本文主要是介绍Redis学习与入门----深度历险(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- redis操作数据的基础数据结构
- string
- list
- hash
- set
- zset(跳跃链表)
- redis分布式锁
- 分布式锁的使用
- 分布式锁的超时问题
- redis的简单延时队列
- redis的位图数据结构
- bitcount和bitpos
- HyperLogLog(高级数据结构)
- 布隆过滤器
- 布隆过滤器是什么
- 布隆过滤器的原理
- 布隆过滤器一些的常用场景
redis操作数据的基础数据结构
通俗易懂的Redis数据结构基础教程
string
string是键值对的形式。Redis是将值存在内存中的,其为了避免内存的频繁分配,提供了预分配内存空间的方法。当字符串是少于1M的时候,是两倍扩容的方式。当内存大于1M时,采用+1M的方式扩容。字符串的最大可用内存为512M。
set 变量名 值
get 变量名
获取子串:getrange 变量名 start end
覆盖子串:setrange 变量名 start end
在最后追加子串:append 变量名 子串值
用作计数器:1.incrby 变量名 加数2.decrby 变量名 减数3.不写默认增加或减少14.计数器是有范围的,它不能超过Long.Max,不能低于Long.MIN
设置过期时间:expire 变量名 时间(默认秒为单位)
查看剩余生命:ttl 变量名
删除变量:del 变量名
list
list结构,即链表结构,在redis中,提供的是双向链表。结合使用rpush/rpop/lpush/lpop四条指令,你可以将其作为队列形式,也可以只采用一端,形成栈的结构。
分为左和右:
rpush 链表名 值 值 值 ...
rpop 链表名
lpush 链表名 值 值 值 ...
lpop 链表名
计算链表长度: llen 链表名
通过下标访问链表:lindex 链表名 下标(从0开始)
通过lrange访问链表子串: lrange 链表名 start end
访问整个链表的方法:1.通过llen计算得到链表长度,lrange 链表名 0 链表长度-12.lrange 链表名 0 -1
更改指定链表下标的值:lset 链表名 下标 新值
在指定值前面或者后面插入值:linsert 链表名 before/after 指定值 插入值
删除指定值的元素:lrem 链表名 数量 删除值
定长链表的一个使用: 1.第一步:ltrim 链表名 起始下标 结束下标2.第二步:lrange 链表名 0 -1
hash
类似于JDK1.7的hashmap结构。以链表+数组的形式存储数据。
hset hash表名 key value
hmset hash表名 key value key value ....
hget hash表名 key
hmget hash表名 key key key ...
获取hash表中所有的键值对:hgetall hash表名
获取hash表中所有的key:hkeys hash表名
获取hash表中所有的value:hvals hash表名
删除key:hdel hash表名 key
判断key是否存在:hexits hash表名 key
hash也可以作为计数器来使用,只要每一个的值是整数:1.hincrby hash表名 key value(整数)2.如果value不是整数,使用hincrby会报错。
同hashmap一样,rehash是非常耗时的操作,所以redis的hash结构,采用的是渐进式的rehash。
rehash的时候,会保存新旧两个hash结构,查询的时候,同时查询两个结构,并在后面命令中,慢慢将旧hash中的值,传给新hash。当旧hash最后一个元素移除后,就删除该数据结构。
hash结构可以用来存储用户信息。不同于整个对象都要序列化的字符串,hash可以对用户的每个字段进行单独存储。减少了流量的浪费,但存储消耗高于字符串
set
Java程序员都知道HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
sadd 表名 元素 元素 元素 ...
列出集合元素: smembers 表名
获取集合长度: scard 表名
获取随机元素: srandmember 表名
删除一个或多个指定值的元素:hrem 表名 元素 元素 ...
随机删除一个元素:spop 表名
判断元素是否存在:sismember 表名 元素
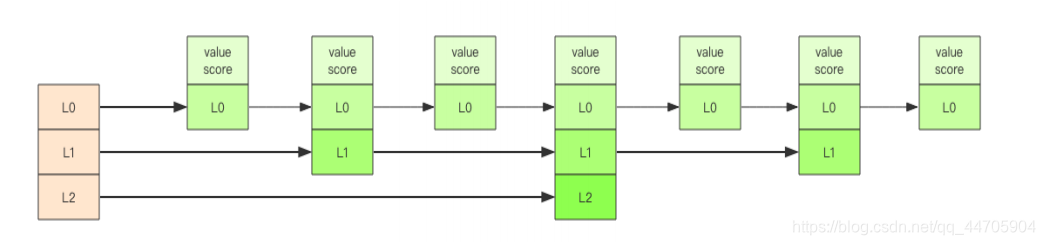
zset(跳跃链表)
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层实现使用了两个数据结构,第一个是hash,第二个是跳跃列表,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。跳跃列表的目的在于给元素value排序,根据score的范围获取元素列表
zadd 表名 score value score value ...
查看元素的权重:zscore 表名 value
正向查看元素,由小到大对元素进行排序(最小的返回0):zrank 表名 value
反向查看元素,由大到小对元素进行排序(最大的返回0):zrevrank 表名 value
根据score范围获取其中的元素列表:zrangebyscore 表名 起始值 结尾值
带有score的返回:zrangebyscore 表名 起始值 结尾值 withscores
返回整个表的,由小到大:zrangebyscore 表名 -inf +inf withscores
返回整个表的,由大到小:zrangebyscore 表名 +inf -inf withscores
移除范围内的元素:zremrangebyscore 表名 起始score 结束score
redis分布式锁
分布式应用在逻辑处理时经常会遇到并发问题。比如要修改内存中的一个对象的状态。那么步骤肯定大致分为三步,先读出该对象状态,再修改该对象状态,再将新状态写回内存。因为这样的操作不是原子操作,在并发情况下是很容易出现问题的。所以可以考虑使用分布式锁来限制程序的并发执行。
分布式锁的使用
- 最开始分布式锁采用setnx(set if not exists)的方法去锁住一个对象操作,只允许一个客户端(即一个线程)来操作。
- 后面发现如果在客户端获取到锁之后,却在中间发生了异常,导致锁没有释放,那么就会陷入死锁。所以我们可以在调用setnx后,再执行expire方法,对这个锁加上一个过期时间。但是如果异常发生在了setnx和expire之间,仍然会产生死锁,因为这两个操作并不是一个原子操作。
- 在redis2.8之后,redis中加入了set的扩展参数nx和ex。使得nx和ex成为了一个原子操作。命令如下

分布式锁的超时问题
分布式锁并不能解决超时问题,如果在加锁和释放锁中间的代码逻辑执行时间过长,导致还没有释放锁,这个锁就过期了。那么这个时候第二个线程就可以去向redis申请这个过期的锁作为自己的锁。这里就违背了redis锁的唯一性原则。
解决办法:
1.人工干预
2.使用lua脚本去给redis服务器发送请求,申请延时锁的释放时间。
redis的简单延时队列
因为list的数据结构,所以redis可以用来做一个简单的延时队列。
客户端通过redis的延时队列pop来获取消息,然后进行处理,如果该队列空了, 那么客户端就会陷入pop的死循环,也就是空轮询,这会拉高客户端的cpu,也会拉高redis的QPS。
解决的办法:
1.可以sleep当前线程一会
2.但即使sleep的再短,也会造成一定的延时,所以可以使用阻塞读,blpop。阻塞读会在队列没有数据的时候,进入休眠状态,当数据到来时,立马醒过来。
3.如果一直阻塞,那么就会造成空闲连接问题,闲置过久,redis可能会主动断开该连接,以减少闲置资源占用,这个时候blpop会抛出异常。所以客户端要注意捕获异常。
redis的位图数据结构
假设有这么一个场景,统计用户一年的签到记录,如果用缓存实现,那么就要记录365天,如果使用普通的key value,那么就是365个key value,那么当用户增多,这个存储空间是会很大的。
为了解决上述问题,redis提供了位图数据结构。这样每一个签到(以0或1)就只占一个位,一年就是365个位,即46个字节,那么就大大节约了存储空间。
注意:二进制码的顺序是从右往左,我们数组里的顺序是从左往右
下面根据hello的ASCII码,将其存入位图结构
#以h为例
#h的ASCII码转成二进制后,就是01101000
#我们只需要设置1的值
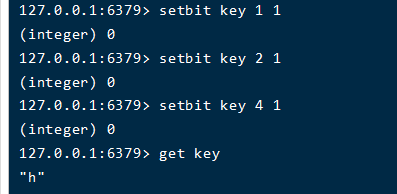
setbit key 位置 1
#上面的位置指的就是1的位置,对于h来说,那么就是1、2、4位(这里得注意,二进制码的顺序是从右往左,我们数组里的顺序是从左往右)。
#所以对于h的设置
setbit key 1 1
setbit key 2 1
setbit key 4 1
get key 打印会发现是h,如下图所示
再继续对key插入e的bit,那么就如下图一样
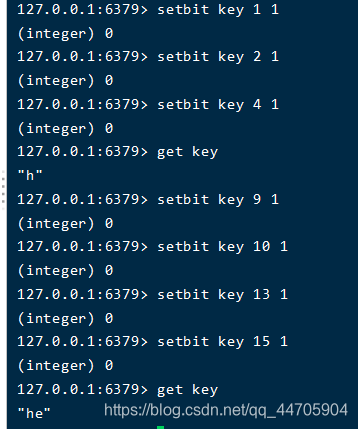
上面的操作可以理解为“零存整取”,即存的是字节,取的是字符。
那么当然也可以零存零取,整存零取
- 对于整存零取,我们set a b
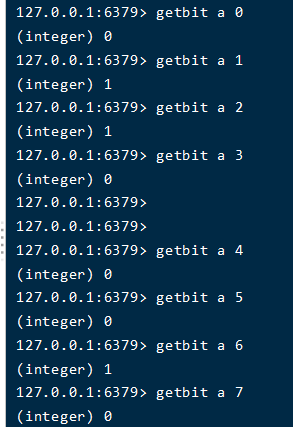
可以发现,获取8个位之后,组合之后是01100010,对应的值是不是97,不正是a吗? - 对于零存零取,只设置了b的第一位是1,所以取第二位是返回的是0

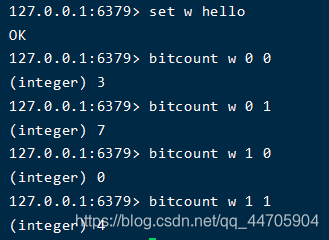
bitcount和bitpos
- bitcount用来查找指定字符范围内出现的1的次数
bitcount key start end
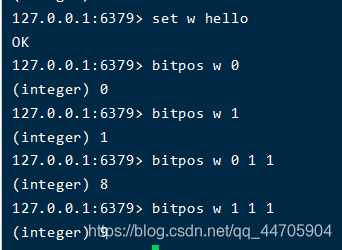
- bitpos用来查找指定字符范围内的第一个位的的位置
HyperLogLog(高级数据结构)
Redis 提供了 HyperLogLog 数据结构就是用来解决这种统计问题的。HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,标准误差是 0.81%,HyperLogLog 数据结构是 Redis 的高级数据结构。
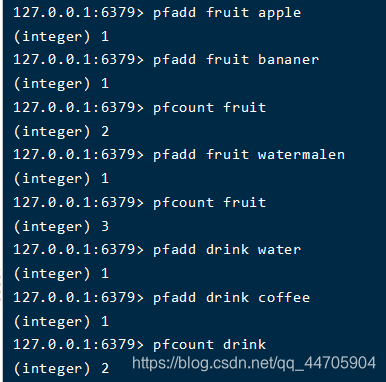
其常用操作有pfadd,pfcount,pfmerge。pfmerge用于合并多个pfadd的值。
HyperLogLog可以用于大量用户相关的数据。对比set存储,可以说是非常高效的。其只需要占据12k的存储空间。这个可以解决许多精确不高的统计需求。
pfadd的用法类似于set集合的sadd,放入数据,计数+1
pfcount获取当前计数。
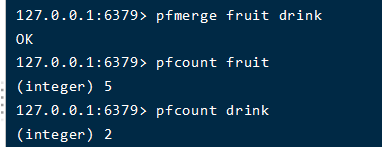
使用pfmerger,将指定的key当前的里面的元素数量追加到前面的指定的key的元素数量上。这个时候fruit的计数就变成了5,但其内部元素还是3
布隆过滤器
HyperLogLog这样的数据结构可以用来估计大概的值。但如果我们想知道某一个值是不是存在于其中,HyperLogLog并没办法做到这一点。
讲一个使用场景,我们在使用某app看推荐内容的时候,系统会自动推荐新的内容,它需要去重我们看过的内容,那么它是怎么实现的去重?
1、如果是遍历整个服务器的历史记录,将其存入数据库,那么对于数据库的exists查询请求就很频繁了,当并发量高的时候,数据库可能就会扛不住。
2、如果将整个缓存起来,那么浪费的存储空间太大了。时间一长,不仅存不下,性能也会下降。
这个时候,就可以采用布隆过滤器,可以专门解决这类问题,在达到去重的同时,在空间上还能节省90%以上。
布隆过滤器是什么
可以将其理解成一个不怎么精确的set结构。当我们使用它的contains方法判断某个对象是否存在时,它可能会误判。但可以人为将这个误判的几率调到很小。
布隆过滤器对于去重是这样的。它认为没见过的就一定是没见过的,它认为见过的(去重),那么可能是它没见过的(因为一些长得比较像的系数组合,导致它误以为它见过,这也是精度误差所在)。
Redis提供的布隆过滤器在Redis4.0提供插件功能之后才正式登场。
可以通过调整bf.reserve的参数来更改误判率。bf.reserve有三个参数,分别是key,error_rate(默认0.01),initial_size(默认100)。
布隆过滤器的error_rate(错误率)越小,需要的initial_size的值就越大。但initial_size的值越大,会浪费存储空间,估计的过小,影响准确率。所以在使用布隆过滤器前,要尽可能的精确估计好元素数量,还需要加上一定的冗余空间,避免实际元素数量大于估计元素数量。
布隆过滤器的原理
内部其实是一个位数组和多个散列性极好的hash函数。当要添加一个key时,就会经过多个hash散列函数的计算,得出具体的存放位置, 将具体的存放位置改为1。当需要查询该key时,也要通过多个hash函数去计算,对比每一个位置上是不是都是1,如果有一个不是,那么就判断该key不存在。
这个位数组越长,错误率越低,需要的hash函数的最佳数量也会增多,影响计算的效率。
可以通过网页上的布隆计算器,计算出具体的数值
布隆过滤器一些的常用场景
- 可以用在爬虫去重网页URL上。
- redis的缓存穿透,就是可以通过布隆过滤器来过滤掉大多数无用的请求。来降低数据库压力的。
这篇关于Redis学习与入门----深度历险(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







