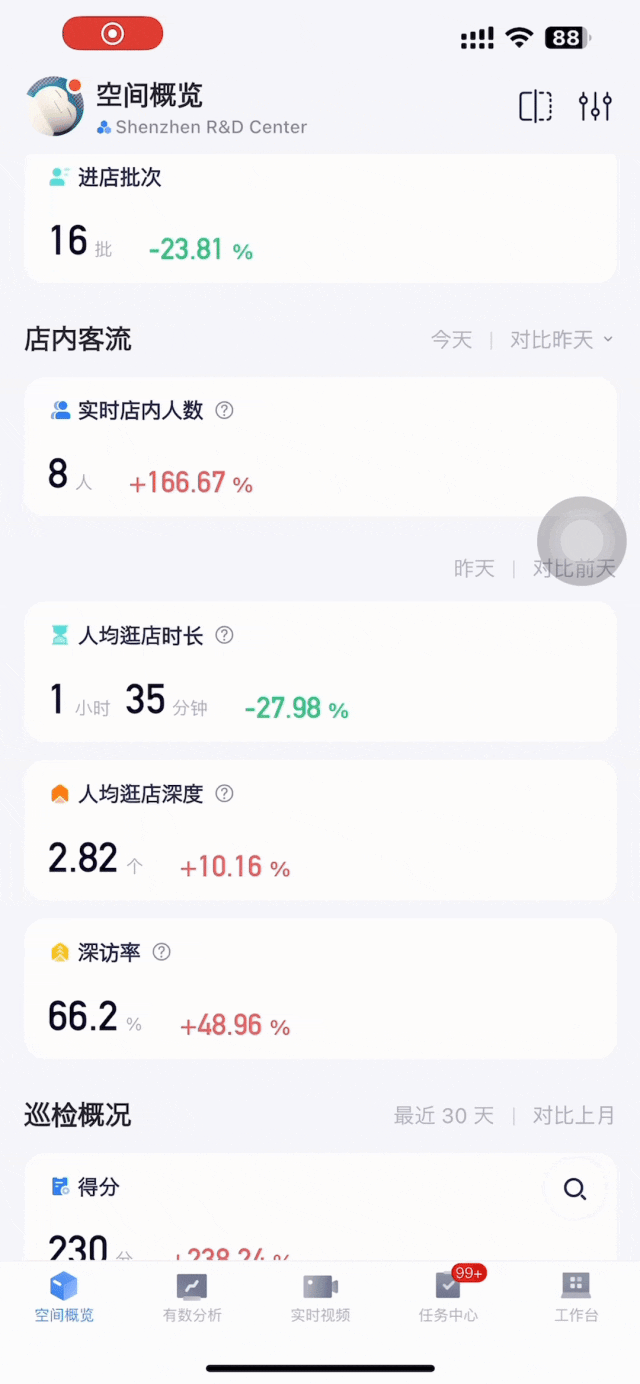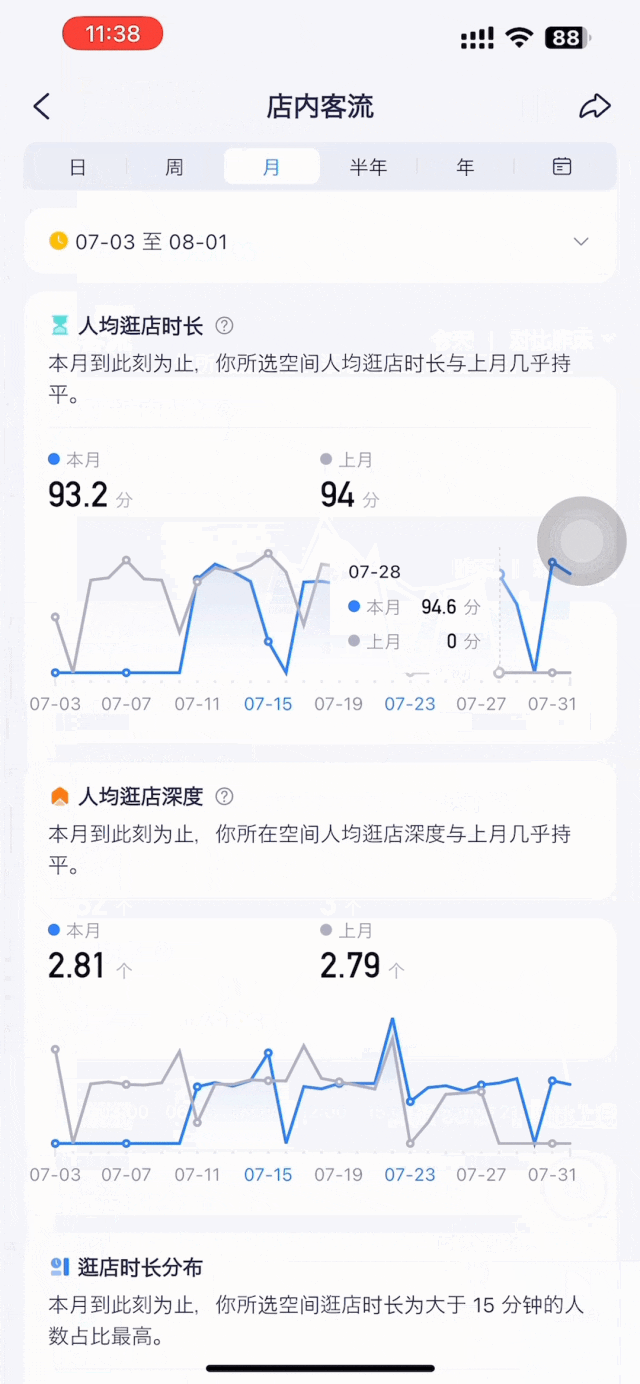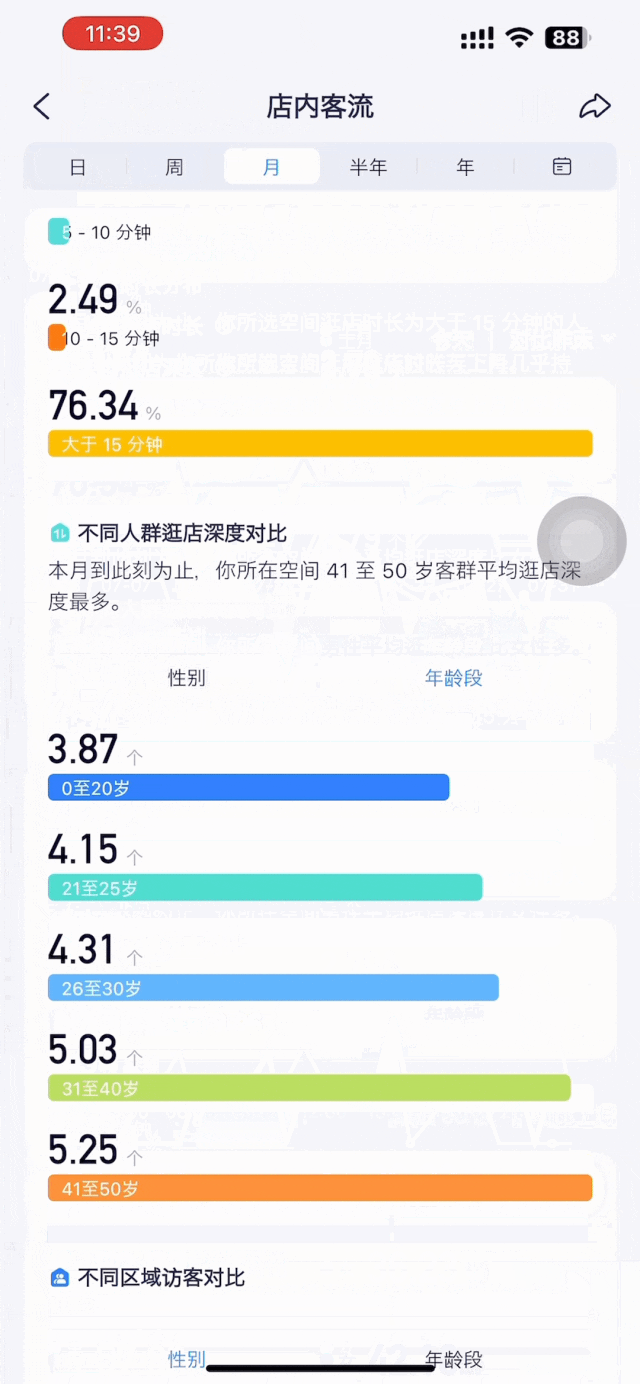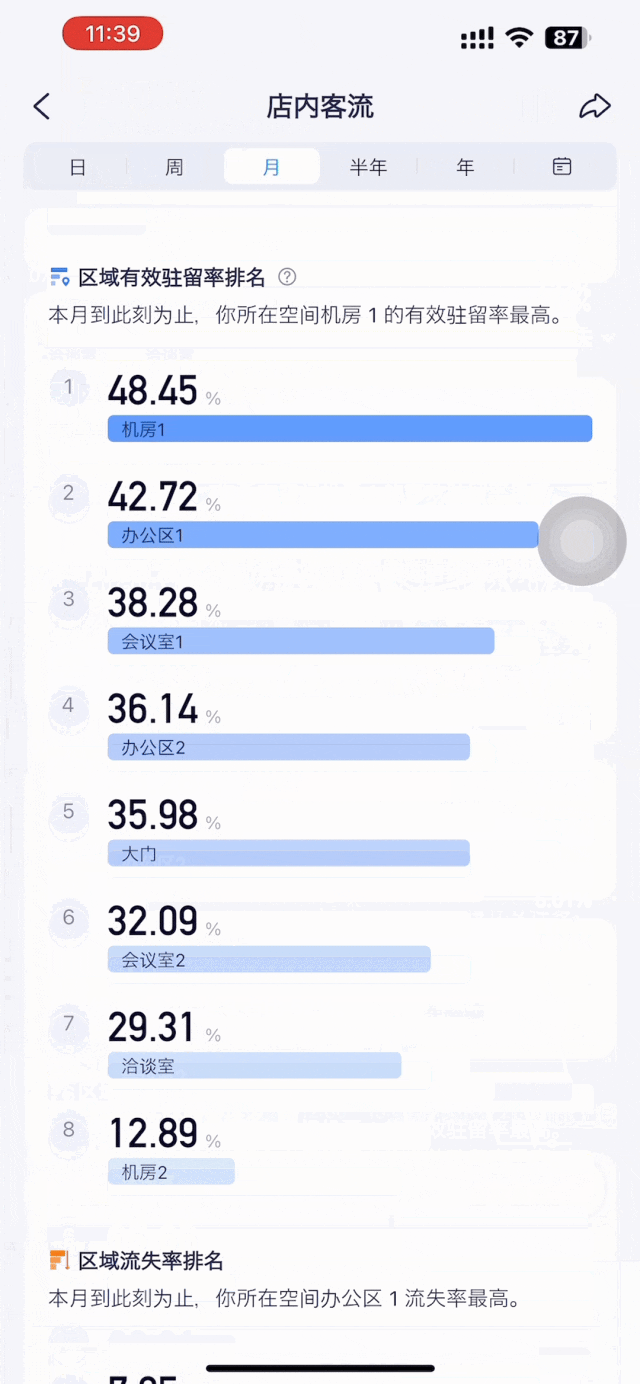
决策者需要的,不是繁琐复杂的原始数据,而是对数据的总结提炼,以方便洞察。这正是数据可视化呈现的核心价值之一。
有没有什么办法在以上基础上再进一步?比如,某运营人员近期打算重点关注品牌旗下特定的几个门店,希望关于这些门店的数据可以按时自动发送到自己手中?
当然可以。在 SpaceSight 中,你可以自定义订阅数据报告。无论是日报、周报还是月报,相关门店的数据报告均可按你所需定时推送给你。当需要团队协同时,则可以下载报告,分享给需要同事。
灵活、简单、高效协同,这是数据报告带来的核心价值,就像一个称职的助理,随时将门店运营情况以精炼、清晰的方式汇报给你。
结语
多维、准确、可视化的数据,支撑起了高效的门店运营决策。作为 AI 驱动的门店标准化运营及数据分析系统,SpaceSight 深挖门店数据,追踪客流全生命周期,全域数据直观呈现,数据报告自动推送,让运营决策更轻松、更高效,实现可复制的门店增长。
这篇关于多维数据下的业绩爆发潜力,每家门店都要进行数字化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






