本文主要是介绍万字长文让你深入了解BPF字节码 @龙蜥社区eBPF SIG,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、什么是字节码
相信大家在看有关BPF的文章时,都有听过“字节码”一说,在讲字节码之前先来了解一下,什么是机器码?机器码(machine code),也叫原生码(native code),就是CPU能够直接读取并运行的代码,执行速度最快的代码,用二进制编码表示,也叫做机器指令码。它和CPU体系架构强相关。
那么什么是字节码?字节码(byte code)是一种中间状态的二进制代码,是由源码编译过来的,可读性没有源码高,而且CPU也不能够直接读取字节码。字节码是一种中间码,它比机器码更抽象,需要直译器转译后才能成为机器码的中间代码。
说到字节码,就不得不提到JVM虚拟机,java源程序经过编译器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定机器上运行。它的运行顺序是:
java源代码 -> 编译器 -> JVM可执行的字节码 -> JVM中的解释器 -> 机器可执行的二进制机器码 -> 程序运行
java采用字节码的好处是,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以java程序运行时比较高效,而且由于字节码并不专对于一种特定的机器,因此java程序无需重新编译便可以在多种不同的计算机上运行。
说完java里面的字节码以及它的运行逻辑,也了解到它的可移植性和执行效率问题,会很自然的想到BPF字节码也具有异曲同工之妙。如下图所示,一般将BPF程序编译后生成BPF字节码,然后将BPF字节码注入到内核中,当有事件触发时,就会执行相应的BPF程序。这里生成字节码的方式需要用到一个编译器,比如当前主要是用C语言去编写BPF程序,通过LLVM/Clang编译生成BPF字节码,这是一种中间代码,将这段字节码加载到内核之后,Linux的验证程序确保它可以安全地运行,防止出现可能会使内核崩溃而危及系统的代码。Linux内核还为BPF指令集成了即时(JIT)编译器,JIT将直接将BPF字节码转换为机器码,从而避免了执行时间的开销。
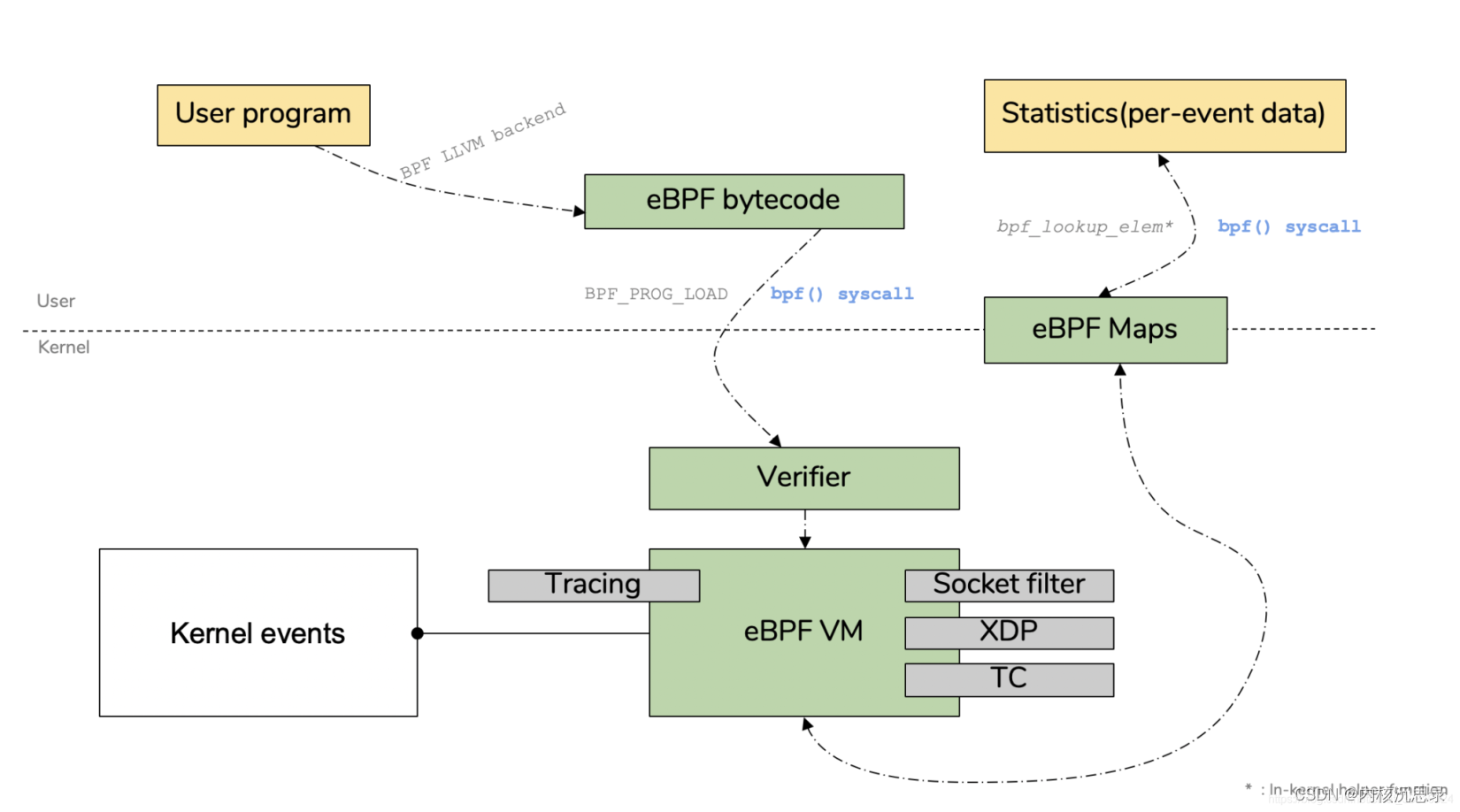
由上图可以看到,BPF字节码起到了非常关键的作用,虽然将用户BPF程序转成字节码是通过Clang编译器完成的,不用关心这个字节码或者说指令集长得怎么样?编译器干了这个脏活累活。但是,为了能提高编写代码和执行代码的效率问题,为了让Linux内核校验出错时,能快速定位出报错根因的话,就有必要了解一下BPF的字节码。
这里有很多概念可以先总结一下:
- 伪机器码:假的机器码,机器码都是能够在物理机上直接执行的,伪机器码不能够直接执行,需要在虚拟机上执行。BPF字节码就是伪机器码。
- BPF指令集:BPF字节码,是一条条的BPF指令,BPF指令集就是伪机器码,是不能够在物理机上直接执行的,需要一个虚拟机才能够执行。不同的处理器体系结构有自己的不同指令集,BPF指令集可以理解为在BPF虚拟机上执行的指令集。
- JIT:just in time 的缩写,编译好的BPF指令集需要在虚拟机上执行,虚拟机需要一条一条的解析为本机机器码才能够执行,所以这个执行效率会很低,但是如果处理器有了JIT就能够将BPF程序直接编译为能够在机器直接执行的机器码,这样大大提高了执行的速度。
在没有严格区分的情况下,文中所说的BPF字节码和BPF指令,是指同一个概念。
2、BPF指令集
BPF指令集是一个通用的 RISC 指令集,指令集由指令操作码和寄存器组成。1992年诞生了BPF技术,当时的寄存器和指令数目非常有限,到后来eBPF技术发展起来,寄存器和指令数目多了很多。为了区别,原来的BPF又称之为classic BPF(cBPF)。

从功能上,对比一下cBPF和eBPF:
- cBPF支持的功能比较单一,常用在网络的数据包过滤,比如大名鼎鼎的tcpdump。而eBPF除了能够支持网络的数据包的过滤外,也支持其他的事件类型,如XDP、Perf Event、kprobe、tracepoint等等。
- eBPF引入Map机制。在cBPF需要通过接收队列将过滤后数据获取出来,但是在eBPF上可以将数据放到Map空间中。Map空间是用户空间和内核空间共享的,所以一般是在内核中将数据存入到Map空间中,然后在用户空间取出数据。或者用户空间写入一些控制逻辑,内核空间根据它进行分支选择。
- eBPF指令集变得更复杂了,以便支持更多功能。与此同时,有了专门的用于编译BPF字节码的编译器clang/llvm,这样就可以基于c语言等进行BPF程序的开发,而不是直接写BPF汇编。
- 还有在安全机制方面等等一些改变。
2.1 tcpdump和cBPF指令码
在讲BPF指令集前,先看一下大家非常熟悉的tcpdump,这是一个通过输入表达式(其实是一些过滤规则)进行网络抓包的工具,然后通过libpcap把这个表达式转换成cBPF的字节码的。
这个字节码或者指令可以通过-d(-dd可以看到具体的指令格式)命令去查看,比如:
#tcpdump -d -i eth0 tcp and port 80
(000) ldh [12]
(001) jeq #0x86dd jt 2 jf 8
(002) ldb [20]
(003) jeq #0x6 jt 4 jf 19
(004) ldh [54]
(005) jeq #0x50 jt 18 jf 6
(006) ldh [56]
(007) jeq #0x50 jt 18 jf 19
(008) jeq #0x800 jt 9 jf 19
(009) ldb [23]
(010) jeq #0x6 jt 11 jf 19
(011) ldh [20]
(012) jset #0x1fff jt 19 jf 13
(013) ldxb 4*([14]&0xf)
(014) ldh [x + 14]
(015) jeq #0x50 jt 18 jf 16
(016) ldh [x + 16]
(017) jeq #0x50 jt 18 jf 19
(018) ret #262144
(019) ret #0#tcpdump -dd -i eth0 tcp and port 80
{ 0x28, 0, 0, 0x0000000c },
{ 0x15, 0, 6, 0x000086dd },
{ 0x30, 0, 0, 0x00000014 },
{ 0x15, 0, 15, 0x00000006 },
{ 0x28, 0, 0, 0x00000036 },
{ 0x15, 12, 0, 0x00000050 },
{ 0x28, 0, 0, 0x00000038 },
{ 0x15, 10, 11, 0x00000050 },
{ 0x15, 0, 10, 0x00000800 },
{ 0x30, 0, 0, 0x00000017 },
{ 0x15, 0, 8, 0x00000006 },
{ 0x28, 0, 0, 0x00000014 },
{ 0x45, 6, 0, 0x00001fff },
{ 0xb1, 0, 0, 0x0000000e },
{ 0x48, 0, 0, 0x0000000e },
{ 0x15, 2, 0, 0x00000050 },
{ 0x48, 0, 0, 0x00000010 },
{ 0x15, 0, 1, 0x00000050 },
{ 0x6, 0, 0, 0x00040000 },
{ 0x6, 0, 0, 0x00000000 },
cBPF架构的基本元素如下,以下内容来源于linux 内核目录下的:
Documentation/networking/filter.rst

- 16*32位的杂项寄存器,又称为临时寄存器, 可寻找范围:0~15;
- cBPF汇编的一条指令为64字节, 在头文件<usr/include/linux/filter.h>中有定义。如下所示;
- 16bit的code表示具体的操作类型,有加载/存储,跳转,运算等类型;
- 8 bit的jt 和 jf 是用于提供代码的跳转偏移量,jt为真跳转,jf为假跳转;
- 32bit的k为通用值,根据指令类型有不同含义;
struct sock_filter { /* Filter block */__u16 code; /* Actual filter code */__u8 jt; /* Jump true */__u8 jf; /* Jump false */__u32 k; /* Generic multiuse field */
};
对于网络报文的过滤,有一个例子是直接将struct sock_filter数组的指针通过setsockopt(2) 传递给内核:
/* From the example above: tcpdump -i em1 port 22 -dd */struct sock_filter code[] = {{ 0x28, 0, 0, 0x0000000c },{ 0x15, 0, 8, 0x000086dd },{ 0x30, 0, 0, 0x00000014 },{ 0x15, 2, 0, 0x00000084 },{ 0x15, 1, 0, 0x00000006 },{ 0x15, 0, 17, 0x00000011 },{ 0x28, 0, 0, 0x00000036 },{ 0x15, 14, 0, 0x00000016 },{ 0x28, 0, 0, 0x00000038 },{ 0x15, 12, 13, 0x00000016 },{ 0x15, 0, 12, 0x00000800 },{ 0x30, 0, 0, 0x00000017 },{ 0x15, 2, 0, 0x00000084 },{ 0x15, 1, 0, 0x00000006 },{ 0x15, 0, 8, 0x00000011 },{ 0x28, 0, 0, 0x00000014 },{ 0x45, 6, 0, 0x00001fff },{ 0xb1, 0, 0, 0x0000000e },{ 0x48, 0, 0, 0x0000000e },{ 0x15, 2, 0, 0x00000016 },{ 0x48, 0, 0, 0x00000010 },{ 0x15, 0, 1, 0x00000016 },{ 0x06, 0, 0, 0x0000ffff },{ 0x06, 0, 0, 0x00000000 },};struct sock_fprog bpf = {.len = ARRAY_SIZE(code),.filter = code,};sock = socket(PF_PACKET, SOCK_RAW, htons(ETH_P_ALL));if (sock < 0)/* ... bail out ... */ret = setsockopt(sock, SOL_SOCKET, SO_ATTACH_FILTER, &bpf, sizeof(bpf));if (ret < 0)/* ... bail out ... *//* ... */close(sock);
由于性能有限, 因此后面cBPF由发展成为eBPF, 有新的指令和架构。原始的BPF指令会被自动翻译为新的eBPF指令,目前在Linux内核里,bpf_convert_filter()函数在做这个转换。
2.2 eBPF指令集
接下来重点来介绍eBPF的指令集。参考自:
Documentation/bpf/instruction-set.rst
Documentation/bpf/classic_vs_extended.rst
eBPF的寄存器
eBPF 由 11 个 64 位寄存器、一个程序计数器PC和一个 512 字节的大 BPF 堆栈空间组成。寄存器被命名为r0- r10。操作模式默认为 64 位。64位的寄存器也可作32 位子寄存器使用,它们只能通过特殊的 ALU(算术逻辑单元)操作访问,使用低32位,高32位使用零填充。
寄存器的使用约定如下:

在加载和存储指令中,寄存器 R6 是一个隐式输入,必须包含指向 sk_buff(ctx)的指针。寄存器 R0 是一个隐式输出,它包含从数据包中获取的数据。
eBPF的指令格式
struct bpf_insn 结构体用来表示eBPF具体的指令格式:
struct bpf_insn {__u8 code; /* opcode */__u8 dst_reg:4; /* dest register */__u8 src_reg:4; /* source register */__s16 off; /* signed offset */__s32 imm; /* signed immediate constant */
};
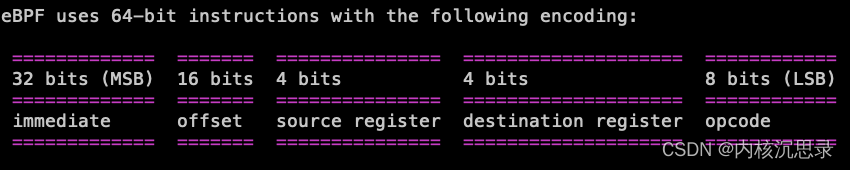
其中的code字段,如下:
+----------------+--------+--------------------+| 4 bits | 1 bit | 3 bits || operation code | source | instruction lass |+----------------+--------+--------------------+(MSB) (LSB)
opcode字段的低3位,决定指令类型。指令类型包含:加载与存储指令、运算指令、跳转指令。
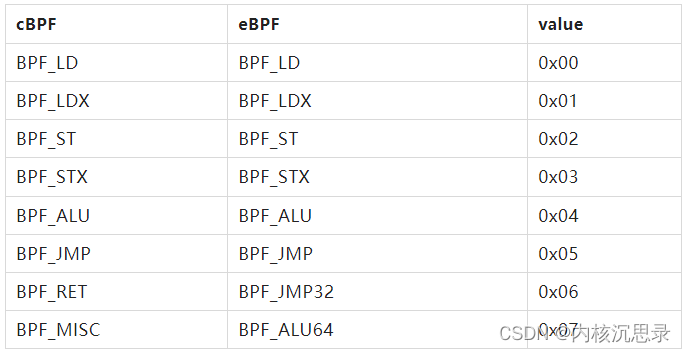
- eBPF把BPF_RET和BPF_MISC指令去掉了,换成了BPF_JMP32和BPF_ALU64,提供更大范围的跳转和64位场景下的运算操作。
- BPF_LD 和 BPF_LDX: 两个类都用于加载操作。BPF_LD用于加载双字。后者是从 cBPF 继承而来的,主要是为了保持 cBPF 到 eBPF 的转换效率,因为它们优化了JIT 代码。
- BPF_ST 和 BPF_STX: 两个类都用于存储操作,用于将数据从寄存器到存储器中。
- BPF_ALU 和 BPF_ALU64: 分别是32位和64位下的ALU操作。
- BPF_JMP 和 BPF_JMP32:跳转指令。JMP32的跳转范围是32位大小(一个字)
运算和跳转指令
当 BPF_CLASS(code) == BPF_ALU 或 BPF_JMP 时,code字段可分为三部分,如下所示:
+----------------+--------+--------------------+
| 4 bits | 1 bit | 3 bits |
| operation code | source | instruction class |
+----------------+--------+--------------------+
(MSB) (LSB)
其中的第四位source,可以为0或者1,在linux中,使用如下宏定义:
BPF_K 0x00
BPF_X 0x08
在cBPF中,表示:
BPF_SRC(code) == BPF_X - use register X as source operand
BPF_SRC(code) == BPF_K - use 32-bit immediate as source operand
在 eBPF 中,这意味着:
BPF_SRC(code) == BPF_X - use 'src_reg' register as source operand
BPF_SRC(code) == BPF_K - use 32-bit immediate as source operand
也就是说,操作数的选择上,BPF_K代表使用立即数,BPF_X代表使用源寄存器的内容。
如果 BPF_CLASS(code) 等于 BPF_ALU 或 BPF_ALU64,则 BPF_OP(code) 是以下之一:
BPF_ADD 0x00BPF_SUB 0x10BPF_MUL 0x20BPF_DIV 0x30BPF_OR 0x40BPF_AND 0x50BPF_LSH 0x60BPF_RSH 0x70BPF_NEG 0x80BPF_MOD 0x90BPF_XOR 0xa0BPF_MOV 0xb0 /* eBPF only: mov reg to reg */BPF_ARSH 0xc0 /* eBPF only: sign extending shift right */BPF_END 0xd0 /* eBPF only: endianness conversion */
如果 BPF_CLASS(code) 等于 BPF_JMP 或 BPF_JMP32,则 BPF_OP(code) 是以下之一:
BPF_JA 0x00 /* BPF_JMP only */BPF_JEQ 0x10BPF_JGT 0x20BPF_JGE 0x30BPF_JSET 0x40BPF_JNE 0x50 /* eBPF only: jump != */BPF_JSGT 0x60 /* eBPF only: signed '>' */BPF_JSGE 0x70 /* eBPF only: signed '>=' */BPF_CALL 0x80 /* eBPF BPF_JMP only: function call */BPF_EXIT 0x90 /* eBPF BPF_JMP only: function return */BPF_JLT 0xa0 /* eBPF only: unsigned '<' */BPF_JLE 0xb0 /* eBPF only: unsigned '<=' */BPF_JSLT 0xc0 /* eBPF only: signed '<' */BPF_JSLE 0xd0 /* eBPF only: signed '<=' */
加载和存储指令
当 BPF_CLASS(code) 等于 BPF_LD 或 BPF_ST 时,op字段可分为三部分,如下所示:
+--------+--------+-------------------+| 3 bits | 2 bits | 3 bits || mode | size | instruction class |+--------+--------+-------------------+(MSB) (LSB)
其中的size定义如下:
BPF_W 0x00 /* word=4 byte */
BPF_H 0x08 /* half word */
BPF_B 0x10 /* byte */
BPF_DW 0x18 /* eBPF only, double word */B - 1 byteH - 2 byteW - 4 byteDW - 8 byte (eBPF only)
mode定义如下:
BPF_IMM 0x00 /* used for 32-bit mov in classic BPF and 64-bit in eBPF */
BPF_ABS 0x20
BPF_IND 0x40
BPF_MEM 0x60
BPF_LEN 0x80 /* classic BPF only, reserved in eBPF */
BPF_MSH 0xa0 /* classic BPF only, reserved in eBPF */
BPF_ATOMIC 0xc0 /* eBPF only, atomic operations */
3、eBPF汇编
前面介绍了eBPF和cBPF的基础指令码,接下来一起看看eBPF的指令构成是什么样子的,这有助于去分析verifier出错时的一些根因定位。以x86_64为例,先介绍一下eBPF使用到的几个寄存器和x86_64的映射关系:
R0 - raxR1 - rdiR2 - rsiR3 - rdxR4 - rcxR5 - r8R6 - rbxR7 - r13R8 - r14R9 - r15R10 - rbp
rdi、rsi、rdx、rcx是传递的参数和顺序。
下面是一段eBPF的伪代码:
Then the following eBPF pseudo-program::
bpf_mov R6, R1 /* save ctx */bpf_mov R2, 2bpf_mov R3, 3bpf_mov R4, 4bpf_mov R5, 5bpf_call foobpf_mov R7, R0 /* save foo() return value */bpf_mov R1, R6 /* restore ctx for next call */bpf_mov R2, 6bpf_mov R3, 7bpf_mov R4, 8bpf_mov R5, 9bpf_call barbpf_add R0, R7bpf_exit
上面伪代码包括寄存器赋值,运算和跳转,以及返回。
如果机器上开启了相关架构的jit功能,会转成对应架构的汇编指令:
push %rbpmov %rsp,%rbpsub $0x228,%rspmov %rbx,-0x228(%rbp)mov %r13,-0x220(%rbp)mov %rdi,%rbxmov $0x2,%esimov $0x3,%edxmov $0x4,%ecxmov $0x5,%r8dcallq foomov %rax,%r13mov %rbx,%rdimov $0x6,%esimov $0x7,%edxmov $0x8,%ecxmov $0x9,%r8dcallq baradd %r13,%raxmov -0x228(%rbp),%rbxmov -0x220(%rbp),%r13leaveqretq
对应到的c程序:
u64 bpf_filter(u64 ctx)
{return foo(ctx, 2, 3, 4, 5) + bar(ctx, 6, 7, 8, 9);
}
具体汇编分析
为了加深对前面所介绍的基础指令的认识,接下来深入分析一下这段代码:
sample/bpf/sock_example.c
抽取关键的这个信息:
struct bpf_insn prog[] = {BPF_MOV64_REG(BPF_REG_6, BPF_REG_1), /* R6 = R1*/ /* R6指向数据包地址 */BPF_LD_ABS(BPF_B, ETH_HLEN + offsetof(struct iphdr, protocol) /* R0 = ip->proto */), /*R6作为隐式输入,R0作为隐式输出。结果R0报错IP协议值*/BPF_STX_MEM(BPF_W, BPF_REG_10, BPF_REG_0, -4), /* *(u32 *)(fp - 4) = r0 */ /* 将协议值保存在栈中*/BPF_MOV64_REG(BPF_REG_2, BPF_REG_10), /*R10只读寄存器,指向栈帧。复制一份到R2中*/BPF_ALU64_IMM(BPF_ADD, BPF_REG_2, -4), /* r2 = fp - 4 */ /* 内核bpf_map_lookup_elem函数的第二个参数key的内存地址放在R2中 */BPF_LD_MAP_FD(BPF_REG_1, map_fd), /* 内核bpf_map_lookup_elem函数的第一个参数map_fd放在R1中 */BPF_RAW_INSN(BPF_JMP | BPF_CALL, 0, 0, 0, BPF_FUNC_map_lookup_elem), /* 函数的返回值为value所在内存的地址,放在R0寄存器中*/BPF_JMP_IMM(BPF_JEQ, BPF_REG_0, 0, 2), /* 如果返回的内存地址为0,则向下跳两个指令 */BPF_MOV64_IMM(BPF_REG_1, 1), /* r1 = 1 */BPF_RAW_INSN(BPF_STX | BPF_XADD | BPF_DW, BPF_REG_0, BPF_REG_1, 0, 0), /* xadd r0 += r1 */ /* value的值加一;结果R0存储1,R1存储value地址 */BPF_MOV64_IMM(BPF_REG_0, 0), /* r0 = 0 */BPF_EXIT_INSN(), /* R0作为返回值,返回零 */};
第一条指令
/* Short form of mov, dst_reg = src_reg */#define BPF_MOV64_REG(DST, SRC) \((struct bpf_insn) { \.code = BPF_ALU64 | BPF_MOV | BPF_X, \.dst_reg = DST, \.src_reg = SRC, \.off = 0, \.imm = 0 })
BPF_MOV64_REG这条指令是将源寄存器R1的值移动到R6寄存器中。其中,R1指向数据包的起始地址,一般是skb指针。
第二条指令
/* Direct packet access, R0 = *(uint *) (skb->data + imm32) */#define BPF_LD_ABS(SIZE, IMM) \((struct bpf_insn) { \.code = BPF_LD | BPF_SIZE(SIZE) | BPF_ABS, \.dst_reg = 0, \.src_reg = 0, \.off = 0, \.imm = IMM })
在加载和存储指令中,寄存器 R6 是一个隐式输入,寄存器 R0 是一个隐式输出。
根据偏移量,读取IP协议类型,例如,TCP 的协议号为 6,UDP 的协议号为 17,ICMP 的协议号为 1。其中,协议字段占8位。
所以,BPF_LD_ABS这条指令表示,将 IP 协议值放入 R0 寄存器。
第三条指令
/* Memory store, *(uint *) (dst_reg + off16) = src_reg */#define BPF_STX_MEM(SIZE, DST, SRC, OFF) \((struct bpf_insn) { \.code = BPF_STX | BPF_SIZE(SIZE) | BPF_MEM, \.dst_reg = DST, \.src_reg = SRC, \.off = OFF, \.imm = 0 })
R10是唯一的只读寄存器,包含用于访问 BPF 堆栈空间的帧指针地址。(关于栈帧结构可以参考:gdb调试之栈帧信息)
这条指令意思是将R0寄存器中的内容(上一步保存了协议类型),保存到栈中。需要注意的是,这里是 BPF_W,只保存了 R0寄存器中的第32位。
第四条指令
BPF_MOV64_REG(BPF_REG_2, BPF_REG_10)
因为栈向下生长了。所以这里使用了 R2寄存器指向栈顶。
BPF_ALU64_IMM(BPF_ADD, BPF_REG_2, -4)/* ALU ops on immediates, bpf_add|sub|...: dst_reg += imm32 */#define BPF_ALU64_IMM(OP, DST, IMM) \((struct bpf_insn) { \.code = BPF_ALU64 | BPF_OP(OP) | BPF_K, \.dst_reg = DST, \.src_reg = 0, \.off = 0, \.imm = IMM })
上面的指令展开,便是一个64位的二进制数,r2-4的结果放在r2里。展开可以在 samples/bpf/bpf_insn.h 和 include/uapi/linux/bpf.h 中查看。
第五条指令
/* BPF_LD_IMM64 macro encodes single 'load 64-bit immediate' insn */#define BPF_LD_IMM64(DST, IMM) \BPF_LD_IMM64_RAW(DST, 0, IMM)#define BPF_LD_IMM64_RAW(DST, SRC, IMM) \((struct bpf_insn) { \.code = BPF_LD | BPF_DW | BPF_IMM,\.dst_reg = DST, \.src_reg = SRC, \.off = 0, \.imm = (__u32) (IMM) }), \((struct bpf_insn) { \.code = 0, \.dst_reg = 0, \.src_reg = 0, \.off = 0, \.imm = ((__u64) (IMM)) >> 32 })#ifndef BPF_PSEUDO_MAP_FD
#define BPF_PSEUDO_MAP_FD 1
#endif/* pseudo BPF_LD_IMM64 insn used to refer to process-local map_fd */
#define BPF_LD_MAP_FD(DST, MAP_FD) \BPF_LD_IMM64_RAW(DST, BPF_PSEUDO_MAP_FD, MAP_FD)
可以看到,这条指令是将 map_fd 的值,保存到R1寄存器中。这时候可能会好奇,这中间有 src_reg 什么事情?
上面可以看到,如果只是单纯将一个立即数保存到寄存器中,则 src_reg=0;如果这个立即数表示是一个 map_fd,则则 src_reg=1;
这样便可以区分指令中的立即数是否表示一个 map_fd。后面 replace_map_fd_with_map_ptr 函数会用到这个性质。
第六条指令
/* Raw code statement block */#define BPF_RAW_INSN(CODE, DST, SRC, OFF, IMM) \((struct bpf_insn) { \.code = CODE, \.dst_reg = DST, \.src_reg = SRC, \.off = OFF, \.imm = IMM })
其中BPF_FUNC_map_lookup_elem的宏展开为1。至于跳转到1的位置,在verifier后是bpf_map_lookup_elem这个函数,则是后续的问题了。可以参考:fixup_bpf_calls
这里,可以从宏的名称看出是是跳转到bpf_map_lookup_elem函数位置。
第七条指令
/* Conditional jumps against immediates, if (dst_reg 'op' imm32) goto pc + off16 */#define BPF_JMP_IMM(OP, DST, IMM, OFF) \((struct bpf_insn) { \.code = BPF_JMP | BPF_OP(OP) | BPF_K, \.dst_reg = DST, \.src_reg = 0, \.off = OFF, \.imm = IMM })
这条指令表示,R0寄存器 等于0,则向下跳过两个指令。
R0寄存器 这里存储的是协议号,根据 IP 协议号列表可知,但 IP 数据包中的协议为 “IPv6逐跳选项”,则向下跳过两个指令。
第八条指令
BPF_RAW_INSN(BPF_STX | BPF_XADD | BPF_DW, BPF_REG_0, BPF_REG_1, 0, 0)
xadd - 交换相加。
第九条指令
BPF_MOV64_IMM(BPF_REG_0, 0), /* r0 = 0 */
R0是包含 BPF 程序退出值的寄存器,设置返回值 R0=0。
第十条指令
/* Program exit */#define BPF_EXIT_INSN() \((struct bpf_insn) { \.code = BPF_JMP | BPF_EXIT, \.dst_reg = 0, \.src_reg = 0, \.off = 0, \.imm = 0 })
程序退出指令,使用BPF_EXIT
4、总结
本文详细介绍了eBPF的字节码和指令架构的定义,由具体的例子展开进行了深入分析,通过eBPF的字节码(指令集)有助于理解eBPF程序。在进行eBPF程序开发时,会遇到很多verifier的报错,经过学习本文后,通过读报错信息就可以清楚异常点的问题,对于进一步深入eBPF的开发有很大的帮助。
这篇关于万字长文让你深入了解BPF字节码 @龙蜥社区eBPF SIG的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






