本文主要是介绍Kubernetes组件_Scheduler_01_将Pod指派给Node的四种方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、前言
- 二、Scheduler调度
- 2.1 默认调度方式
- 2.1.1 架构和流程
- 2.1.2 开发实践:设置好request和limit
- 2.2 节点node上的标签属性
- 2.3 节点node上的污点属性
- 污点命令操作
- 实践:去掉主节点的污点
- 2.4 Yaml文件中的容忍属性
- 2.5 节点上的Unschedulable属性
- 2.6 小结
- 三、将Pod指派给node的四种方式
- 3.1 直接指定
- 3.1.1 nodeName 和 nodeSelector
- 3.1.2 实践:实现 pod 独占 node (nodeName + Taint + Tolerations)
- 3.2 亲和性和反亲和性
- 3.2.1 node亲和性:让其他pod 强制调度/优先调度 到这个node上
- required 硬性限制
- preferred 软性限制
- 小结:各个属性的含义
- 3.2.2 node反亲和性:让其他pod 强制不要调度/优先不要调度 到这个node上
- required硬性限制
- preferred 软件限制
- 小结:各个属性的含义
- 3.2.3 pod亲和性:让其他pod优先调度到有一个pod的node上(至少要有两个节点,才能完成测试)
- required硬性限制
- preferred软性限制
- 3.2.4 pod反亲和性(pod多于node情况下,可以保证每个node只有一个pod)
- required硬性限制
- preferred软性限制
- 3.3 拓扑方式 (各个node节点平均分配pod) v1.19才引入
- 四、尾声
一、前言
Scheduler本质是Kubernetes中的一个静态Pod,在 kube-system 命令空间里面。
Scheduler作用:决定哪个Pod被调度到哪个Node上。
官网 :https://kubernetes.io/docs/concepts/scheduling/kube-scheduler/ ,如下:
通过调度算法,为待调度Pod列表的每个Pod,从Node列表中选择一个最合适的Node。
然后,目标节点上的kubelet通过API Server监听到Kubernetes Scheduler产生的Pod绑定事件,获取对应的Pod清单,下载Image镜像,并启动容器。
二、Scheduler调度
2.1 默认调度方式
官方博客:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/kube-scheduler/
定义:在 Kubernetes 中,调度 是指将 Pod 放置到合适的节点上,以便对应节点上的 Kubelet 能够运行这些 Pod。
2.1.1 架构和流程
架构图
In Kubernetes, scheduling refers to making sure that Pods are matched to Nodes so that Kubelet can run them
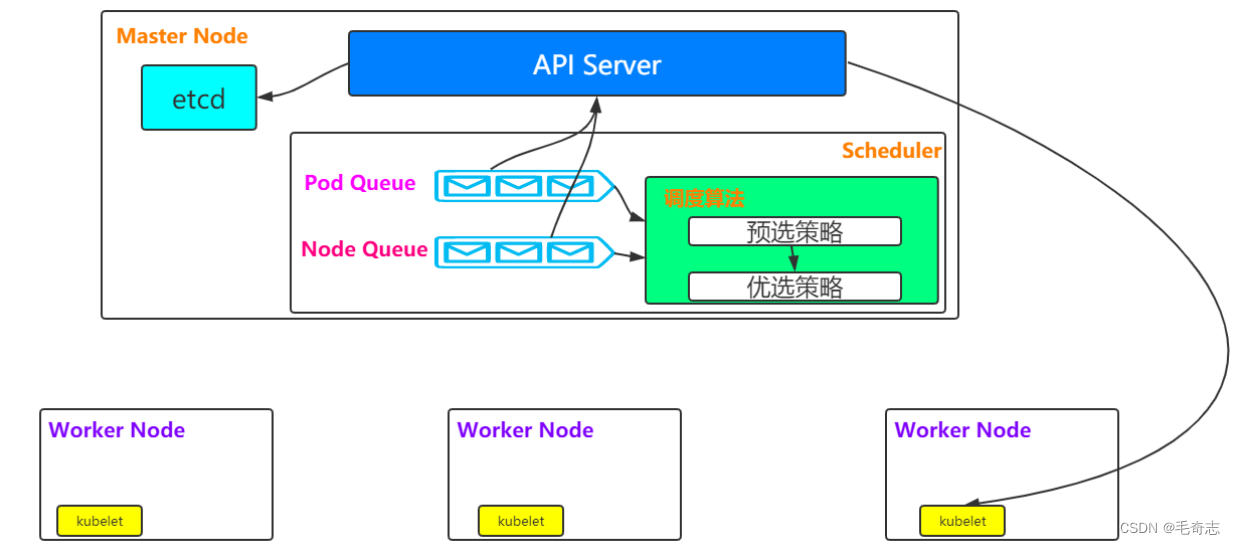
流程描述
https://kubernetes.io/docs/concepts/scheduling/kube-scheduler/#kube-scheduler-implementation
(1)预选调度策略:遍历所有目标Node,刷选出符合Pod要求的候选节点(https://kubernetes.io/docs/concepts/scheduling/kube-scheduler/#filtering
),涉及的包括 PodFitsHostPorts、PodFitsHost、PodFitsResources
(2)优选调度策略:在(1)的基础上,采用优选策略算法计算出每个候选节点的积分,积分最高者胜出
,涉及的包括SelectorSpreadPriority、InterPodAffinityPriority
2.1.2 开发实践:设置好request和limit
默认调度方式要设置好request和limit,避免大量pod分布到同一个node上
(1) yaml 文件中最好声明好 cpu 和 memory 的 request下限 和 limit 上限,这样 scheduler 调度的时候,防止所有的都到同一个 node 上,出现 OOM out of memory 导致 Pending Memory sufficient 或者 关机 (last reboot)
(2) request和limit设置为同样大小,而且比打成镜像的 springboot 的 jvm xmx 还大一些(一般在start.sh脚本里设置的),内存就大 500m,cpu 就大 0.5 个,这是以为 空Pod自身也是会有一些开销的,后面的博客会讲到。
2.2 节点node上的标签属性
给节点打标签
kubectl label node xxx project=k8snew
node/192.168.1.97 labeled
查看节点上的标签
kubectl describe node xxx
删掉指定节点上的指定标签
kubectl label nodes xxx project-
删掉所有节点上的指定标签
kubectl label nodes --all project-
2.3 节点node上的污点属性
污点命令操作
添加污点的方式:kubectl taint nodes node1 key=value:NoSchedule
删除污点的方式:
kubectl taint nodes node1 key:NoSchedule- 指定节点
kubectl taint nodes --all key:NoSchedule- 全部节点
查看污点的方式:kubectl describe node node-name | grep taint
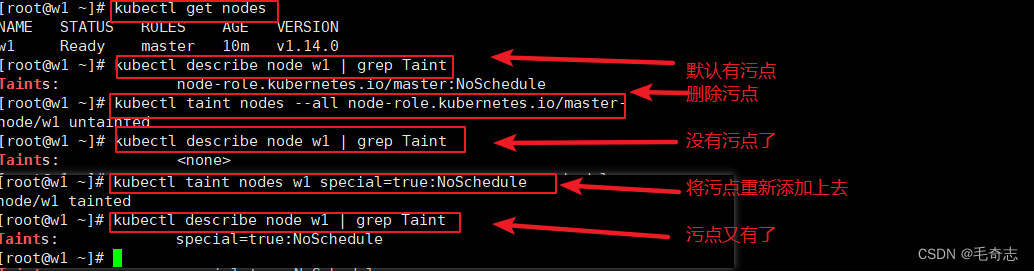
实践:去掉主节点的污点
使用kubeadm安装的集群,默认主节点是有污点的,不允许主节点分配pod,我们就拿这个 key value 练手
## 查看节点
kubectl get nodes## 查看污点(有污点) (是grep Taint ,不是grep taint,别搞错了)
kubectl describe node w1 | grep Taint## 去除污点 (返回值 node/w1 untainted)
kubectl taint nodes --all node-role.kubernetes.io/master-## 查看污点(没有污点了)
kubectl describe node w1 | grep Taint## 重新加上污点 (返回值 node/w1 tainted)
kubectl taint nodes w1 special=true:NoSchedule ## 查看污点(又有污点了)
kubectl describe node w1 | grep Taint## 删除污点
kubectl taint nodes --all special:NoSchedule-

2.4 Yaml文件中的容忍属性
容忍tolerations两种写法:
tolerations:
- key: "key1"operator: "Equal"value: "value1"effect: "NoSchedule"
等效
tolerations:
- key: "key1"operator: "Exists"effect: "NoSchedule"
无论是污点还是容忍,都是涉及到 key value effect 三个属性:key value可以理解,都是自定义的,都是用来 selector-label 标签选择器的,但是 NoSchedule 这个关键字需要学习一下,与污点有关的关键字都学习一下
这个值 NoSchedule 被称为 effect (在yaml的容忍里面可以看到),就是当匹配上这个 selector - label 需要执行的操作,常见的 effect 有三个值:NoSchedule 、PreferNoSchedule 、NoExecute
NoExecute :最强,如果Pod尚未被分配到node上,在没有添加容忍的情况下,不会被分配到这个node上;如果Pod已经被分配到这个node上,在指定时间之后,会被从这个node上驱逐
NoSchedule:次之,如果Pod尚未被分配到node上,在没有添加容忍的情况下,不会被分配到这个node上;如果Pod已经被分配到这个node上,不会被从这个node上驱逐
PreferNoSchedule :最弱,如果Pod尚未被分配到node上,在没有添加容忍的情况下,不会优先被分配到这个node上;如果Pod已经被分配到这个node上,不会被从这个node上驱逐
官网截图(链接:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/taint-and-toleration/):

好了,污点和容忍的知识学习完了
2.5 节点上的Unschedulable属性
tolerations 是 yaml 文件中的一个属性,Taint 是 Node节点的一个属性,相同点和都和Scheduler相关,影响到将哪个pod被调度到node上
问题1:想要分配到主节点
解决1:要么主节点去掉污点 ,要么给pod yaml 配置容忍,两种居其一就好
问题2:想不要分配到主节点
解决2:同时满足 “保持默认主节点保留污点” 并且 “保持默认 yaml 中不配置容忍”,这可以保证pod一定分配不到主节点
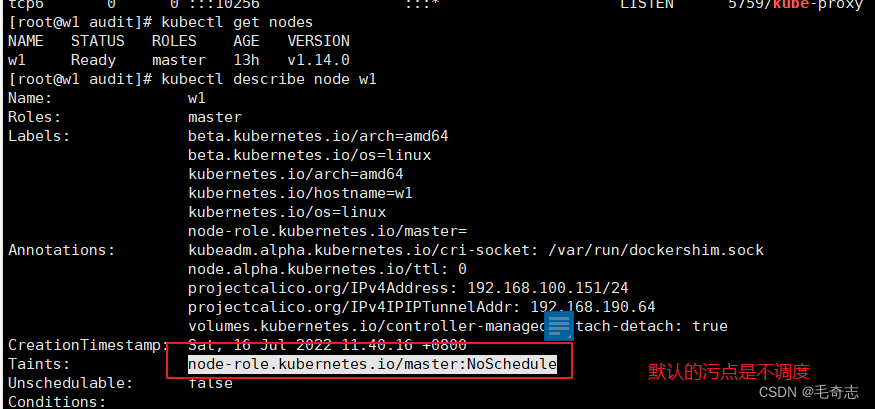
还没有学习完,再看节点上的一个 Unschedulable属性,默认是为false,但是有时候为true,导致这个节点上无法部署pod,而且使用普通 kubectl taint nodes node1 key:NoSchedule- 方式无法去除这种污点,开始。
执行 kubectl get nodes -o wide 这条命名,一般都是Ready或者NotReady,但是有的时候会看到node中出现UnSchedulable错误。

两个开发技巧:
kubectl get nodes 变成 kubectl get nodes -o wide,多了 -o wide,这样可以看到每个节点的内网ip
kubectl get pod 变成 kubectl get pod -o wide ,多了一个 -o wide,这样可以看到每个pod被调度到哪个node上
报错如下:kubectl describe pod pod-name -n ns-name 看到错误是 were unschedulable,kubectl get nodes看到唯一的 w1 节点是 SchedulingDisabled 错误,然后 kubectl describe nodes w1 看到 Taints
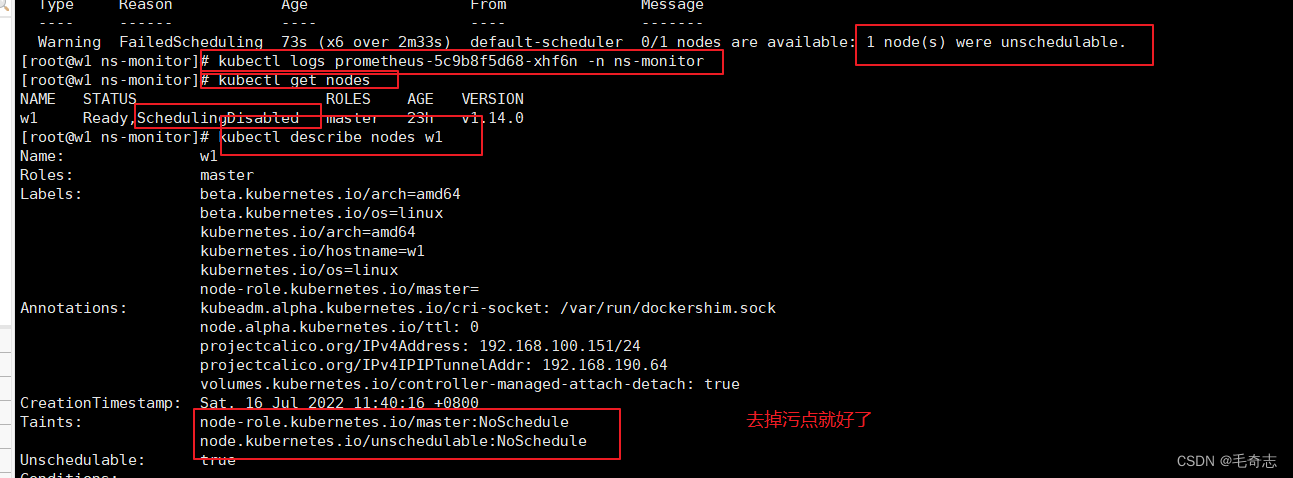
解决方案两句
# 步骤1:删掉所有节点 上的 key 为 node-role.kubernetes.io/master 的
kubectl taint nodes --all node-role.kubernetes.io/master-
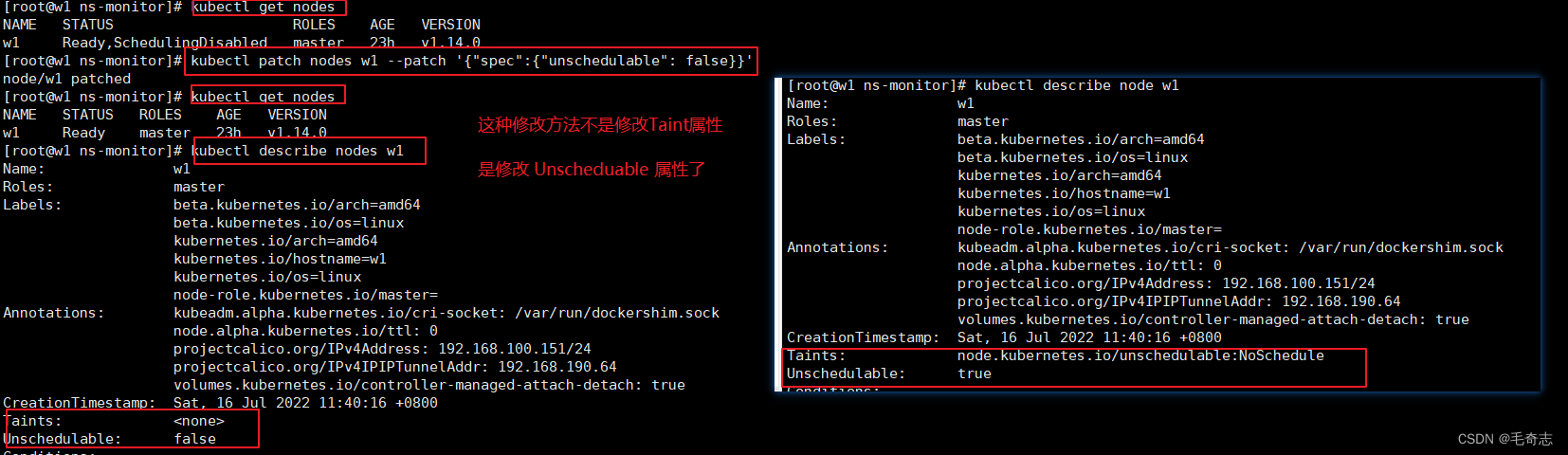
# 步骤2:修改(即patch)
kubectl patch nodes w1 --patch '{"spec":{"unschedulable": false}}'
第一步,执行 kubectl taint nodes --all node-role.kubernetes.io/master- 去掉污点
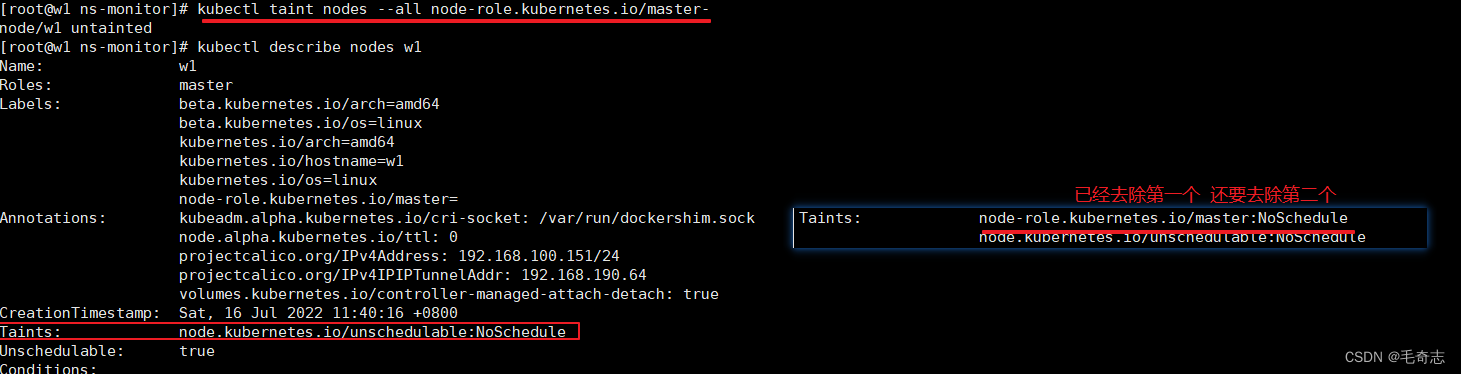
去掉了一个污点,还有一个污点,且Unschedule 仍然为true
第二步,执行 kubectl patch nodes w1 --patch '{"spec":{"unschedulable": false}}' 表示可以使用被调度
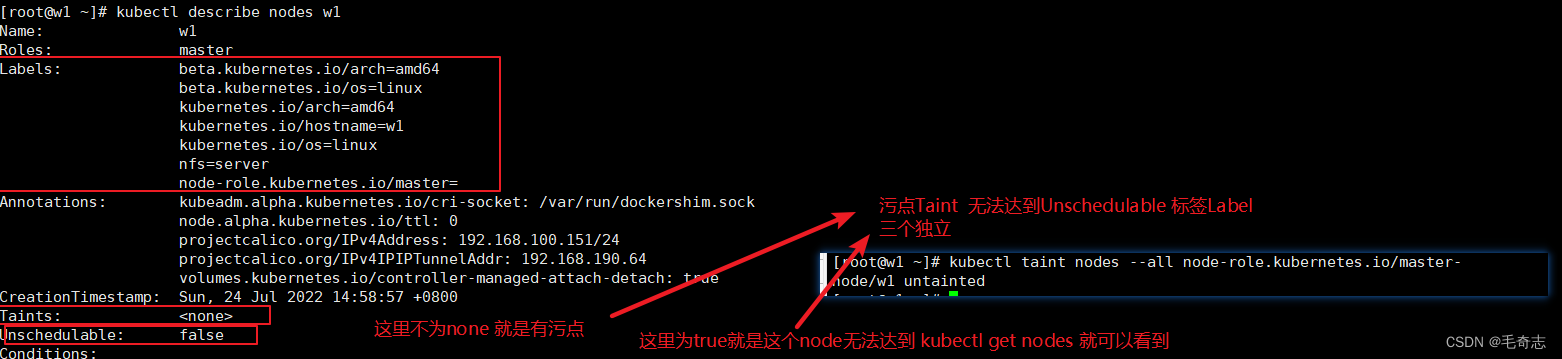
2.6 小结
与Scheduler调度相关的知识点:
在节点上的包括:三个属性: Labels Taint Unschedulable
在pod yaml上的包括:tolerations 容忍
节点,如下:三个属性:Labels Taint Unschedulable 都在红色框框里
kubectl describe node xxx 属性就可以看到
三、将Pod指派给node的四种方式
3.1 直接指定
3.1.1 nodeName 和 nodeSelector
nodeName(pod的yaml文件) = nodeSelect(pod的yaml文件) + label (kubectl 命令给 node 打标签)
yaml文件将pod调度到指定node节点,存在两种方案:
(1) Pod.spec.nodeName (deployment.template.spec.nodeName)
(2) Pod.spec.nodeSelector (deployment.template.spec.nodeSelector)
这两种方式都可以指定分配到当前pod yaml,分配到哪个node上。
Pod.spec.nodeName + node节点需要设置为对应名称 【直接选择节点名】
Pod.spec.nodeSelector + node节点需要设置为对应的label 【给节点打上标签+yaml里面添加nodeSelector选择器】
Pod.spec.nodeName将 Pod 直接调度到指定的 Node 节点上,其底层原理是:会跳过 Scheduler 的调度策略,该匹配规则是强制匹配,这种方式的缺点写成的 yaml 不具备模板的通用性(类似于绝对路径),因为每个集群的节点的名称是不同的(需要对节点重命名)。
apiVersion: apps/v1
kind: Deployment
metadata:name: myweb
spec:replicas: 3selector:matchLabels:app: mywebtemplate:metadata:labels:app: mywebspec:nodeName: node1 # 关键的代码在于这里 Pod.spec.nodeName (deployment.template.spec.nodeName)containers:- name: mywebimage: nginxports:- containerPort: 80
Pod.spec.nodeSelector:通过 kubernetes 的 label-selector 机制选择节点,底层原理是由调度器调度策略匹配 label,而后调度 Pod 到目标节点,该匹配规则属于强制约束,这种方式也不具备迁移性(需要对节点打标签)
# 先给节点node1打个标签
kubectl label nodes worker node1 key=web1
apiVersion: apps/v1
kind: Deployment
metadata:name: myweb
spec:replicas: 3selector:matchLabels:app: mywebtemplate:metadata:labels:app: mywebspec:nodeSelector:key: web1 #关键的代码在这里Pod.spec.nodeSelector(deployment.template.spec.nodeSelector)containers:- name: mywebimage: nginxports:- containerPort: 80
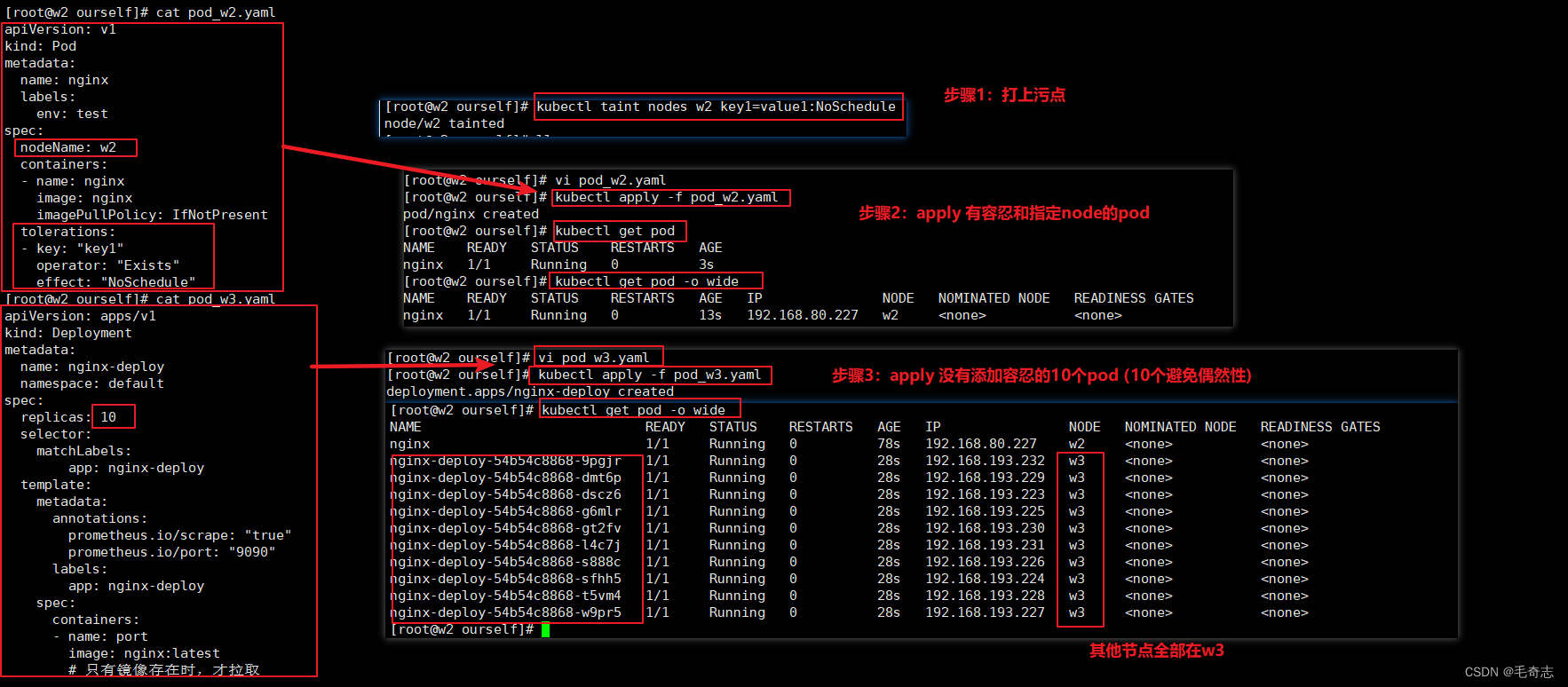
3.1.2 实践:实现 pod 独占 node (nodeName + Taint + Tolerations)
分析:
污点 和 容忍,可以完全决定一个或多个pod 一定不调度 到某个节点node
nodeName (或者 nodeSelector + label) ,可以完全决定一个或多个pod 一定调度 到某个节点node
独占的目的是:某个pod 一定调度到某个node上,且 其他pod一定不调度到这个node上
所以,最终方案是: nodeName + 污点 + 容忍
您可以使用命令 kubectl taint 给节点增加一个污点。比如,
kubectl taint nodes w2 key1=value1:NoSchedule
pod_w2.yamlapiVersion: v1
kind: Pod
metadata:name: nginxlabels:env: test
spec:nodeName: w2containers:- name: nginximage: nginximagePullPolicy: IfNotPresenttolerations:- key: "key1"operator: "Exists"effect: "NoSchedule"
其他所有的10个节点,都在 w3 上面,就实现了 pod 独占 w2
pod_w3.yamlapiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploynamespace: default
spec:replicas: 10 selector:matchLabels:app: nginx-deploytemplate:metadata:annotations:prometheus.io/scrape: "true"prometheus.io/port: "9090"labels:app: nginx-deployspec:containers:- name: portimage: nginx:latest# 只有镜像存在时,才拉取imagePullPolicy: IfNotPresent
3.2 亲和性和反亲和性
四个定义:
node的亲和性:将pod调度到这个node (分为 required 和 preferred 两种)
node的反亲和性:不要将pod调度调度到这个node (分为 required 和 preferred 两种)
pod的亲和性:将其他的pod调度到有这个pod的node (分为 required 和 preferred 两种)
pod的反亲和性:不要将其他的pod调度到有这个pod的node (分为 required 和 preferred 两种)
先搞懂node的亲和性和反亲和性,这个稍微容易一点,然后才是pod的亲和性和反亲和性
Pod亲和性指的是满足特定条件的的Pod对象运行在同一个node上, 而反亲和性调度则要求它们不能运行于同一node ,使用 pod 反亲和性这一套,可以完成:当 node 数量大于等于 pod 数量的时候,每个node上各有一个 pod (当然,当 pod 数量大于 node 的时候,平均分配还是要看 拓扑分布)。
3.2.1 node亲和性:让其他pod 强制调度/优先调度 到这个node上
先测试一个pod,然后再加一个pod,不断增加,直到当前节点硬件资源用完了 kubectl describe nodes xxx ,才能部署到另一个noed
先看 required 硬性限制
required 硬性限制
节点亲和性概念上类似于 nodeSelector, 它使你可以根据节点上的标签来约束 Pod 可以调度到哪些节点上。 节点亲和性有两种:
requiredDuringSchedulingIgnoredDuringExecution: 调度器只有在规则被满足的时候才能执行调度。此功能类似于 nodeSelector, 但其语法表达能力更强。
preferredDuringSchedulingIgnoredDuringExecution: 调度器会尝试寻找满足对应规则的节点。如果找不到匹配的节点,调度器仍然会调度该 Pod。
nodeAffinity + requiredDuringSchedulingIgnoredDuringExecution 等效 nodeSelector+label 等效 nodeName,三种都是硬性指定限制
至于 nodeAffinity + requiredDuringSchedulingIgnoredDuringExecution 等效 nodeSelector+label ,是怎样等效的,其实也是通过 标签选择器,node 打上标签,然后 pod 的节点亲和性来选择
kubectl get nodes -o wide --show-labels 查看所有节点的标签(也可以不需要 -o wide )
kubectl describe nodes xxx 查看指定节点的标签(这个命令也可以查看指定节点的当前硬件使用)
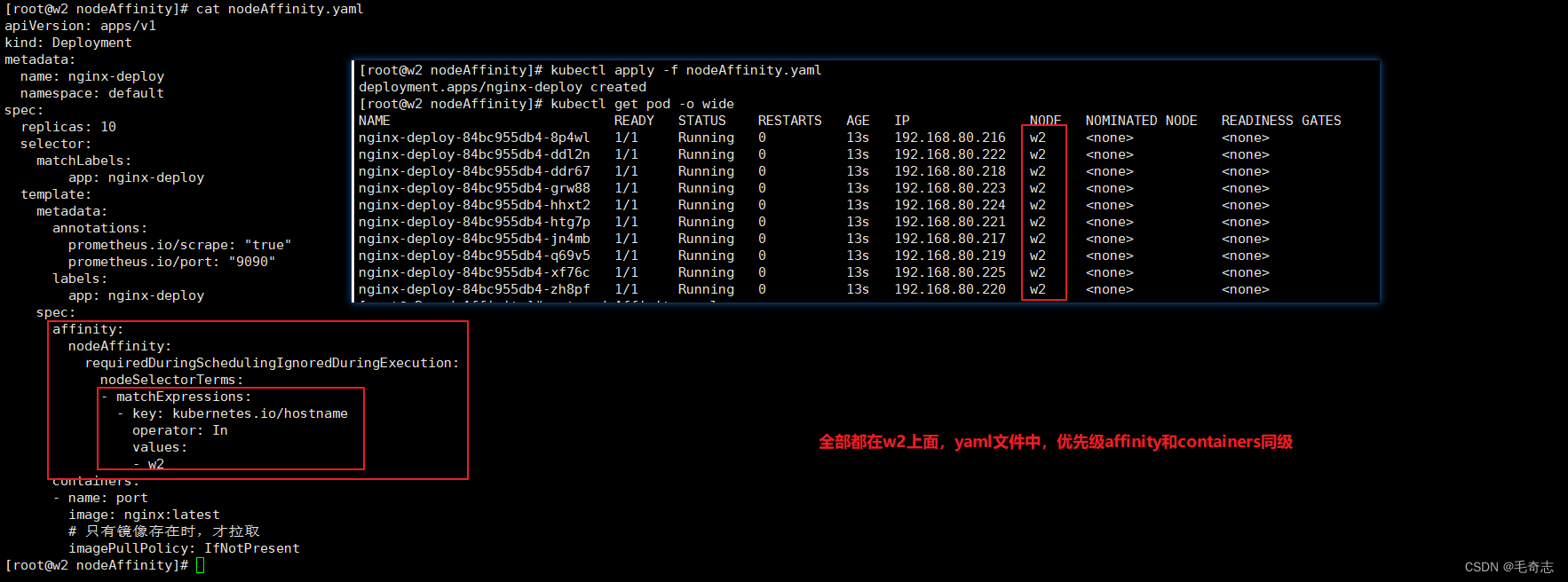
测试:测试10个pod,都调度到同一个node上 (10个避免偶然性)
nodeAffinity.yamlapiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploynamespace: default
spec:replicas: 10 selector:matchLabels:app: nginx-deploytemplate:metadata:annotations:prometheus.io/scrape: "true"prometheus.io/port: "9090"labels:app: nginx-deployspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- w2containers:- name: portimage: nginx:latest# 只有镜像存在时,才拉取imagePullPolicy: IfNotPresent
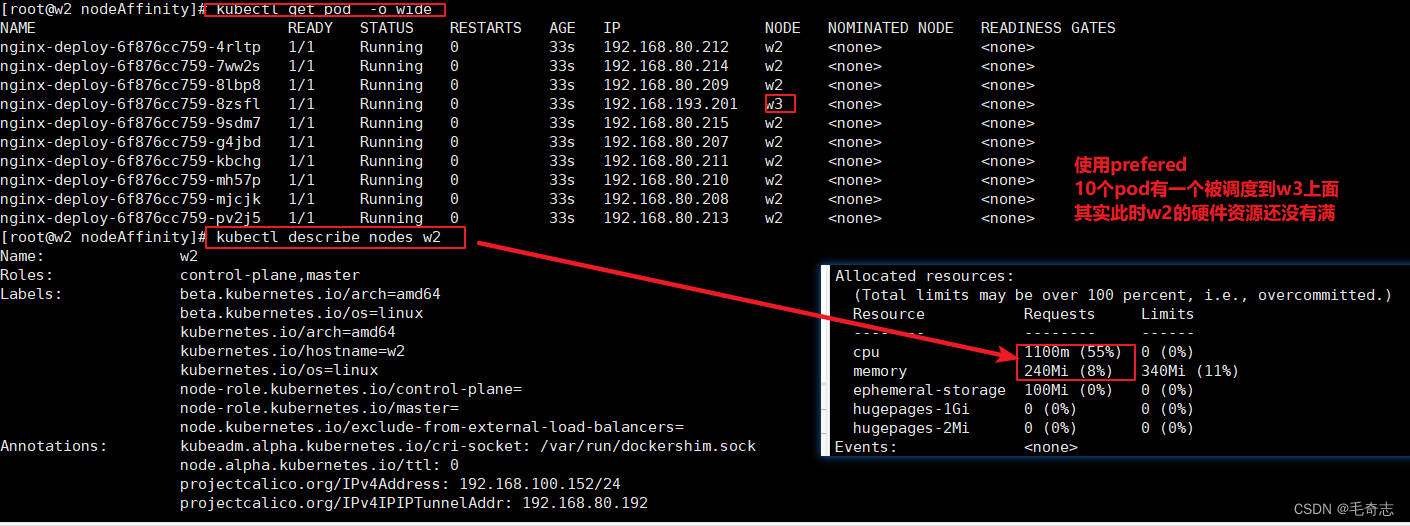
preferred 软性限制
然后是 preferred 软性限制/优先调度
nodeAffinity.yamlapiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploynamespace: default
spec:replicas: 10 selector:matchLabels:app: nginx-deploytemplate:metadata:annotations:prometheus.io/scrape: "true"prometheus.io/port: "9090"labels:app: nginx-deployspec:affinity:nodeAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 1preference:matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- w2containers:- name: portimage: nginx:latest# 只有镜像存在时,才拉取imagePullPolicy: IfNotPresent
小结:各个属性的含义
对于pod的亲和性,required和preferred 下面的属性,略有不同

搞懂各个属性
weight字段是权重/分数,闭区间 [1,100],required没有,perferred独有
为什么 perferred 有 weight 字段
回答:用来计算分数的,preferredDuringSchedulingIgnoredDuringExecution 亲和性类型的每个实例设置 weight 字段,其取值范围是 1 到 100。 当调度器找到能够满足 Pod 的其他调度请求的节点时,调度器会遍历节点满足的所有的偏好性规则, 并将对应表达式的 weight 值加和。最终的加和值会添加到该节点的其他优先级函数的评分之上。 在调度器为 Pod 作出调度决定时,总分最高的节点的优先级也最高。
官网链接:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/assign-pod-node/#node-affinity

为什么 required 没有 weight 字段
回答:required 就是强制的意思,相当于默认自带 weight 为最高/无穷大,必须满足
operator :operator 字段来为 Kubernetes 设置在解释规则时要使用的逻辑操作符。 你可以使用 In、NotIn、Exists、DoesNotExist、Gt 和 Lt 之一作为操作符。NotIn 和 DoesNotExist 可用来实现节点反亲和性行为。
In:label的值在某个列表中
NotIn:label的值不在某个列表中
Gt:label的值大于某个值
Lt:label的值小于某个值
Exists:某个label存在 #####values为任意值。
DoesNotExist:某个label不存在
preferredDuringSchedulingIgnoredDuringExecution和requiredDuringSchedulingIgnoredDuringExecution
这两个名字中的后半段符串IgnoredDuringExecution隐含的意义所指,在Pod资源基于节点亲和性规则调度至某节点之后,节点标签发生了改变而不再符合此节点亲和性规则时 ,调度器不会将Pod对象从此节点上移出,因为,它仅对新建的Pod对象生效。
其实,无论是 nodeName 、nodeSelector+label 、亲和性和反亲和性、拓扑分布方式,都是只对第一次调用生效,要想整个生命周期都生效,需要在deployment所在yaml文件中,使用 descheduler 组件,是一个开源在 github 上的组件
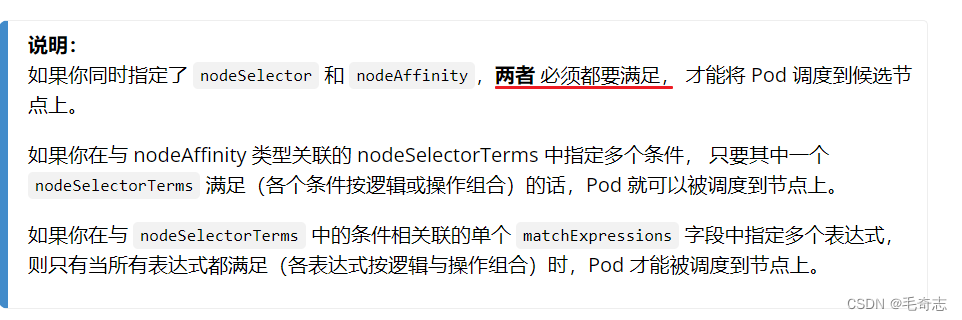
最后说明:
1、 nodeSelector 和 nodeAffinity 是一个且的关系,必须同时满足
2、 nodeAffinity 下面的多个 nodeSelectorTerms 是一个或的关系,满足一个即可 调度 到 node 上
3、 nodeSelectorTerms 下面的多个 matchExpressions 是一个且的关系,必须同时满足
官网链接:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/assign-pod-node/#node-affinity
3.2.2 node反亲和性:让其他pod 强制不要调度/优先不要调度 到这个node上
node反亲和性实现方式
方式1:直接通过 Taint 污点来实现,不要将任何 pod 调度到这个 node 上,然后通过 Tolerations 容忍给pod开白名单
方式2:NotIn NotExists 来实现
错误方式1:从来没有一个叫 nodeAntiAffinity 的属性,如下图方式是错误的:
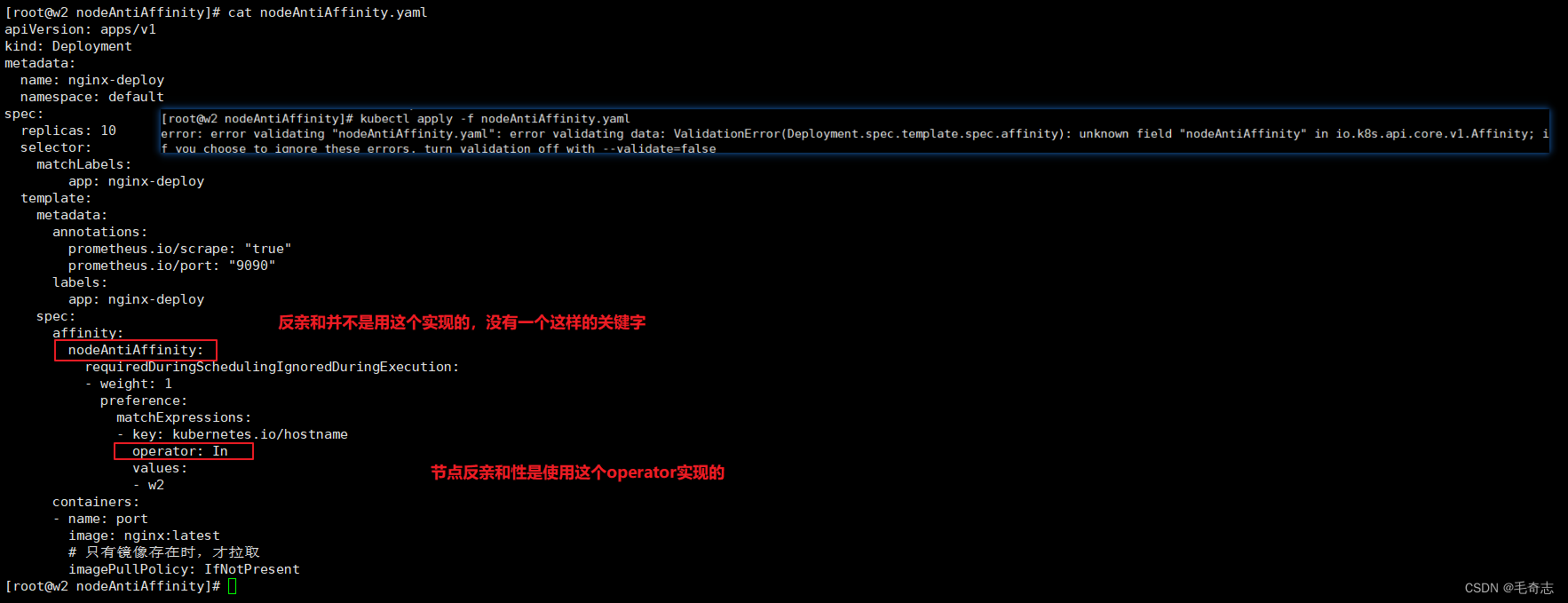
required硬性限制
cat nodeAntiAffinity_require.yamlapiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploynamespace: default
spec:replicas: 10 selector:matchLabels:app: nginx-deploytemplate:metadata:annotations:prometheus.io/scrape: "true"prometheus.io/port: "9090"labels:app: nginx-deployspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: NotInvalues:- w2containers:- name: portimage: nginx:latest# 只有镜像存在时,才拉取imagePullPolicy: IfNotPresent
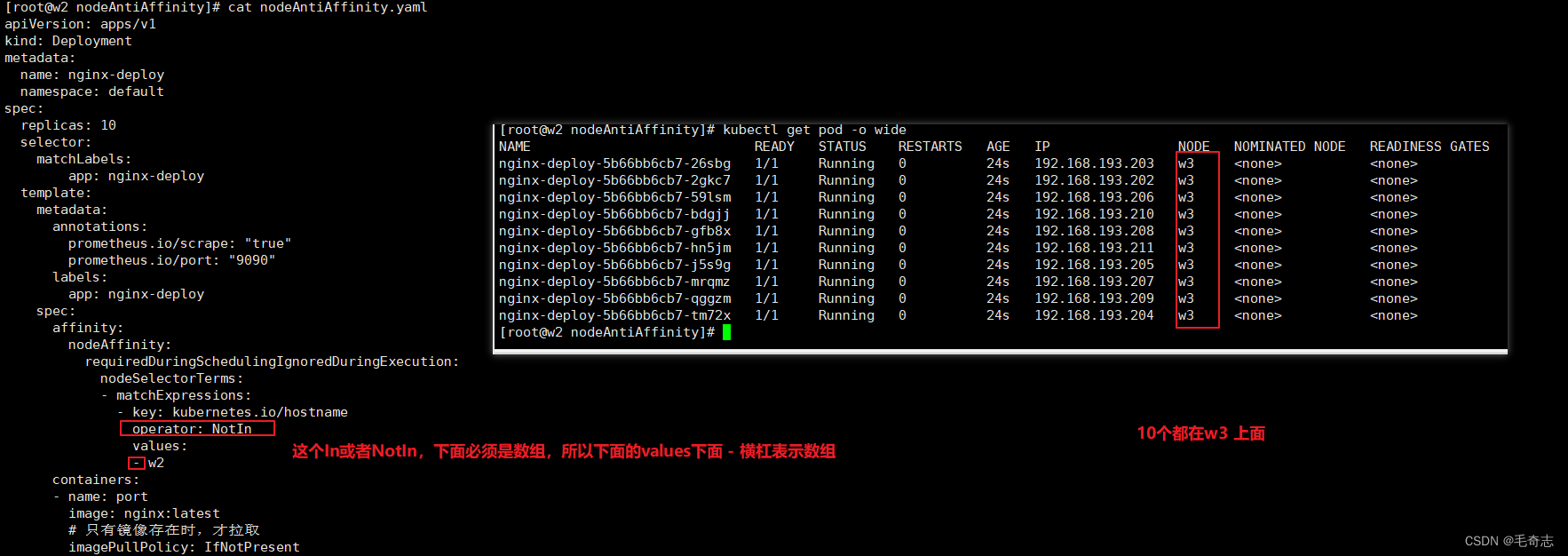
preferred 软件限制
cat nodeAntiAffinity_preferred.yamlapiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploynamespace: default
spec:replicas: 10 selector:matchLabels:app: nginx-deploytemplate:metadata:annotations:prometheus.io/scrape: "true"prometheus.io/port: "9090"labels:app: nginx-deployspec:affinity:nodeAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 1preference:matchExpressions:- key: kubernetes.io/hostnameoperator: NotInvalues:- w2containers:- name: portimage: nginx:latest# 只有镜像存在时,才拉取imagePullPolicy: IfNotPresent
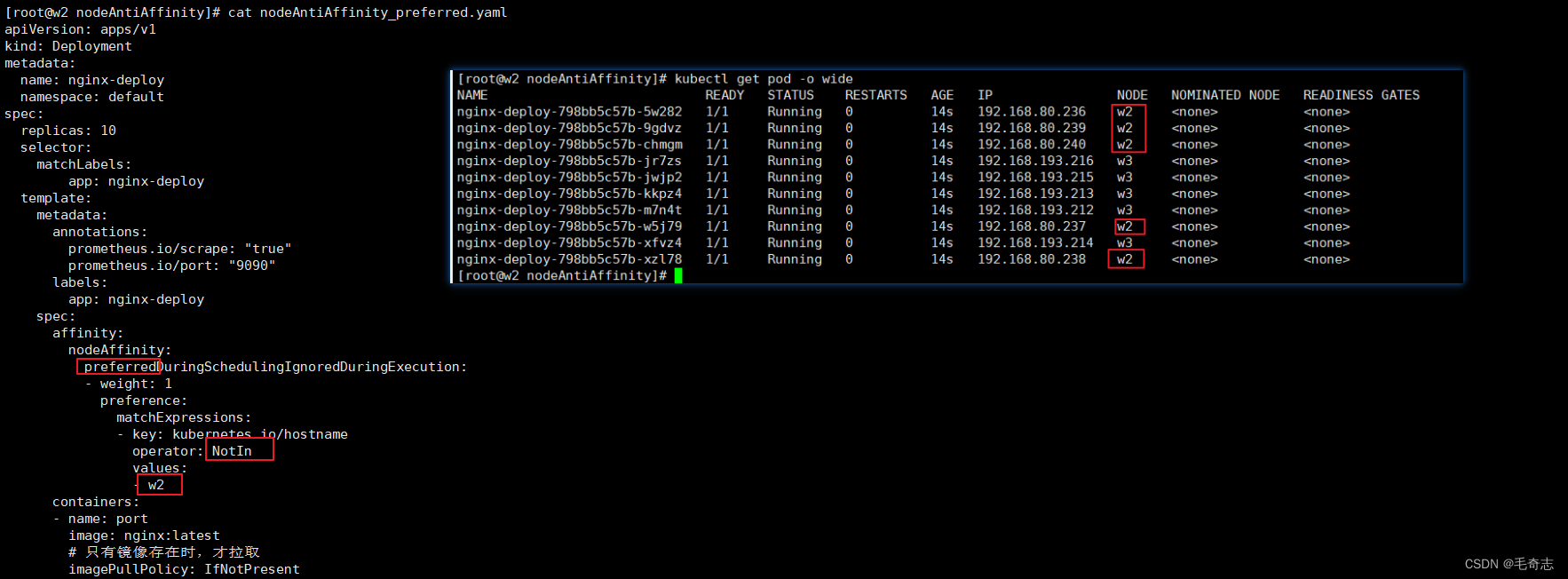
小结:各个属性的含义
无,反亲和性没有引入新的属性
3.2.3 pod亲和性:让其他pod优先调度到有一个pod的node上(至少要有两个节点,才能完成测试)
required硬性限制
先测试一个pod,然后再加一个pod,不断增加,直到当前节点硬件资源用完了 kubectl describe nodes xxx ,才能部署到另一个node
podAffinity_require_hostname.yamlapiVersion: apps/v1
kind: Deployment
metadata:name: deploylabels:app: web
spec:replicas: 6selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- name: nginx-deployimage: nginx:latestimagePullPolicy: IfNotPresentaffinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- webtopologyKey: kubernetes.io/hostname
pod亲和性相对于node亲和性,这里多了一个 topologyKey ,是用来分区的key,就是这个key的value不同就是划入到不同区域。比如上面使用 kubernetes.io/hostname 进行分区,那么 w2 w3 两个机器就是两个不同的分区,即每个机器是一个分区,第一个pod调度到哪个机器,后面五个pod只能调度到哪个机器,因为要调度到 第一个pod 所在的那个分区
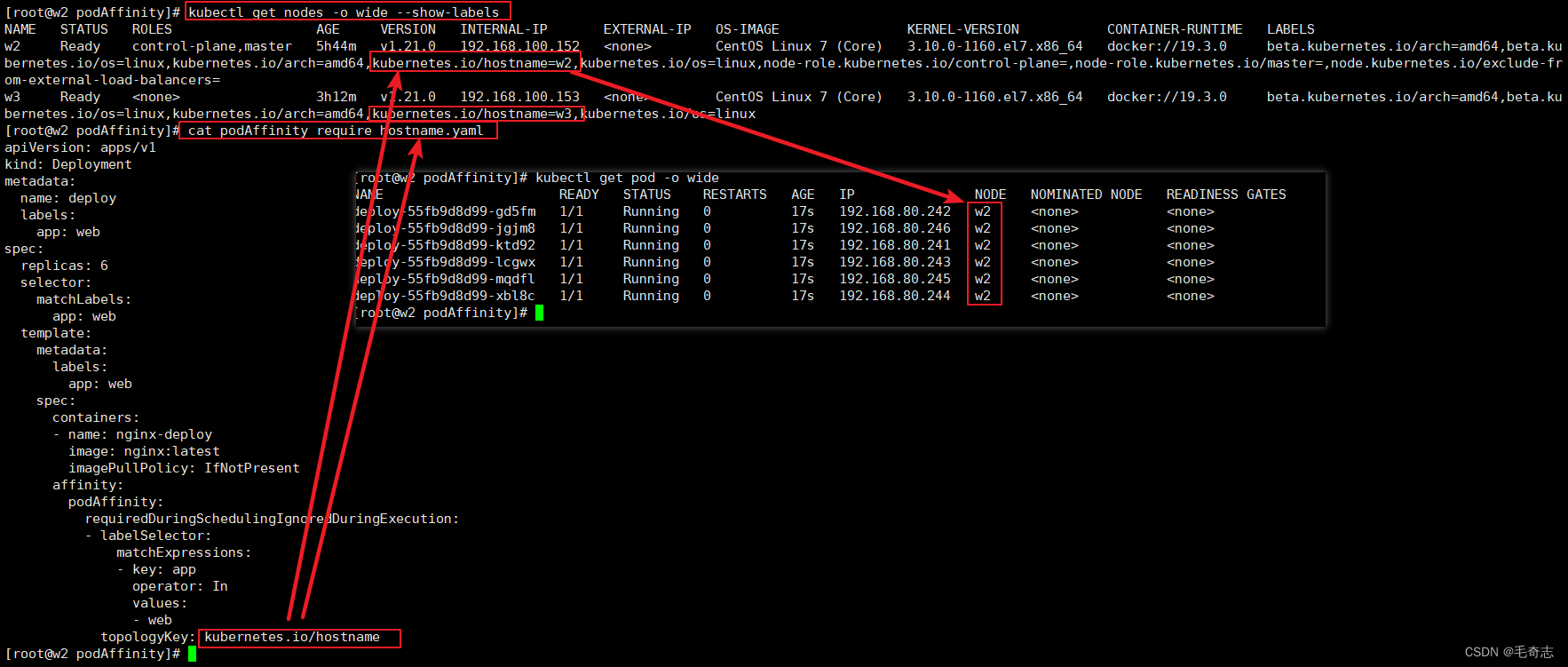
测试一下这个拓扑字段,就是分区字段,将两个机器设置的value设置为同一个,或者取value相同的key
podAffinity_require_os.yamlapiVersion: apps/v1
kind: Deployment
metadata:name: deploylabels:app: web
spec:replicas: 6selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- name: nginx-deployimage: nginx:latestimagePullPolicy: IfNotPresentaffinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- webtopologyKey: kubernetes.io/os
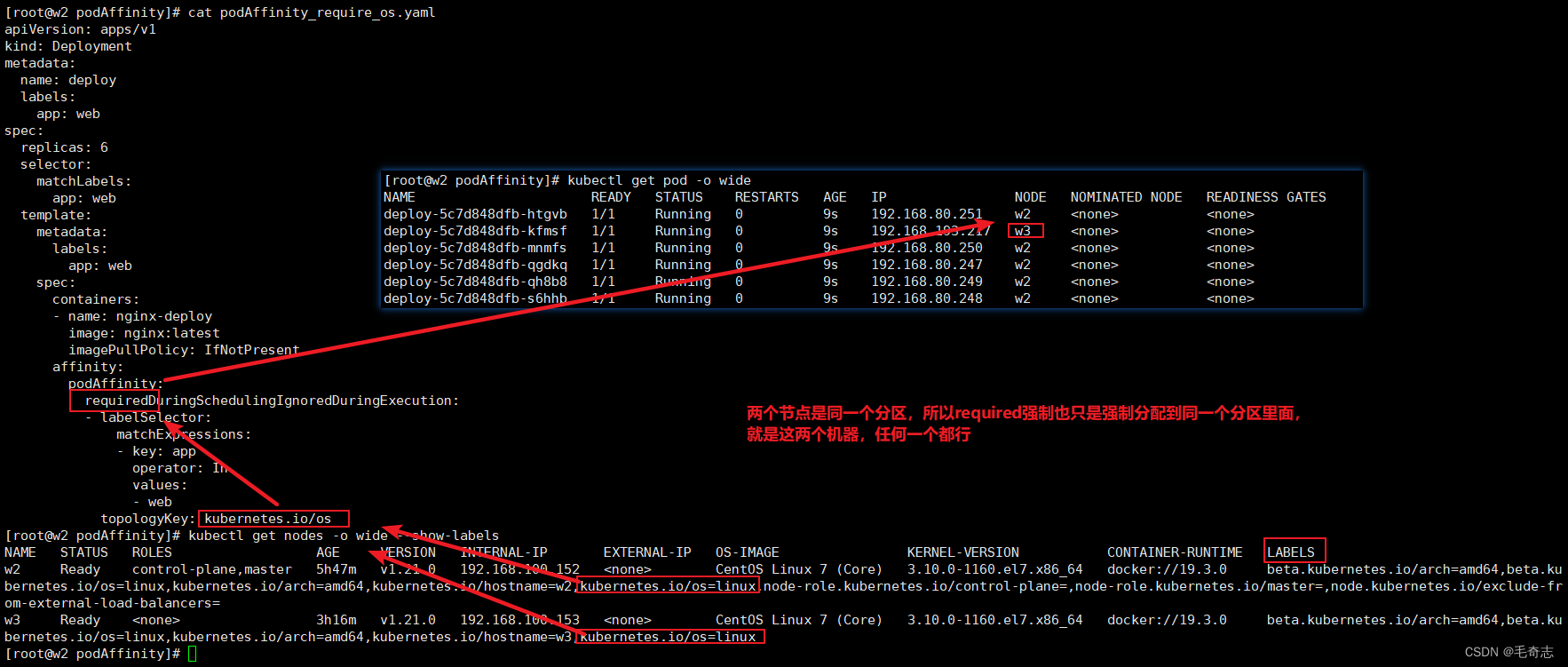
对于pod的亲和性,搞懂各个属性,而且测试成功,就算完成了
preferred软性限制
podAffinity_preferred_hostname.yamlapiVersion: apps/v1
kind: Deployment
metadata:name: deploylabels:app: web
spec:replicas: 6selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- name: nginx-deployimage: nginx:latestimagePullPolicy: IfNotPresentaffinity:podAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 80podAffinityTerm:labelSelector:matchExpressions:- {key: app, operator: In, values: ["web"]}topologyKey: kubernetes.io/hostname- weight: 20podAffinityTerm:labelSelector:matchExpressions:- {key: app, operator: In, values: ["web"]}topologyKey: kubernetes.io/hostname
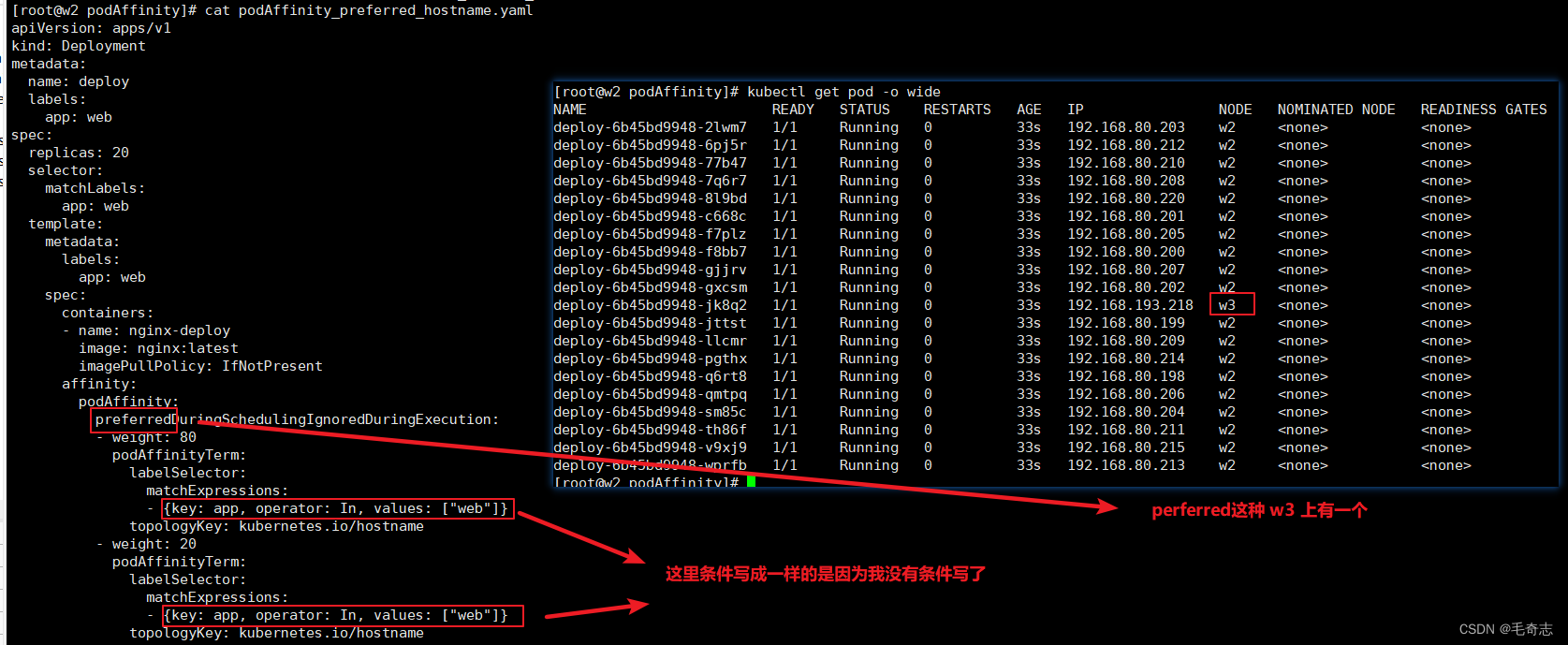
假如,如下:
apiVersion: apps/v1
kind: Deployment
metadata:name: app-affinity
spec:replicas: 5selector:matchLabels:app: myapptemplate:metadata:name: myapplabels:app: myappspec:affinity:podAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 80podAffinityTerm:labelSelector:matchExpressions:- {key: app, operator: In, values: ["nginx"]}topologyKey: zone- weight: 20podAffinityTerm:labelSelector:matchExpressions:- {key: app, operator: In, values: ["apach"]}topologyKey: zonecontainers:- name: nginximage: nginx
######启动pod
[root@node1 ~]# kubectl apply -f pod-soft.yaml
deployment.apps/app-affinity created
#####如下:
[root@node1 ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
app-affinity-66fbb677c7-2kwjf 1/1 Running 0 3s 172.25.166.158 node1 <none> <none>
app-affinity-66fbb677c7-5thfw 1/1 Running 0 3s 172.25.166.155 node1 <none> <none>
app-affinity-66fbb677c7-drdml 1/1 Running 0 3s 172.25.166.159 node1 <none> <none>
app-affinity-66fbb677c7-qq9fn 1/1 Running 0 3s 172.25.166.156 node1 <none> <none>
app-affinity-66fbb677c7-vq4jg 1/1 Running 0 3s 172.25.166.157 node1 <none> <none>
它定义了两组亲和性判定机制,一个是选择nginx Pod所在节点的zone标签,并赋予了较高的权重80,另一个是选择apach Pod所在节点的 zone标签,它有着略低的权重20。于是,调度器会将目标节点分为四类 :nginx Pod和apach Pod同时所属的zone(weight=100)、nginx Pod单独所属的zone(weight=)、apach Pod单独所属的zone(weight=20),以及其他所有的zone(weight=0)。
实际意义:Pod亲和性的实际应用就是,比如 A服务运行在某一个node,我们需要 B服务也运行到这个Pod,就可以让这样处理。
3.2.4 pod反亲和性(pod多于node情况下,可以保证每个node只有一个pod)
required硬性限制
podAntiAffinity_require_hostname.yamlapiVersion: apps/v1
kind: Deployment
metadata:name: deploylabels:app: web
spec:replicas: 6selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- name: nginx-deployimage: nginx:latestimagePullPolicy: IfNotPresentaffinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- webtopologyKey: kubernetes.io/hostname
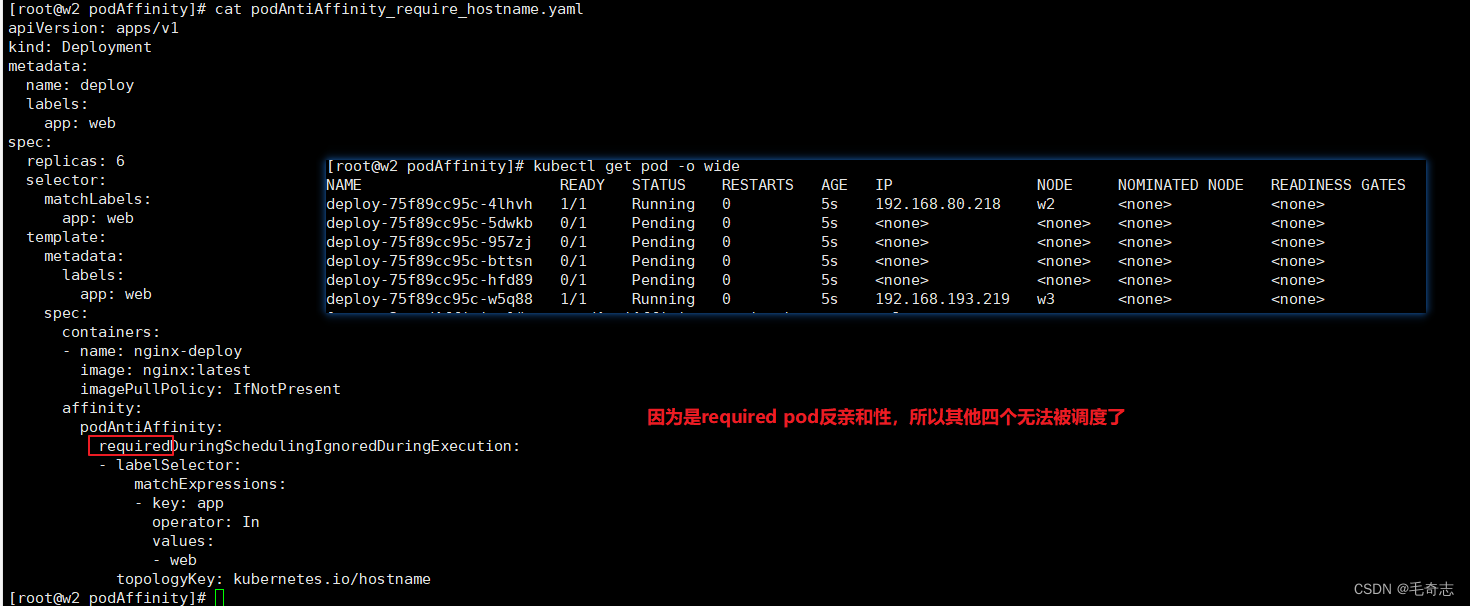
preferred软性限制
podAffinity_preferred_hostname.yamlapiVersion: apps/v1
kind: Deployment
metadata:name: deploylabels:app: web
spec:replicas: 6selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- name: nginx-deployimage: nginx:latestimagePullPolicy: IfNotPresentaffinity:podAntiAffinity:preferredDuringSchedulingIgnoredDuringExecution:- weight: 1podAffinityTerm:labelSelector:matchExpressions:- {key: app, operator: In, values: ["web"]}topologyKey: kubernetes.io/hostname
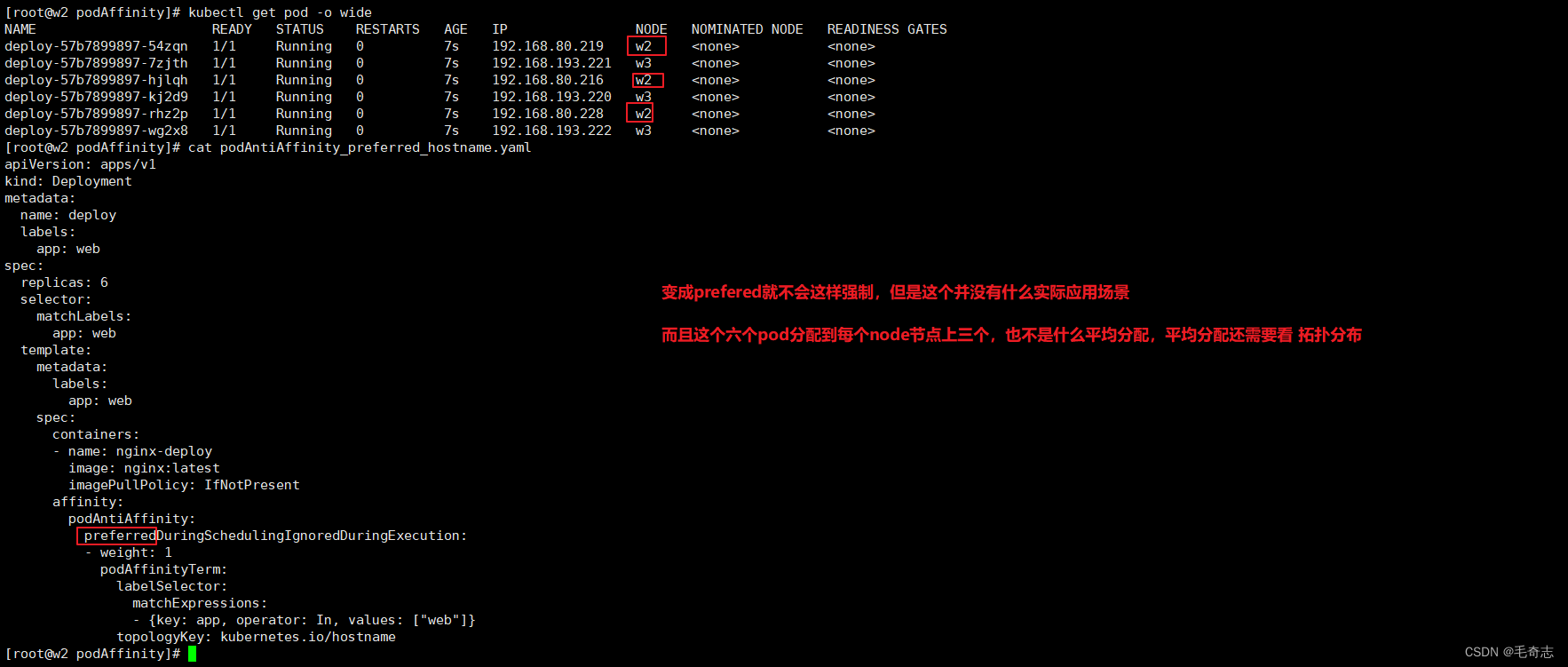
3.3 拓扑方式 (各个node节点平均分配pod) v1.19才引入
拓扑方式可以解决平均分配问题,但是需要注意 k8s 版本
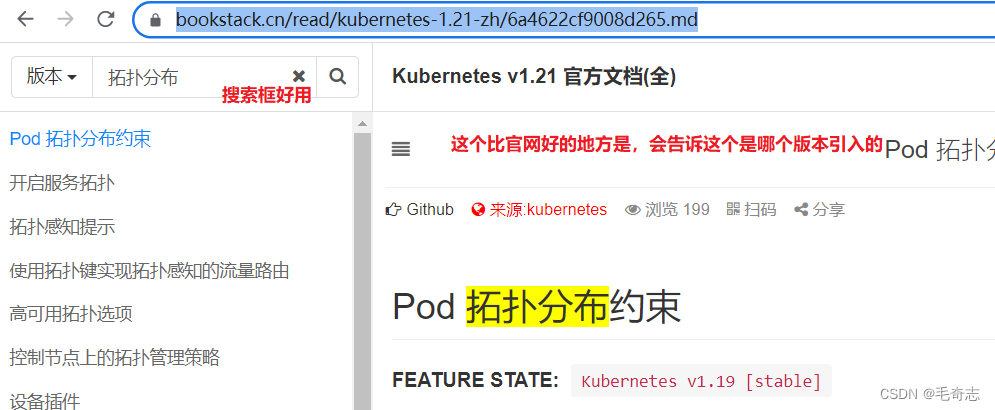
如果集群版本过低,无法使用拓扑分布
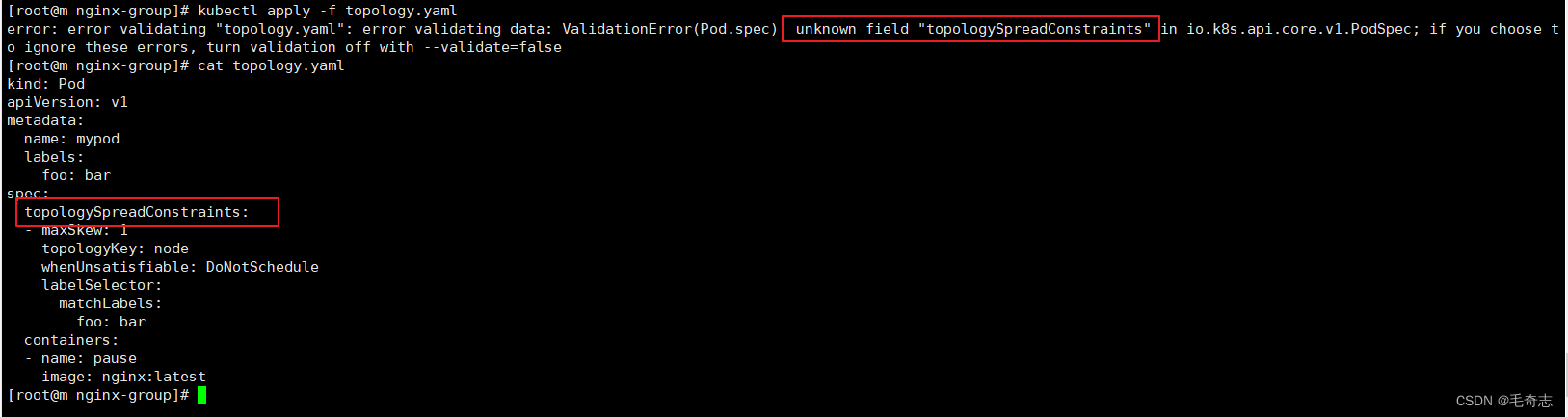
测试拓扑分布:15个pod,平均分配到两个node上(至少要有两个节点,才能完成测试)
cat topology.yamlapiVersion: apps/v1
kind: Deployment
metadata:name: mypod
spec:selector:matchLabels:foo: barreplicas: 3template:metadata:labels:foo: barspec:topologySpreadConstraints:- maxSkew: 15topologyKey: kubernetes.io/hostnamewhenUnsatisfiable: DoNotSchedulelabelSelector:matchLabels:foo: barcontainers:- name: pauseimage: nginx:latest
15个pod,平均分配,一个节点7个,一个节点8个,说明生效了
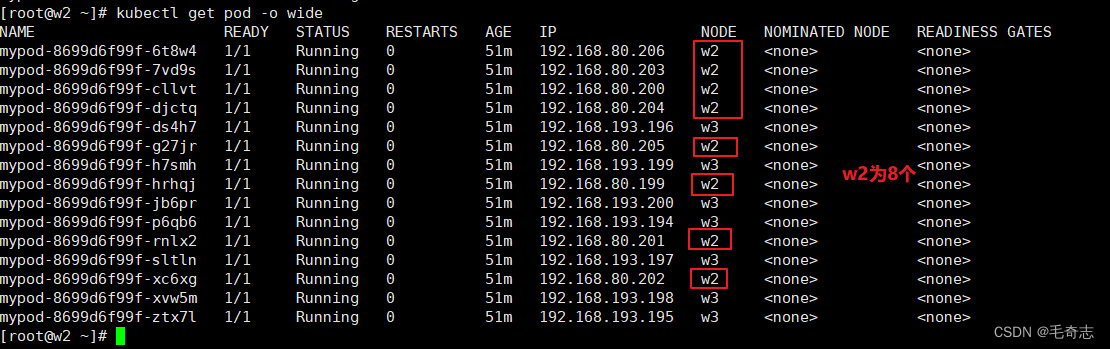
对于拓扑分布,理解下面的属性,并且测试成功,就上手了

四、尾声
默认scheduler调度算法:需要设置好request和limit,并且是一样大,而且比 jvm 参数大一些,内存大 500m,cpu大0.5
节点三要素:label 、污点、Unschedulable属性
yaml文件中一个属性:Toleration容忍
scheduler调度的四种方式
nodeName = nodeSelector + label = nodeAffinity + require (节点强亲和性)
拓扑方式用来平均分配
四种方式都是创建的时候调度,药性运行时候调度,需要使用 descheduler 组件,它是 scheduler 的补充
天天打码,天天进步!
这篇关于Kubernetes组件_Scheduler_01_将Pod指派给Node的四种方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





