本文主要是介绍Hadoop支持的文件格式之SequenceFile,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 0x00 文章内容
- 0x01 SequenceFile格式概念
- 1. SequenceFile是啥
- 0x02 编码实现
- 1. 写文件完整代码
- 2. 读文件完整代码
- 3. 写文件完整代码(HDFS)
- 4. 读文件完整代码(HDFS)
- 0x03 校验结果
- 1. 启动集群
- 2. 执行写SequenceFile文件格式代码
- 3. 执行读SequenceFile文件格式代码
- 4. 执行写SequenceFile文件格式代码(HDFS)
- 5. 执行读SequenceFile文件格式代码(HDFS)
- 0xFF 总结
0x00 文章内容
Hadoop支持的四种常用的文件格式:Text(csv)、Parquet、Avro以及SequenceFile,非常关键!
0x01 SequenceFile格式概念
1. SequenceFile是啥
二进制格式。
0x02 编码实现
1. 写文件完整代码
package com.shaonaiyi.hadoop.filetype.sequence;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;import java.io.IOException;
import java.net.URI;/*** @Author shaonaiyi@163.com* @Date 2019/12/20 11:27* @Description Hadoop支持的文件格式之写Sequence*/
public class SequenceFileWriter {private static final String[] DATA = {"shao, naiyi, bigdata, hadoop","naiyi, bigdata, spark","yi, two, a good man"};public static void main(String[] args) throws IOException {String uri = "hdfs://master:9999/user/hadoop-sny/mr/filetype/sequence.seq";Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(URI.create(uri), configuration);Path path = new Path(uri);IntWritable key = new IntWritable();Text value = new Text();SequenceFile.Writer writer = null;try {writer = SequenceFile.createWriter(configuration,SequenceFile.Writer.file(path), SequenceFile.Writer.keyClass(key.getClass()),SequenceFile.Writer.valueClass(value.getClass()));for (int i = 0; i < 100; i++) {key.set(100 -i);value.set(DATA[i % DATA.length]);System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);writer.append(key, value);}} finally {writer.close();}}}
代码解读:根据配置文件、文件路径、key类型、value类型此四个参数构建SequenceFile的Writer对象,然后循环append进key和value
2. 读文件完整代码
package com.shaonaiyi.hadoop.filetype.sequence;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.ReflectionUtils;import java.io.IOException;
import java.net.URI;
/*** @Author shaonaiyi@163.com* @Date 2019/12/20 11:28* @Description Hadoop支持的文件格式之读Sequence*/
public class SequenceFileReader {public static void main(String[] args) throws IOException {String uri = "hdfs://master:9999/user/hadoop-sny/mr/filetype/sequence.seq";Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(URI.create(uri), configuration);Path path = new Path(uri);SequenceFile.Reader reader = null;try {reader = new SequenceFile.Reader(configuration, SequenceFile.Reader.file(path));Writable key = (Writable)ReflectionUtils.newInstance(reader.getKeyClass(), configuration);Writable value = (Writable)ReflectionUtils.newInstance(reader.getValueClass(), configuration);long position = reader.getPosition();while (reader.next(key, value)) {String syncSeen = reader.syncSeen() ? "*" : "";System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);position = reader.getPosition();}} finally {reader.close();}}}
3. 写文件完整代码(HDFS)
package com.shaonaiyi.hadoop.filetype.sequence;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.mapreduce.task.JobContextImpl;
import org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl;import java.io.IOException;/*** @Author shaonaiyi@163.com* @Date 2019/12/20 12:53* @Description Hadoop支持的文件格式之写Sequence(HDFS)*/
public class MRSequenceFileWriter {public static void main(String[] args) throws IOException, IllegalAccessException, InstantiationException, ClassNotFoundException, InterruptedException {//1 构建一个job实例Configuration hadoopConf = new Configuration();Job job = Job.getInstance(hadoopConf);//2 设置job的相关属性job.setOutputKeyClass(LongWritable.class);job.setOutputValueClass(Text.class);job.setOutputFormatClass(SequenceFileOutputFormat.class);//3 设置输出路径FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9999/user/hadoop-sny/mr/filetype/sequence"));//4 构建JobContextJobID jobID = new JobID("jobId", 123);JobContext jobContext = new JobContextImpl(job.getConfiguration(), jobID);//5 构建taskContextTaskAttemptID attemptId = new TaskAttemptID("attemptId", 123, TaskType.REDUCE, 0, 0);TaskAttemptContext hadoopAttemptContext = new TaskAttemptContextImpl(job.getConfiguration(), attemptId);//6 构建OutputFormat实例OutputFormat format = job.getOutputFormatClass().newInstance();//7 设置OutputCommitterOutputCommitter committer = format.getOutputCommitter(hadoopAttemptContext);committer.setupJob(jobContext);committer.setupTask(hadoopAttemptContext);//8 获取writer写数据,写完关闭writerRecordWriter<LongWritable, Text> writer = format.getRecordWriter(hadoopAttemptContext);String value = "shao";writer.write(new LongWritable(System.currentTimeMillis()), new Text(value));writer.close(hadoopAttemptContext);//9 committer提交job和taskcommitter.commitTask(hadoopAttemptContext);committer.commitJob(jobContext);}}
4. 读文件完整代码(HDFS)
package com.shaonaiyi.hadoop.filetype.sequence;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.task.JobContextImpl;
import org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl;import java.io.IOException;
import java.util.List;
import java.util.function.Consumer;
/*** @Author shaonaiyi@163.com* @Date 2019/12/20 14:17* @Description Hadoop支持的文件格式之读Sequence(HDFS)*/
public class MRSequenceFileReader {public static void main(String[] args) throws IOException, IllegalAccessException, InstantiationException {//1 构建一个job实例Configuration hadoopConf = new Configuration();Job job = Job.getInstance(hadoopConf);//2 设置需要读取的文件全路径FileInputFormat.setInputPaths(job, "hdfs://master:9999/user/hadoop-sny/mr/filetype/sequence");//3 获取读取文件的格式SequenceFileInputFormat inputFormat = SequenceFileInputFormat.class.newInstance();//4 获取需要读取文件的数据块的分区信息//4.1 获取文件被分成多少数据块了JobID jobID = new JobID("jobId", 123);JobContext jobContext = new JobContextImpl(job.getConfiguration(), jobID);List<InputSplit> inputSplits = inputFormat.getSplits(jobContext);//读取每一个数据块的数据inputSplits.forEach(new Consumer<InputSplit>() {@Overridepublic void accept(InputSplit inputSplit) {TaskAttemptID attemptId = new TaskAttemptID("jobTrackerId", 123, TaskType.MAP, 0, 0);TaskAttemptContext hadoopAttemptContext = new TaskAttemptContextImpl(job.getConfiguration(), attemptId);RecordReader<LongWritable, Text> reader = null;try {reader = inputFormat.createRecordReader(inputSplit, hadoopAttemptContext);reader.initialize(inputSplit, hadoopAttemptContext);while (reader.nextKeyValue()) {System.out.println(reader.getCurrentKey());System.out.println(reader.getCurrentValue());}reader.close();} catch (IOException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}});}}
0x03 校验结果
1. 启动集群
a. 启动HDFS集群,
start-dfs.sh
2. 执行写SequenceFile文件格式代码
a. 直接在Win上执行,控制台会显示结果:
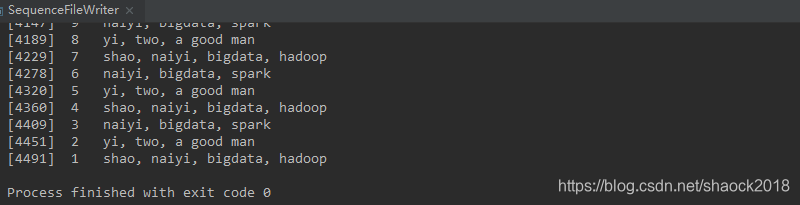
然后去集群也可以查看到结果:
hadoop fs -ls hdfs://master:9999/user/hadoop-sny/mr/filetype/
hadoop fs -cat hdfs://master:9999/user/hadoop-sny/mr/filetype/sequence.seq


b. 其实,还可以通过如下命令以Text格式查看二进制文件
hadoop fs -text hdfs://master:9999/user/hadoop-sny/mr/filetype/sequence.seq

注意,此处控制台打印的日志与写进文件的内容不一样,所以看到控制台其实是多打印了writer.getLength():
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
PS:如果报权限错误:
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="/user/hadoop-sny":hadoop-sny:supergroup:drwxr-xr-x
解决方案:需要去集群里修改权限
hadoop fs -mkdir -p hdfs://master:9999/user/hadoop-sny/mr/filetype
hadoop fs -chmod 757 hdfs://master:9999/user/hadoop-sny/mr/filetype
3. 执行读SequenceFile文件格式代码
a. 也可以得到相应的结果

4. 执行写SequenceFile文件格式代码(HDFS)
hadoop fs -ls hdfs://master:9999/user/hadoop-sny/mr/filetype/


5. 执行读SequenceFile文件格式代码(HDFS)
a. 可以看到代码里写进去的结果

对应的打印代码为:
String value = "shao";writer.write(new LongWritable(System.currentTimeMillis()), new Text(value));
0xFF 总结
- Hadoop支持的文件格式系列:
Hadoop支持的文件格式之Text
Hadoop支持的文件格式之Avro
Hadoop支持的文件格式之Parquet
Hadoop支持的文件格式之SequenceFile - 项目实战中,文章:网站用户行为分析项目之会话切割(二)中使用的存储格式是
Parquet。
作者简介:邵奈一
全栈工程师、市场洞察者、专栏编辑
| 公众号 | 微信 | 微博 | CSDN | 简书 |
福利:
邵奈一的技术博客导航
邵奈一 原创不易,如转载请标明出处。
这篇关于Hadoop支持的文件格式之SequenceFile的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







