本文主要是介绍存储压测工具— — Cosbench教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
存储压测工具— — Cosbench教程
Cosbench是Intel团队基于java开发,对云存储的测试工具,全称是Cloud object Storage Bench,本文主要针对的是支持aws-s3协议的存储服务进行测试,包括seaweedfs、以及华为云存储。
1 安装
github地址:https://github.com/intel-cloud/cosbench
本文讲解的是0.4.2.c4版本,大家可以根据自己的需求去下载github上的相应的release版本。
- 本文所说的cosbench的下载地址: https://github.com/intel-cloud/cosbench/releases/download/v0.4.2.c4/0.4.2.c4.zip
注意:
cosbench是基于java开发的,因此本地需要有java环境
# 安装 curl
yum install -y curl
# 安装 nc
yum install -y nmap-ncat
# 安装 openjdk
yum install -y java-1.8.0-openjdk
下载后解压:
脚本功能说明:
- start-all.sh\stop-all.sh:在当前节点上启动\停止contronller、driver
- start-controller.sh\stop-controller.sh:在当前节点上启动\停止contronller
- start-driver.sh\stop-driver.sh:在当前节点上启动\停止driver
- cli.sh:命令行客户端
2 运行
2.1 单节点运行
直接启动目录下的start-all.sh会在当前节点同时运行driver和controller,并通过如下命令检测是否已经启动。
$ netstat -an |grep LISTEN| grep 19088
tcp 0 0 :::19088 :::* LISTEN
$ netstat -an |grep LISTEN| grep 18088
tcp 0 0 :::18088 :::* LISTEN

运行成功之后直接在浏览器上输入:
http://localhost:19088/controller/index.html
即可访问到页面
2.2 多driver运行
controller 的配置文件为 conf/controller.conf,主要内容如下:
[controller]
drivers = 1
concurrency = 4
log_level = INFO
log_file = log/system.log
archive_dir = archive[driver1]
name = driver1
url = http://driver_url:driver_port/driver
其中 controller下drivers指定driver的数目,concurrency指定可以同时运行的任务个数
[driver << n >>]是driver的设置信息,其中n为递增整数,driver配置时必须要是这种格式,否则不会生效
在controller中配置好driver信息后,在对应的机器上启动driver即可,driver启动命令如下:
start-driver.sh < driver个数 > < ip > <起始端口>,例如: start-driver.sh 4 10.252.1.111 18088
其中若有多个worker时,woker的监听端口没以100为单元递增,driver启动后再启动controller整个系统即启动完成
3 XML文件编写
3.1 标准格式
<?xml version="1.0" encoding="UTF-8" ?>
<workload name="s3-sample" description="sample benchmark for s3"><!--s3服务地址及认证信息配置ak、sk、endpoint等--><storage type="s3" config="accesskey=<accesskey>;secretkey=<scretkey>;proxyhost=<proxyhost>;proxyport=<proxyport>;endpoint=<endpoint>" /><workflow><workstage name="init"><!--init 任务阶段 创建一个bucket两个bucket,桶名前缀为s3testqwer--><work type="init" workers="1" config="cprefix=s3testqwer;containers=r(1,2)" /></workstage><workstage name="prepare"><!--prepare 任务阶段 在init创建的桶里创建10个object 大小为64kb--><work type="prepare" workers="1" config="cprefix=s3testqwer;containers=r(1,2);objects=r(1,10);sizes=c(64)KB" /></workstage><workstage name="main"><!--main 任务执行阶段执行mainwork runtime:多长时间后执行任务 workers: 同时执行任务的worker数--><work name="main" workers="8" runtime="30"><!--operation为执行的具体操作 ratio为该操作占用总操作的比例--><operation type="read" ratio="80" config="cprefix=s3testqwer;containers=u(1,2);objects=u(1,10)" /><operation type="write" ratio="20" config="cprefix=s3testqwer;containers=u(1,2);objects=u(11,20);sizes=c(64)KB" /></work></workstage><workstage name="cleanup"><!--cleanup 任务阶段 删除任务执行时创建的object--><work type="cleanup" workers="1" config="cprefix=s3testqwer;containers=r(1,2);objects=r(1,20)" /></workstage><workstage name="dispose"><!--dispose 任务阶段 清理调为该任务创建的桶--><work type="dispose" workers="1" config="cprefix=s3testqwer;containers=r(1,2)" /></workstage></workflow>
</workload>
3.2 造数据
如果我们是通过cosbench造数据,那么可以省略掉后面的main、cleanup、dispose等步骤
例如:给30.16.13.137:8060环境下造两个桶,桶名prefix为s3testqwer
objects=r(1,10);sizes=c(64)KB
- 指定桶里对象有10个,文件大小为64KB
<?xml version="1.0" encoding="UTF-8" ?>
<workload name="s3-sample" description="sample benchmark for s3"><storage type="s3" config="accesskey=9fadssca999fadsfvzx;secretkey=99kfasodu0321r203safdsfa9;endpoint=http://30.16.13.137:8060" /><workflow><workstage name="init"><work type="init" workers="1" config="cprefix=s3testqwer;containers=r(1,2)" /></workstage><workstage name="prepare"><work type="prepare" workers="1" config="cprefix=s3testqwer;containers=r(1,2);objects=r(1,10);sizes=c(64)KB" /></workstage></workflow>
</workload>
4 提交任务
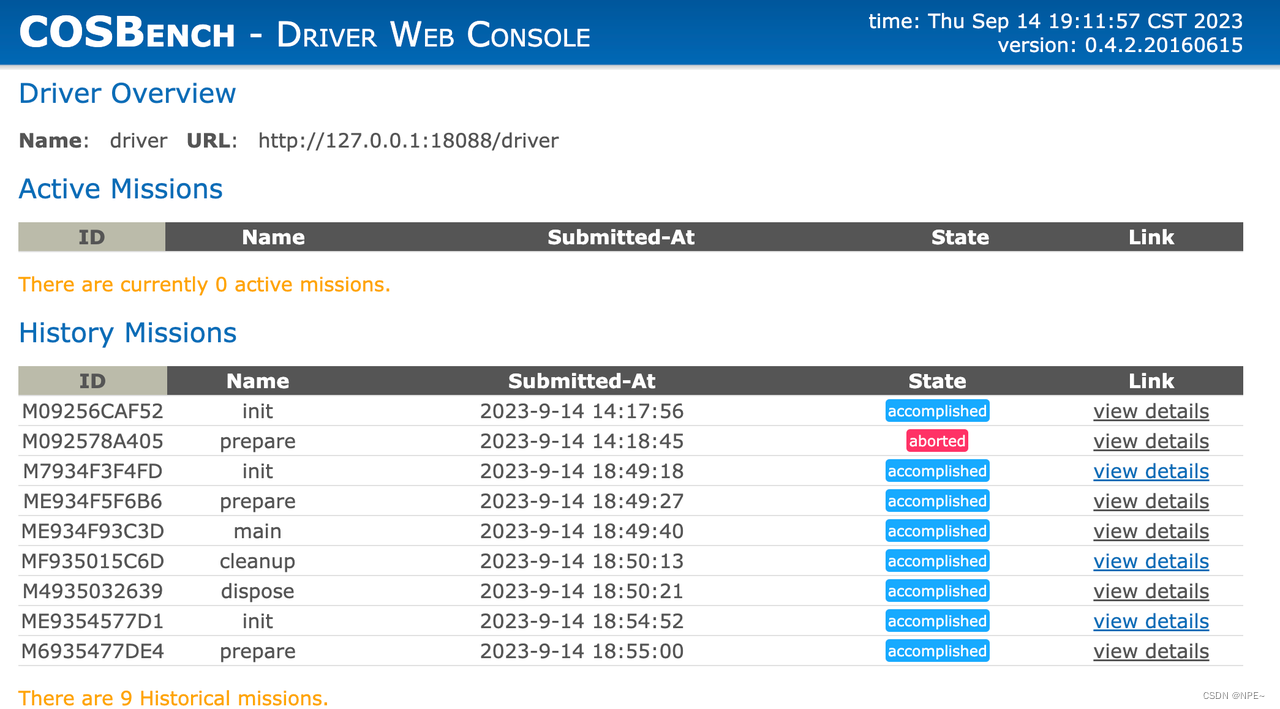
执行sh cli.sh submit conf/s3-config-sample.xml或者在controller页面手动上传任务配置
http://127.0.0.1:18088/driver/index.html可以查看到所有的任务及对应状态,界面如下:
这篇关于存储压测工具— — Cosbench教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







