本文主要是介绍2023年阿里巴巴信息检索(搜推广)技术论文整理汇总-KDD,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
省时查报告-专业、及时、全面的行研报告库
省时查方案-专业、及时、全面的营销策划方案库
2024届高校毕业生抽样调研报告.pdf
2023届高校毕业生薪酬研究报告.pdf
【免费下载】2023年9月份全网热门报告合集
千模大战:百家争鸣OR一地鸡毛?
OpenAI:GPT最佳实践(大白话编译解读版)
ChatGPT提词手册,学完工作效率提升百倍
马斯克谈AI:中美差距12个月,出现AGI只要三五年
万字干货:ChatGPT的工作原理
2023年创业(有创业想法)必读手册
ChatGPT调研报告(仅供内部参考)
2023年AIGC发展趋势报告:人工智能的下一时代
《底层逻辑》高清配图
又到年底,我们开始准备总结2023年国内外各大厂信息检索(搜索、推荐、广告)技术的进展和趋势。作为第一步,我们会先系统整理一下各个大厂这一年的所有信息检索相关的论文。

ChatGPT4国内可以直接访问的链接,无需注册,无需翻墙,支持编程等多个垂直模型,点开即用:
https://ai.zntjxt.com(复制链接电脑浏览器或微信中点开即可,也可扫描下方二维码直达)阿里巴巴信息检索(搜推广)技术论文2023
面向公平感知网络广告的个性化自动竞价框架. A Personalized Automated Bidding Framework for Fairness-aware Online Advertising, KDD 2023.


在机器学习技术的推动下,在线广告平台推出了各种自动竞价策略服务,以促进广告主做出智能决策。然而,广告主所处的广告环境各不相同,因此在学术界和产业界广泛使用的统一竞价策略存在严重的不公平问题,导致广告主之间的广告效果差异显著。在这项工作中,为了解决不公平问题并提高系统的整体性能,我们提出了一种个性化自动竞价框架,即 PerBid,将传统的统一代理自动竞价策略转变为多个情境感知代理,分别对应不同的广告主集群。具体来说,我们首先设计了一个广告活动剖析网络来模拟动态广告环境。通过对具有相似特征的广告商进行聚类,并为每个聚类生成情境感知自动竞价代理,我们可以为广告商匹配个性化的自动竞价策略。在阿里巴巴展示广告平台的真实数据集和在线 A/B 测试中进行的实验证明,PerBid 在提高整体广告性能和保证异构广告主之间的公平性方面非常有效。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599765利用情境化混合模型对排序和校准进行联合优化. Joint Optimization of Ranking and Calibration with Contextualized Hybrid Model, KDD 2023.

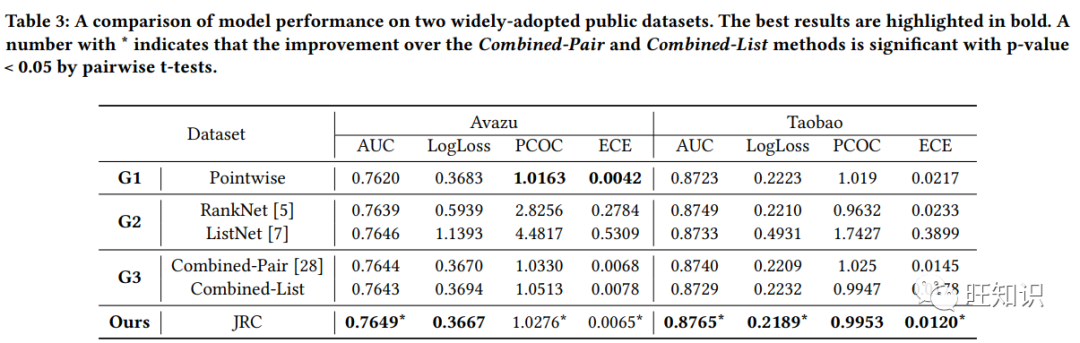
尽管排名优化技术不断发展,但点损失仍是预测点击率的主要方法。这可以归因于点式损失的校准能力,因为预测结果可以看作是点击概率。在实践中,点击率预测模型通常也会用排名能力来评估。为了优化排名能力,可以采用排名损失(如配对损失或列表损失),因为它们通常比点式损失获得更好的排名。以往的研究尝试将两种损失直接结合起来,以获得两种损失的益处,并观察到性能有所提高。然而,以往的研究打破了输出对数作为点击率的含义,这可能会导致次优解决方案的出现。为了解决这个问题,我们提出了一种可以联合优化排名和校准能力(简称 JRC)的方法。JRC 通过对比不同标签样本的 logit 值来提高排序能力,并将预测概率限制为 logit 减法的函数。我们进一步证明,JRC 巩固了对数的解释,即对数是联合分布的模型。通过这种解释,我们证明了 JRC 近似优化了上下文混合判别-生成目标。在公共和工业数据集上的实验以及在线 A/B 测试表明,我们的方法提高了排名和校准能力。自 2022 年 5 月以来,JRC 已部署在阿里巴巴的展示广告平台上,并取得了显著的性能改进。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599851一种新颖的历史数据重用方法捕捉促销期间的转化率波动. Capturing Conversion Rate Fluctuation during Sales Promotions: A Novel Historical Data Reuse Approach, KDD 2023.



转换率(CVR)预测是在线推荐系统的核心组件之一,人们提出了各种方法来获得准确且校准良好的 CVR 估计。然而,我们发现,训练有素的 CVR 预测模型在促销活动中的表现往往不尽如人意。这在很大程度上归因于数据分布偏移的问题,在这种情况下,传统方法不再奏效。为此,我们试图为 CVR 预测开发替代建模技术。观察到不同促销活动中相似的购买模式,我们建议重新利用历史促销数据来捕捉促销活动的转换模式。在此,我们提出了一种新颖的历史数据重用(HDR)方法,首先检索历史上类似的促销数据,然后利用获取的数据对 CVR 预测模型进行微调,以更好地适应促销模式。HDR 由三个部分组成:自动数据检索模块,用于从历史促销活动中寻找类似数据;分布偏移校正模块,用于对检索到的数据重新加权,以便更好地与目标促销活动保持一致;以及 TransBlock 模块,用于快速微调原始模型,以便更好地适应促销模式。利用真实世界数据进行的实验证明了 HDR 的有效性,因为它在很大程度上提高了排名和校准指标。在阿里巴巴的展示广告系统中也部署了 HDR,在 2022 年双 11 促销期间提升了 9% 的 RPM 和 16% 的 CVR。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599788实现列车换乘计划的个性化排名. PlanRanker: Towards Personalized Ranking of Train Transfer Plans, KDD 2023.



由于高铁技术的蓬勃发展和在线预订火车的便利,火车换乘计划排名已成为在线旅行平台(OTP)的核心业务。目前,主流 OTP 采用基于规则或简单偏好的策略对火车换乘计划进行排序。然而,由于对计划成本的重视程度不够,以及对参考换乘计划的忽略,使得这些现有策略在解决列车换乘计划的个性化排序问题上效果不佳。为此,本文提出了一种新型个性化深度网络(Plan- Ranker),以更好地解决这一问题。在 PlanRanker 中,我们首先提出了一个个性化学习组件,通过用户的行为日志数据来捕捉查询语义和目标换乘计划--用户的相关个性化兴趣。然后,我们提出了成本学习组件,其中强调并学习目标转移计划的价格成本和时间成本。最后,我们设计了一个参考转移计划学习组件,使 PlanRanker 的整个框架能够从参考转移计划中学习,这些计划是由平台用户拼凑而成的,从而反映了群众的智慧。PlanRanker 目前已成功部署在阿里巴巴 Fliggy 上,这是中国最大的 OTP 之一,每天为数百万用户提供火车票预订服务。Fliggy 在两个生产数据集上的离线实验和全国范围的在线 A/B 测试都证明了 PlanRanker 的优越性。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599887重新审视个性化联合学习:抵御后门攻击的稳健性. Revisiting Personalized Federated Learning: Robustness Against Backdoor Attacks, KDD 2023.

在这项工作中,除了提高预测准确性之外,我们还研究了个性化是否能为后门攻击带来鲁棒性优势。我们首次研究了 pFL 框架中的后门攻击,在基准数据集 FEMNIST 和 CIFAR-10 上针对 6 种 pFL 方法测试了 4 种广泛使用的后门攻击,共进行了 600 次实验。研究结果表明,部分模型共享的 pFL 方法能显著提高抵御后门攻击的鲁棒性。相比之下,完全模型共享的 pFL 方法则没有表现出鲁棒性。为了分析不同鲁棒性表现的原因,我们对不同的 pFL 方法进行了全面的消融研究。在此基础上,我们进一步提出了一种轻量级防御方法--简单调整(Simple-Tuning),该方法根据经验提高了对后门攻击的防御性能。我们相信,我们的工作既能在稳健性方面为 pFL 应用提供指导,也能为未来设计更稳健的 FL 方法提供有价值的见解。我们开源了我们的代码,建立了首个 pFL 黑盒后门攻击基准:https://github.com/alibaba/FederatedScope/tree/backdoor-bench。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599898基于特征的联盟博弈框架与用户标签画像建模的知识转移. A Feature-Based Coalition Game Framework with Privileged Knowledge Transfer for User-tag Profile Modeling, KDD 2023.



在现代推荐系统中,用户标签剖析是挖掘用户属性的一种有效方法。然而,由于用户输入的特征模式不完整,以往的研究无法精确提取用户对项目中标签的偏好。为了将用户与物品的交互转化为用户对标签的偏好,我们提出了一种新颖的基于特征的框架,名为联盟标签多视图映射(CTMVM),该框架识别并研究了两个特殊的特征,即联盟特征和特权特征。前者表示每次点击中的决定性标签,其中一个项目中标签之间的关系被视为联盟博弈。后者表示只在训练过程中出现的高信息量特征。对于联盟特征,我们采用基于 Shapley 值的授权(SVE),以博弈论范式对项目中的标签进行建模,并使网络直接掌握用户对重要标签的偏好。对于特权特征,我们提出了特权知识映射(Privileged Knowledge Mapping,PKM),明确地将每个标签的特权特征知识提炼为一个单一的嵌入,这有助于模型在更精细的层次上预测用户-标签偏好。然而,单一嵌入的贫瘠容量限制了每个标签与不同特权特征之间的多样化关系。因此,我们进一步提出了自适应多视图映射(AMVM)模型,通过处理多个映射网络来增强效果。在两个公共数据集和一个私有数据集上的出色离线实验结果表明,CTMVM 性能卓越。在阿里巴巴大型推荐系统上部署后,CTMVM 在主题点击率(Theme-CTR)和项目点击率(Item-CTR)方面分别提高了 10.81% 和 6.74%,这验证了在训练中吸收这两个特定特征的有效性。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599761实现真实世界的跨设备联邦学习. FS-REAL: Towards Real-World Cross-Device Federated Learning, KDD 2023 .


联邦学习(Federated Learning,FL)旨在与分布式客户端合作训练高质量模型,同时不上传其本地数据,这在学术界和工业界都引起了越来越多的关注。然而,蓬勃发展的 FL 研究与现实世界的应用场景之间仍存在相当大的差距,这主要是由异构设备的特性及其规模造成的。现有的大多数工作都是在同质设备上进行评估,这与现实世界中异质设备的多样性和可变性不匹配。此外,由于资源有限和软件栈复杂,利用异构设备进行大规模研发具有挑战性。这两个关键因素非常重要,但在 FL 研究中却未得到充分探索,因为它们直接影响 FL 的训练动态和最终性能,使 FL 算法的有效性和可用性变得模糊不清。为了弥补这一差距,我们在本文中提出了一种高效、可扩展的真实世界跨设备 FL 原型系统 FS-REAL。它支持异构设备运行时,包含并行性和鲁棒性增强的 FL 服务器,并为个性化、通信压缩和异步聚合等高级 FL 实用功能提供实现和扩展。为了证明 FS-REAL 的可用性和效率,我们在各种设备分布情况下进行了大量实验,量化并分析了异构设备和各种规模的影响,并进一步提供了有关真实 FL 应用场景的见解和开放讨论。我们的系统的发布将有助于为进一步的实际 FL 研究和涉及不同设备和规模的广泛应用铺平道路。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599829预载广告中延迟印象建模的强化学习. RLTP: Reinforcement Learning to Pace for Delayed Impression Modeling in Preloaded Ads, KDD 2023.


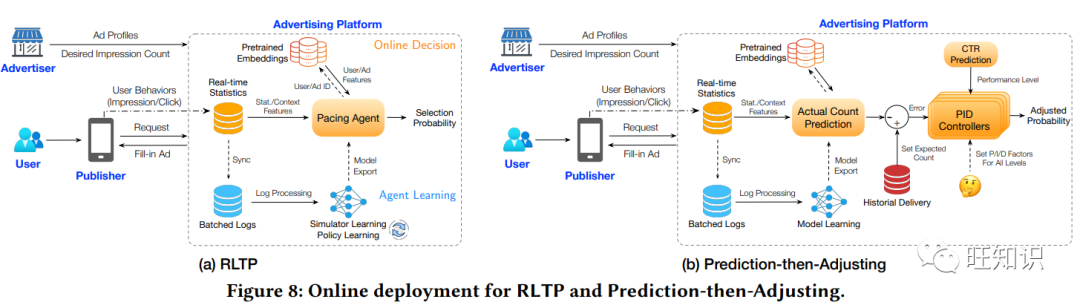
为了提高品牌知名度,许多广告商与广告平台签订合同,购买流量并向目标受众投放广告。在整个投放期内,广告商希望获得一定的广告印象数,并希望投放效果越好越好。广告平台采用实时步调算法来满足要求。不过,投放程序也会受到发布商的影响。预加载是许多类型广告(如视频广告)广泛使用的一种策略,以确保显示的响应时间是合法的,这导致了延迟印象现象。在本文中,我们重点研究了预载广告的印象步调这一新问题,并提出了强化学习步调框架 RLTP。它能学习一个步调代理,在整个投放期按顺序产生选择概率。为了共同优化印象数量和投递性能这两个目标,RLTP 采用了量身定制的奖励估算器,以满足保证印象数量、惩罚超量投递并最大化流量价值的要求。在大规模数据集上的实验验证了 RLTP 的性能大大优于基线。我们已将其在线部署到我们的广告平台上,并显著提高了交付完成率和点击率。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599900通过因果关系感知强化学习的最小回退优化进行对抗性受限竞标. Adversarial Constrained Bidding via Minimax Regret Optimization with Causality-Aware Reinforcement Learning, KDD 2023.


随着互联网的普及,在线广告在在线拍卖机制的推动下应运而生。在这些反复进行的拍卖中,软件代理代表聚集在一起的广告商参与其中,以优化他们的长期效用。为了满足不同的需求,我们采用竞价策略来优化广告目标,但又受到不同的支出限制。现有的约束竞价方法通常依赖于 i.i.d. 训练和测试条件,这与在线广告市场的对抗性质相矛盾,因为不同的参与者拥有潜在的冲突目标。为此,我们探讨了对抗性竞价环境下的限制性竞价问题,并假设对对抗性因素一无所知。与依赖 i.i.d. 假设不同,我们的见解是使环境的列车分布与潜在的测试分布保持一致,同时使策略遗憾最小化。基于这一观点,我们提出了一种实用的最小遗憾优化(MiRO)方法,该方法在教师寻找对抗环境进行辅导和学习者在给定的环境分布上元学习其策略之间交错进行。此外,我们还率先将专家示范纳入竞标策略的学习中。通过因果关系感知策略设计,我们从专家那里提炼知识,从而改进了 MiRO。在工业数据和合成数据上进行的广泛实验表明,我们的方法--具有因果关系感知强化学习功能的 MiRO(MiROCL)--比之前的方法优胜 30% 以上。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599254序列即基因:电子商务欺诈交易检测的用户行为建模框架, Sequence As Genes: An User Behavior Modeling Framework for Fraud Transaction Detection in E-commerce, KDD 2023.

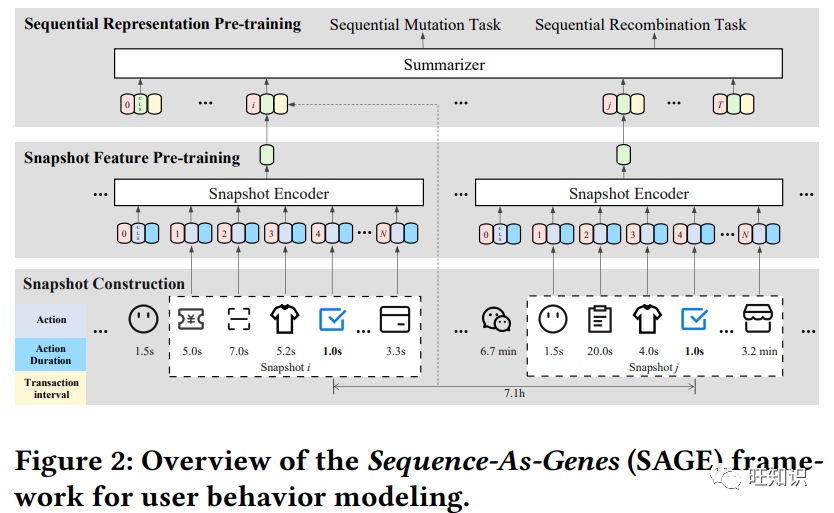

随着电子商务的爆炸式增长,检测真实世界场景中的欺诈交易对电子商务平台变得越来越重要。用户行为序列记录了用户在平台上的活动轨迹,包含丰富的欺诈交易检测信息。然而,这些方法始终受到真实世界场景中标记数据稀缺的困扰。最近在自然语言处理(NLP)和计算机视觉(CV)领域出现的令人瞩目的预训练方法带来了一线曙光。然而,用户行为序列与文本、图像和视频有着本质区别。在本文中,我们提出了一个新颖、通用的用户行为预训练框架,名为 "序列基因"(Sequence As GEnes,SAGE),它为用户行为建模提供了一个新的视角。受将序列视为基因的启发,我们精心设计了用户行为数据组织范式和预训练方案。具体来说,我们从 DNA 表达的本质中汲取灵感,提出了一种高效的数据组织范式,将行为序列的长度与相应的时间跨度分离开来。同样受遗传学中自然机制的启发,我们提出了两个预训练任务,即序列突变和序列重组,以提高复杂真实世界场景中用户行为表征的鲁棒性和一致性。在四个差异化欺诈交易检测真实场景中进行的大量实验证明了我们提出的框架的有效性。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599905利用全生命周期行为建模增强通用用户表示能力, Empowering General-purpose User Representation with Full-life Cycle Behavior Modeling, KDD 2023.



用户建模在工业领域发挥着至关重要的作用。在这一领域,与特定任务的表征学习相比,生成适用于下游各种用户认知任务的通用表征的任务无关方法更具价值和经济性,是一个很有前途的方向。随着互联网服务平台的快速发展,用户行为不断积累。然而,现有的通用用户表征研究几乎无法对用户注册以来的超长行为序列进行全生命周期建模。在本研究中,我们提出了一个名为全生命周期用户表征模型(LURM)的新框架来应对这一挑战。具体来说,LURM 由两个级联子模型组成:(romannumeral1)兴趣袋(Bag-of-Interests,BoI)将任意时间段内的用户行为编码成一个超高维度(\textite. \textitg. , 10^5 )的稀疏向量;(romannumeral2)自监督多锚编码器网络(Self-supervised Multi-anchor Encoder Network,SMEN)将 BoI 特征序列映射到多个低维用户表征。特别值得一提的是,SMEN 实现了几乎无损的降维,这得益于一个新颖的多锚(multi-anchor)模块,该模块可以学习用户兴趣的不同方面。在多个基准数据集上的实验表明,我们的方法优于最先进的通用表示方法。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599331具有曝光限制的多渠道综合推荐, Multi-channel Integrated Recommendation with Exposure Constraints, KDD 2023.


综合推荐旨在联合推荐主馈中来自不同渠道的异构项目,已被广泛应用于各种在线平台。虽然综合推荐很有吸引力,但它要求排序方法从传统的用户-项目模型迁移到新的用户-渠道-项目范式,以便更好地捕捉用户在项目和渠道两个层面的偏好。此外,实际的饲料推荐系统通常会对不同渠道施加曝光限制,以确保用户体验。这给异构项目的联合排序带来了更大的困难。在本文中,我们研究了实用推荐系统中带有曝光约束的综合推荐任务。我们的贡献有四个方面。首先,我们将这一任务表述为二元在线线性规划问题,并提出了一个名为 "带曝光约束的多渠道综合推荐"(MIREC)的双层框架,以获得最优解。其次,我们提出了一种高效的在线分配算法,从整个时间跨度内所有用户请求的全局视角来确定不同频道的最佳曝光分配。我们证明,该算法能以线性复杂度在 O (√T) 的遗憾约束下达到最优点。第三,我们提出了一系列协作模型来确定每个用户请求的异构物品的最佳布局。在我们的模型中,用户兴趣、跨渠道相关性和页面上下文的联合建模比现有模型更符合饲料产品的浏览性质。最后,我们在离线数据集和线上 A/B 测试中进行了大量实验,以验证 MIREC 的有效性。目前,所提出的框架已在淘宝网首页上实施,为主要流量提供服务。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599868通过内容协作图神经网络进行电子商务搜索, E-commerce Search via Content Collaborative Graph Neural Network, KDD 2023.


最近,许多电子商务搜索模型都基于图神经网络(GNN)。尽管这些模型性能良好,但它们存在以下问题:(1) 缺乏对产品内容的适当语义表示;(2) 对于行业规模的图形效率较低;(3) 对于长尾查询和冷启动产品的准确性较低。为了同时解决这些问题,本文提出了一种新型内容协作图神经网络 CC-GNN。首先,CC-GNN 使内容短语明确参与图传播,以捕捉短语的正确含义和语义漂移。其次,CC-GNN 为实现更具可扩展性的图学习框架做出了多项努力,包括高效的图构建、元路径引导的消息传递以及用于图对比学习的难度感知表征扰动(Difficulty-aware Representation Perturbation)。此外,CC-GNN 在监督学习和对比学习中都采用了反事实数据补充,以解决长尾/冷启动问题。在一个包含 1 亿个节点的真实电子商务数据集上进行的大量实验表明,CC-GNN 比现有方法有显著改进(即在总体、长尾查询和冷启动产品的几个关键评价指标上都有 10% 以上的改进),同时降低了计算复杂度。所提出的 CC-GNN 组件可应用于搜索和推荐任务的其他模型。在公共数据集上的实验表明,应用所提出的组件可以提高不同推荐模型的性能。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599320多因素顺序重新排序与感知多样化, Multi-factor Sequential Re-ranking with Perception-Aware Diversification, KDD 2023.



Feed 推荐系统推荐一系列项目供用户浏览和互动,在实际应用中得到了极大的普及。在 Feed 产品中,用户往往会连续浏览大量条目,因此之前浏览过的条目会对用户后续条目的行为产生重大影响。因此,主要关注提高推荐条目的准确性的传统方法对于饲料推荐来说并不理想,因为它们可能会推荐高度相似的条目。对于 Feed 推荐来说,关键是要同时考虑推荐项目序列的准确性和多样性,以满足用户在连续浏览项目时不断变化的兴趣。为此,本研究提出了一个通用的重新排序框架,名为 "感知多样化的多因素顺序重新排序"(MPAD),以顺序的方式共同优化 Feed 推荐的准确性和多样性。具体来说,MPAD 首先通过基于图聚类的聚合,从用户的行为序列中提取出他们不同程度的兴趣。然后,MPAD 提出了两个子模型,分别评估给定项目的准确性和多样性,这两个子模型从项目序列的角度捕捉了用户因不断变化的上下文而不断发展的兴趣和用户对多样性的个人感知。这与 feed 场景的浏览性质是一致的。最后,MPAD 通过从候选集中依次选择最优项目来生成返回列表,从而最大限度地提高整个列表的准确性和多样性。MPAD 已在淘宝网的首页 feed 中实现,为主要流量提供服务,每天向数亿用户推荐数十亿件商品。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599869保证交付广告的端到端库存预测与合同分配, End-to-End Inventory Prediction and Contract Allocation for Guaranteed Delivery Advertising, KDD 2023.
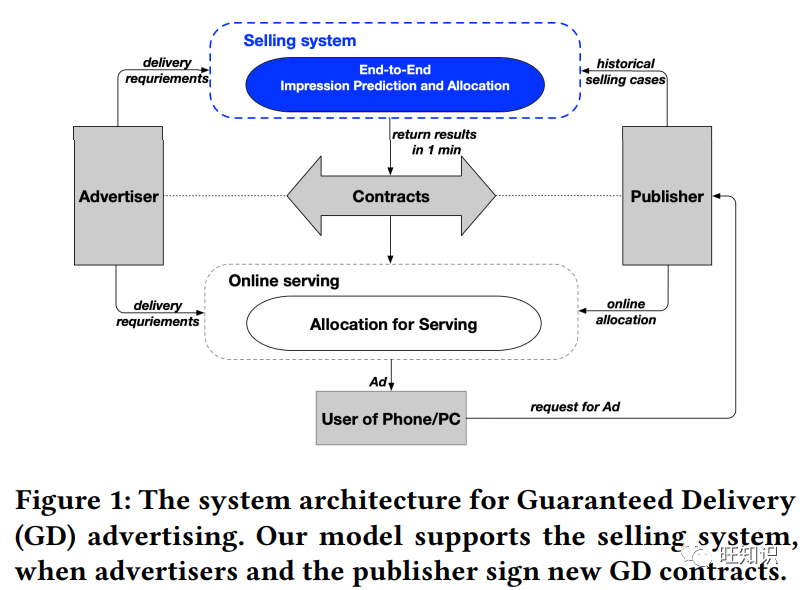

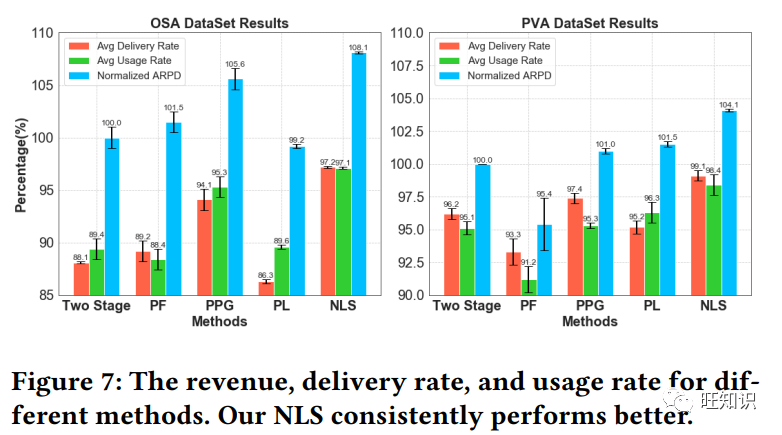
保证交付(GD)广告在电子商务营销中起着至关重要的作用,广告发布商事先与广告客户签订合同,承诺交付广告印象,以满足广告客户的目标要求。以往对广东广告的研究主要集中在在线服务方面,但忽略了广东销售阶段合同分配的重要性。传统的广东销售方法将印象库存预测和合同分配视为两个独立的阶段。然而,这种两阶段优化往往会导致合同分配效果不佳。在本文中,我们的目标是通过一种新颖的端到端方法来缩小这种性能差距。具体来说,我们提出了神经拉格朗日销售(NLS)模型,以统一的学习目标联合预测广告印象库存并优化广告印象的合约分配。为此,我们首先开发了一个可变拉格朗日层,通过神经网络反向传播分配问题,并允许直接优化分配遗憾。然后,为了在各种分配目标和约束条件下进行有效优化,我们设计了一个图卷积神经网络,从双向分配图中提取预测特征。大量实验表明,与现有的两阶段方法相比,我们的方法可以提高广东销售业绩。特别是,我们的优化层在计算效率和求解质量上都优于基线求解器。据我们所知,这是第一项将端到端预测和优化方法应用于工业广东销售问题的研究。我们的工作对一般的预测和分配问题也有借鉴意义。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599332利用政策超网络进行可控多目标重新排序, , KDD 2023.
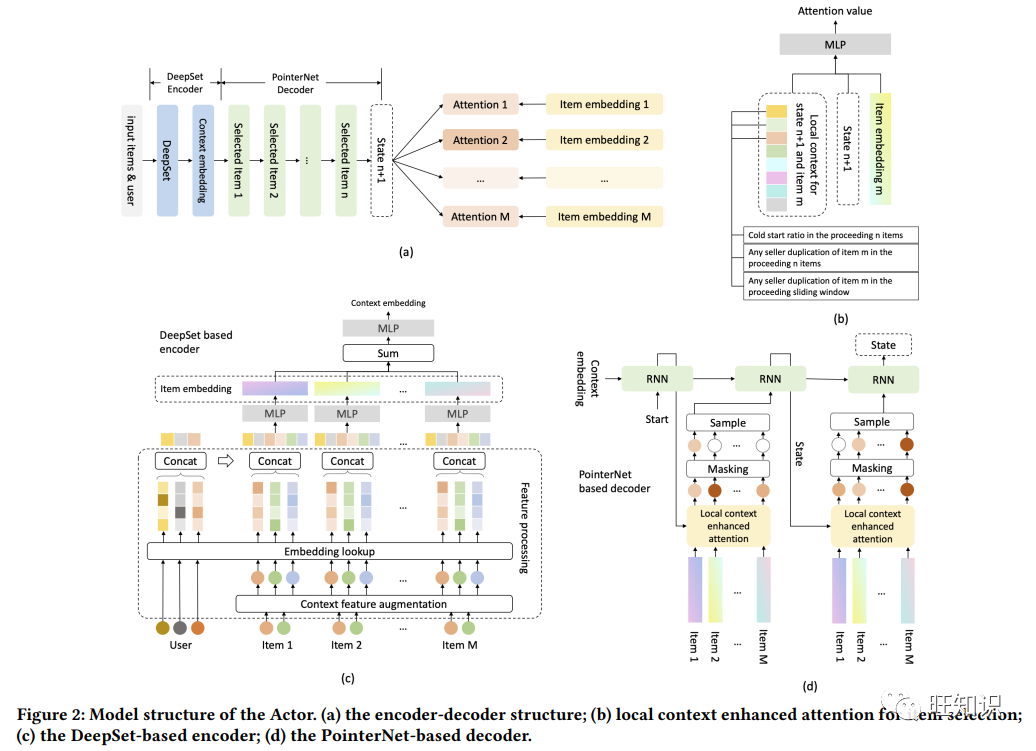

多阶段排序管道已成为现代推荐系统中广泛使用的策略,其最后阶段的目标是返回一个项目排序列表,该列表应平衡用户偏好、多样性、新颖性等多项要求。线性标量化可以说是应用最广泛的技术,它通过对具有一定偏好权重的需求进行求和,将多个需求合并为一个优化目标。现有的最终阶段排序方法通常采用静态模型,即在离线训练时确定偏好权重,并在在线服务时保持不变。每当需要修改偏好权重时,就必须重新训练模型,这既浪费时间又浪费资源。同时,对于不同的目标用户群或不同的时间段(如节假日促销期间),最合适的权重可能会有很大不同。在本文中,我们提出了一个名为 "可控多目标重新排序"(CMR)的框架,该框架结合了一个超网络,可根据不同的偏好权重为重新排序模型生成参数。这样,CMR 就能根据环境变化在线调整偏好权重,而无需重新训练模型。此外,我们还将面向商业的实际任务分为四大类,并将其无缝纳入基于 "演员-评估者 "框架的新建议重新排序模型中,该框架可作为 CMR 可靠的现实世界测试平台。基于淘宝应用收集的数据集进行的离线实验表明,CMR 将几种流行的重新排序模型用作底层模型,从而改进了这些模型。在线 A/B 测试也证明了 CMR 的有效性和可信度。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599796POI标签的多模式模型, M3PT: A Multi-Modal Model for POI Tagging, KDD 2023.



兴趣点标记旨在为兴趣点(POI)标注一些信息标签,从而方便与兴趣点相关的许多服务,包括搜索、推荐等。现有的大多数解决方案都忽视了兴趣点图像的重要性,也很少融合兴趣点的文字和视觉特征,导致标记效果不理想。在本文中,我们提出了一种新颖的 POI 标记多模态模型,即 M3PT,它通过融合目标 POI 的文本和视觉特征以及多模态表征之间的精确匹配来实现增强型 POI 标记。具体来说,我们首先设计了一个领域自适应图像编码器(DIE),以获得与黄金标签语义一致的图像嵌入。然后,在 M3PT 的文本-图像融合模块(TIF)中,将文本和视觉表征完全融合到 POI 的内容嵌入中,以便进行后续匹配。此外,我们还采用了对比学习策略,进一步缩小不同模态表征之间的差距。为了评估标记模型的性能,我们从阿里 Fliggy 的真实商业场景中构建了两个高质量的 POI 标记数据集。在这些数据集上,我们进行了大量实验,以证明我们的模型相对于单模态和多模态基线的优势,并验证 M3PT 中重要组件的有效性,包括 DIE、TIF 和对比学习策略。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599862具有外部性的基于学习的广告拍卖设计:框架和基于匹配的方法, Learning-Based Ad Auction Design with Externalities: The Framework and A Matching-Based Approach, KDD 2023.
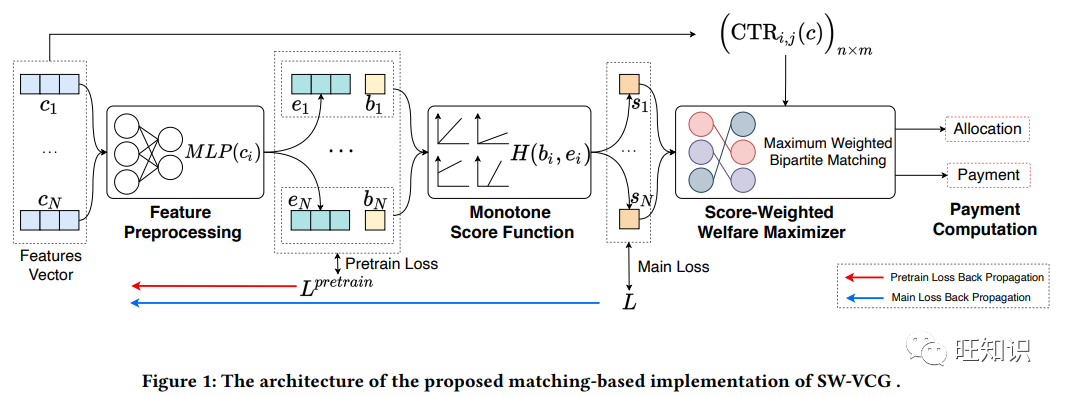
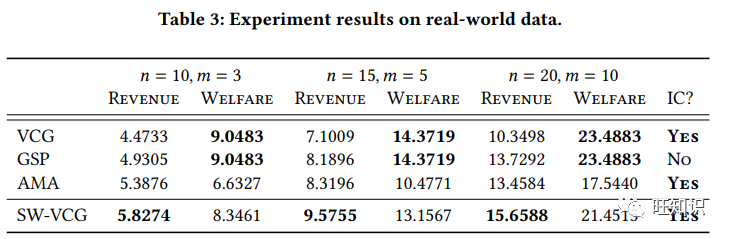
基于学习的广告拍卖已越来越多地应用于在线广告。然而,现有的方法忽视了外部性,如广告与有机物品之间的互动。在本文中,我们提出了一个通用框架,即分数加权 VCG,用于设计考虑外部性的基于学习的广告拍卖。该框架将最优拍卖设计分解为两个部分:设计单调的分数函数和分配算法,这为数据驱动的实施提供了便利。理论结果表明,在各种外部性感知的点击率模型下,该框架都能产生最佳的激励兼容和个体理性广告拍卖,同时还具有数据效率和鲁棒性。此外,我们还提出了一种利用基于匹配的分配算法实现所提框架的方法。在真实世界和合成数据上的实验结果表明了所提方法的有效性。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599403联合预训练和局部再训练:多源知识图谱上的可迁移表征学习, Joint Pre-training and Local Re-training: Transferable Representation Learning on Multi-source Knowledge Graphs, KDD 2023.
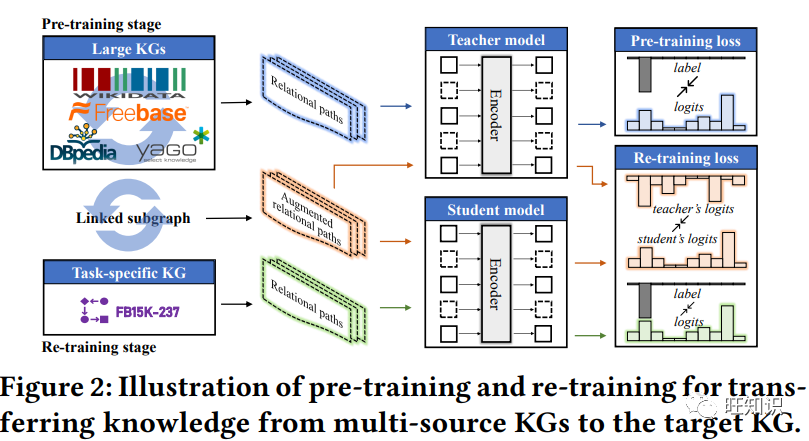
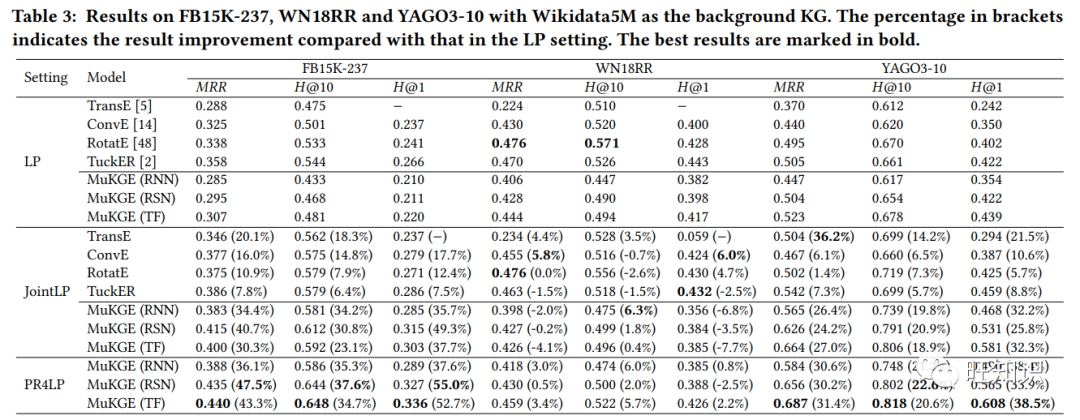
本文提出了用于学习和应用多源知识图谱(KG)嵌入的 "联合预训练和局部再训练 "框架。我们的动机是,不同的知识图谱包含互补信息,可以改善知识图谱嵌入和下游任务。我们在链接的多源知识图谱上预先训练一个大型教师知识图谱嵌入模型,然后提炼知识,针对特定任务的知识图谱训练一个学生模型。为了在不同的幼稚园之间实现知识转移,我们使用实体对齐来构建一个链接子图,用于连接预先训练的幼稚园和目标幼稚园。通过对链接子图进行再训练,可以实现从教师到学生的三级知识提炼,即特征知识提炼、网络知识提炼和预测知识提炼,从而生成更具表现力的嵌入。教师模型可以在不同的目标 KG 和任务中重复使用,而无需从头开始训练。我们进行了大量实验来证明我们框架的有效性和效率。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599397用于长尾推荐的元图学习, Meta Graph Learning for Long-tail Recommendation, KDD 2023.


在推荐系统中,高倾斜的长尾项目分布通常会损害模型在尾部项目上的性能,尤其是基于图的推荐模型。我们提出了一个新思路,将项目之间的关系作为辅助图来学习,以增强基于图的表示学习,并在耦合框架中集体进行推荐。这就带来了两个挑战:1)长尾下游信息也可能对辅助图的学习产生偏差;2)学习到的辅助图可能会对原始的用户-项目双元图产生负迁移。为解决这两个难题,我们创新性地提出了一种新颖的长尾推荐元图学习框架(MGL)。元学习策略被引入到边沿生成器的学习中,首先对生成器进行调整以重建去偏的项目共现矩阵,然后在生成用于推荐的项目关系时对其进行虚拟评估。此外,我们还提出了一种流行感知对比学习策略,通过将可信头部项目表征与所学辅助图的表征进行对齐来防止负迁移。在公共数据集上进行的实验表明,我们提出的模型在尾部项目上的表现明显优于强基准模型,而且不会影响整体性能。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599428为旅游领域搜索中的查询理解持续预训练语言模型, QUERT: Continual Pre-training of Language Model for Query Understanding in Travel Domain Search, KDD 2023.



鉴于预训练语言模型(PLMs)的成功,持续预训练通用 PLMs 已成为领域适应的典范。在本文中,我们提出了 QUERT,一种用于旅游领域搜索中 QUERy 理解的持续预训练语言模型。针对旅游领域搜索查询的特点,QUERT 在四个定制的预训练任务中接受了联合训练:地理感知掩码预测、Geohash 代码预测、用户点击行为学习以及短语和标记顺序预测。下游任务的性能提升和消融实验证明了我们提出的预训练任务的有效性。具体来说,在有监督和无监督设置下,下游任务的平均性能分别提高了 2.02% 和 30.93%。为了检验 QUERT 对在线业务的改进效果,我们在 Fliggy APP 上部署了 QUERT 并进行了 A/B 测试。反馈结果显示,当使用 QUERT 作为编码器时,独特点击率和页面点击率分别提高了 0.89% 和 1.03%。相关资源请访问 https://github.com/hsaest/QUERT
https://dl.acm.org/doi/pdf/10.1145/3580305.3599891通过强化学习实现公有云上分布式深度学习任务的双代理调度程序, A Dual-Agent Scheduler for Distributed Deep Learning Jobs on Public Cloud via Reinforcement Learning, KDD 2023.
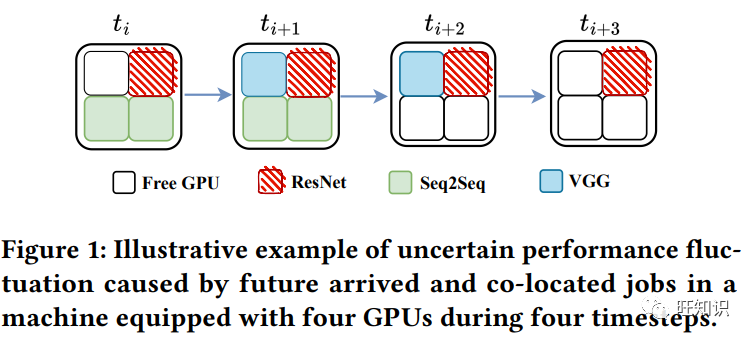
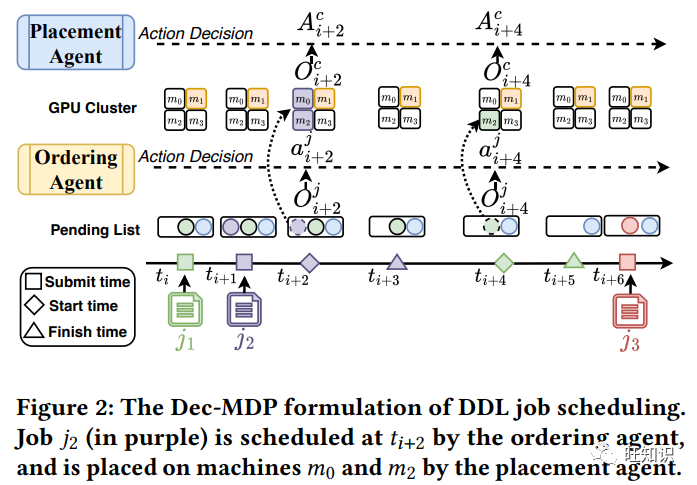

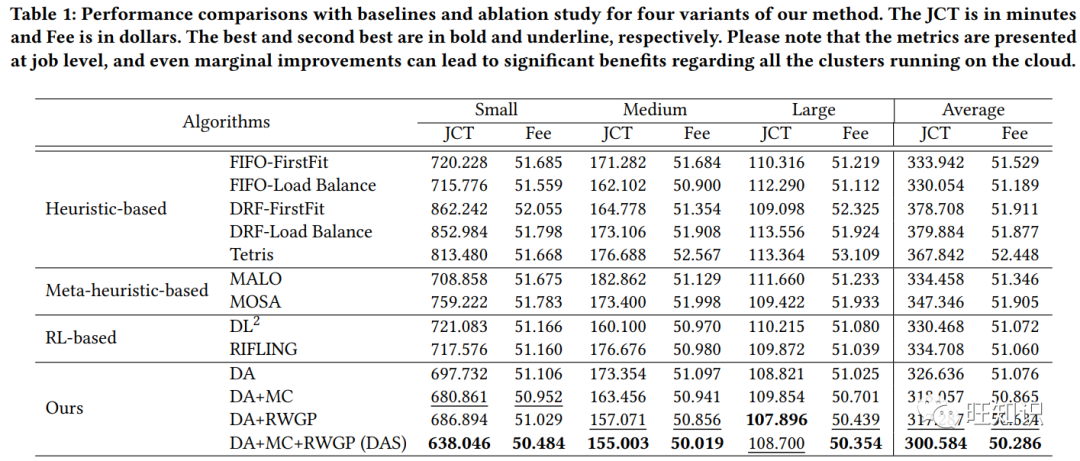
公有云 GPU 集群正在成为训练分布式深度学习作业的新兴平台。在这种训练模式下,作业调度器是改善用户体验的关键组件,即减少训练费用和作业完成时间,还能为服务提供商节省电力成本。然而,调度问题是众所周知的 NP 难题。现有研究大多将其分为两个较简单的子任务,即排序任务和放置任务,分别负责决定作业的调度顺序和 GPU 机器的放置顺序。由于学习型策略具有卓越的适应能力,其性能通常优于传统的启发式方法。然而,目前仍有两大难题尚未得到很好解决。首先,大多数基于学习的方法只关注独立的排序或放置策略,而忽略了它们之间的合作。其次,不平衡的机器性能和资源争用会给作业持续时间带来巨大的开销和不确定性,但现有工作很少考虑到这一点。为了解决这些问题,本文提出了一个从两个子任务中抽象出来的双代理调度器框架,以共同学习排序和布局策略,并做出更明智的调度决策。具体来说,我们设计了一个具有可扩展的挤压和通信策略的排序代理,以实现更好的合作;对于放置代理,我们提出了一种新颖的随机漫步高斯过程,以学习 GPU 机器的性能相似性,同时意识到不确定的性能波动。最后,通过多代理强化学习对双代理进行联合优化。在实际生产集群跟踪中进行的大量实验证明了我们模型的优越性。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599241异构多场景推荐的工业框架, SAMD: An Industrial Framework for Heterogeneous Multi-Scenario Recommendation, KDD 2023.
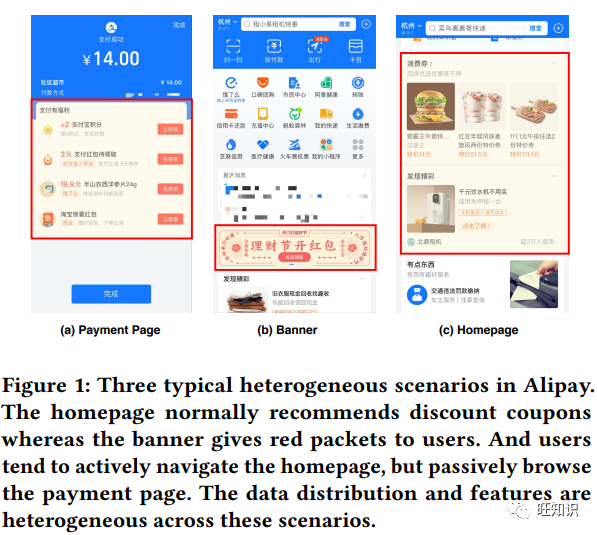



工业推荐系统通常需要同时为多个场景提供服务。在实践中,由于用户经常以不同的意图参与场景,而且每个场景中的物品通常属于不同的类别,因此存在各种异构场景。现有的多场景推荐工作主要集中在对数据分布相似的同质场景建模。它们将知识平等地转移到每个场景中,而没有考虑异构场景的多样性。本文认为,多场景推荐中的异质性是一个亟待解决的关键问题。为此,我们为多场景推荐提出了一个名为 "场景感知模型诊断元蒸馏(SAMD)"的工业框架。SAMD 旨在通过模拟场景关系和进行异构知识提炼,在异构场景中提供场景感知和模型无关的知识共享。具体来说,SAMD 首先测量每个情景的综合表示,然后提出一种新颖的元提炼范式,以进行情景感知知识共享。元网络首先建立潜在场景的关系,并生成每个场景的知识共享策略。然后,异构知识提炼利用场景感知策略,通过中间特征提炼实现异构场景间的知识共享,而不受模型架构的限制。这样,SAMD 以场景感知和模型无关的方式在异构场景间共享知识,从而解决了异构性问题。与其他最先进的方法相比,广泛的离线实验和在线 A/B 测试证明了所提出的 SAMD 框架性能优越,尤其是在异构场景中。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599955用于取货和送货路线预测的深度强化学习框架, DRL4Route: A Deep Reinforcement Learning Framework for Pick-up and Delivery Route Prediction, KDD 2023.
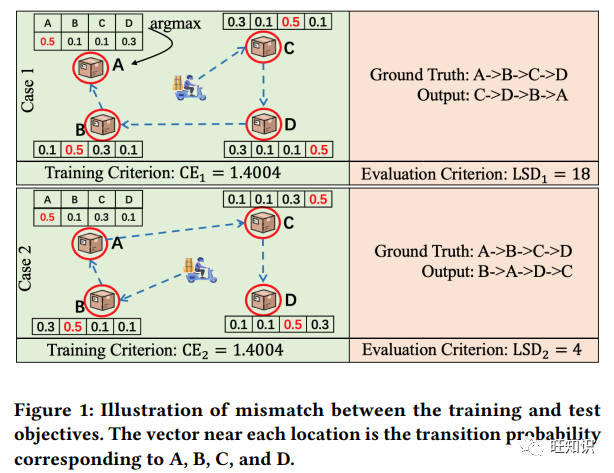
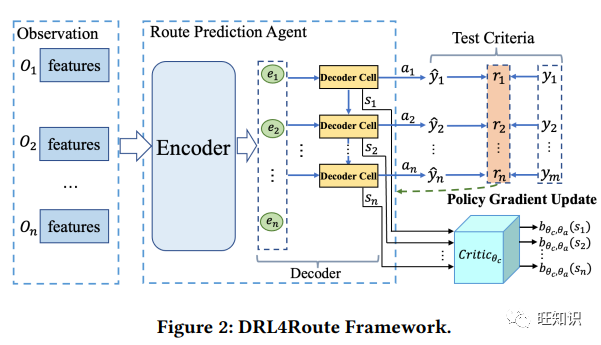
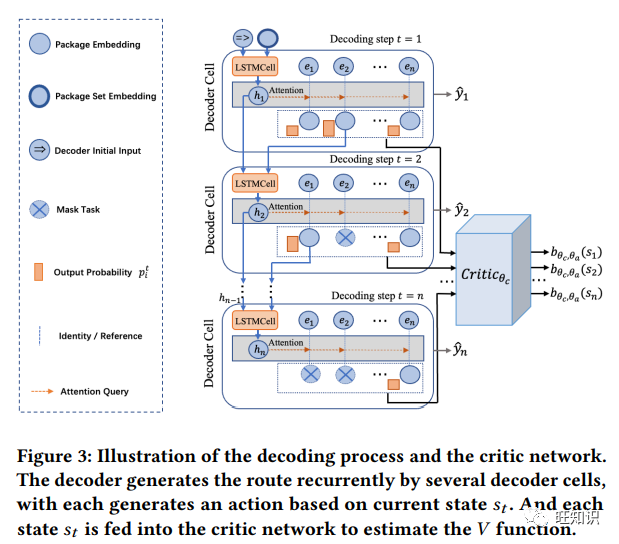

取货和送货路线预测(PDRP)旨在根据工人当前的任务池估算其未来的服务路线,近年来受到越来越多的关注。基于监督学习的深度神经网络因其从海量历史数据中捕捉工人行为模式的强大能力,已成为该任务的主流模型。尽管前景广阔,但它们未能在训练过程中引入无差别测试标准,导致训练和测试标准不匹配。这大大降低了它们在实际系统中的应用性能。为了解决上述问题,我们首次尝试将强化学习(RL)推广到路线预测任务中,并由此产生了一种名为 DRL4Route 的基于 RL 的新型框架。它结合了以往深度学习模型的行为学习能力和强化学习的无差别目标优化能力。DRL4Route 可以作为一个即插即用的组件来增强现有的深度学习模型。在此框架基础上,我们进一步为物流服务中的 PDRP 实现了一个名为 DRL4Route-GAE 的模型。该模型采用行为批判架构,配备了广义优势估计器(Generalized Advantage Estimator),可以平衡策略梯度估计的偏差和方差,从而实现更优化的策略。广泛的离线实验和在线部署表明,在真实世界数据集上,DRL4Route-GAE 比现有方法的位置平方偏差(LSD)提高了 0.9%-2.7%,精度@3(ACC@3)提高了 2.4%-3.2%。
https://dl.acm.org/doi/pdf/10.1145/3580305.3599811
ChatGPT4国内可以直接访问的链接,无需注册,无需翻墙,支持编程等多个垂直模型,点开即用:
https://ai.zntjxt.com(复制链接电脑浏览器或微信中点开即可,也可扫描下方二维码直达)

「 更多干货,更多收获 」

【免费下载】2023年8月份全网热门报告合集
ChatGPT提词手册,学完工作效率提升百倍
万字干货:ChatGPT的工作原理
2023年创业(有创业想法)必读手册
ChatGPT调研报告(仅供内部参考)
ChatGPT的发展历程、原理、技术架构及未来方向
2023年AIGC发展趋势报告:人工智能的下一时代
推荐系统在腾讯游戏中的应用实践.pdf
推荐技术在vivo互联网商业化业务中的实践.pdf
2023年,如何科学制定年度规划?
《底层逻辑》高清配图
推荐技术在vivo互联网商业化业务中的实践.pdf
推荐系统基本问题及系统优化路径.pdf
荣耀推荐算法架构演进实践.pdf
大规模推荐类深度学习系统的设计实践.pdf
某视频APP推荐策略详细拆解(万字长文)关注我们
智能推荐 个性化推荐技术与产品社区 | 长按并识别关注
|

一个「在看」,一段时光👇
这篇关于2023年阿里巴巴信息检索(搜推广)技术论文整理汇总-KDD的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





