本文主要是介绍零代码编程:用ChatGPT将SRT字幕文件批量转为Word文本文档,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一个文件夹中有多个srt视频字幕文件,srt文件里面有很多时间轴:

现在想将其批量转为word文档,去掉里面与字符无关的时间轴,在ChatGPT中输入提示词:
你是一个Python编程专家,要完成一个批量将SRT字幕文件转为Word文本文档的任务,具体步骤如下:
打开文件夹:F:\儿童学习教育\Abadas.适合2岁以上.BBC儿童学习单词的动画;
读取里面所有的srt字幕文件;
将srt字幕文件里面的时间和数字序号全部去掉,只保留字幕文本,另存为word文档;
比如,原有的srt字幕文件内容为:
1
00:00:20,560 --> 00:00:22,760
'Hey, Abadas!'
2
00:00:22,760 --> 00:00:26,120
ALL: Hello, Ben! Come and play with us!
3
00:00:26,120 --> 00:00:30,000
And... # We'll have a...
转换后的word文档内容为:
'Hey, Abadas!'
ALL: Hello, Ben! Come and play with us!
And... # We'll have a...
注意:每一步都要输出相关信息
每一行代码都要给出详细的注释
ChatGPT的回复:
以下是一个使用 python-docx 和 re(正则表达式模块)将 SRT 字幕文件转为 Word 文档的 Python 脚本。请先安装 python-docx 库,可以通过 pip install python-docx 来安装。
import os
import re
from docx import Document
# 设置源文件夹路径
source_dir = 'F:/儿童学习教育/Abadas.适合2岁以上.BBC儿童学习单词的动画'
# 遍历源文件夹中的所有字幕文件
for file_name in os.listdir(source_dir):
# 确保是 SRT 文件
if file_name.endswith('.srt'):
file_path = os.path.join(source_dir, file_name)
print(f'正在处理字幕文件: {file_path}')
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 使用正则表达式将时间和数字序号去掉
pattern = re.compile(r'\d+\n\d{2}:\d{2}:\d{2},\d+ --> \d{2}:\d{2}:\d{2},\d+\n')
text_only = re.sub(pattern, '', content)
# 创建一个 Word 文档,并将处理后的文本添加到文档中
doc = Document()
doc.add_paragraph(text_only)
# 将 Word 文档保存为一个新文件
word_file_path = file_path.replace('.srt', '.docx')
doc.save(word_file_path)
print(f'已将字幕文件保存为 Word 文档: {word_file_path}')
注意:此脚本假设所有的 SRT 文件都使用 UTF-8 编码。如果你的 SRT 文件使用其他编码,你可能需要修改 open() 函数中的 encoding 参数。此外,脚本假设 SRT 文件的时间戳和文本之间没有额外的空行。如果有额外的空行,你可能需要修改或添加正则表达式来处理它们。最后,这个脚本会直接修改你的文件系统,因此在运行之前请确保你已经备份了原始数据,或者在一个安全的环境下运行这个脚本。在运行这个脚本之前,请确保你的Python环境有足够的权限来读取和写入文件。以上代码未进行错误处理,实际使用时应考虑加入错误处理机制。

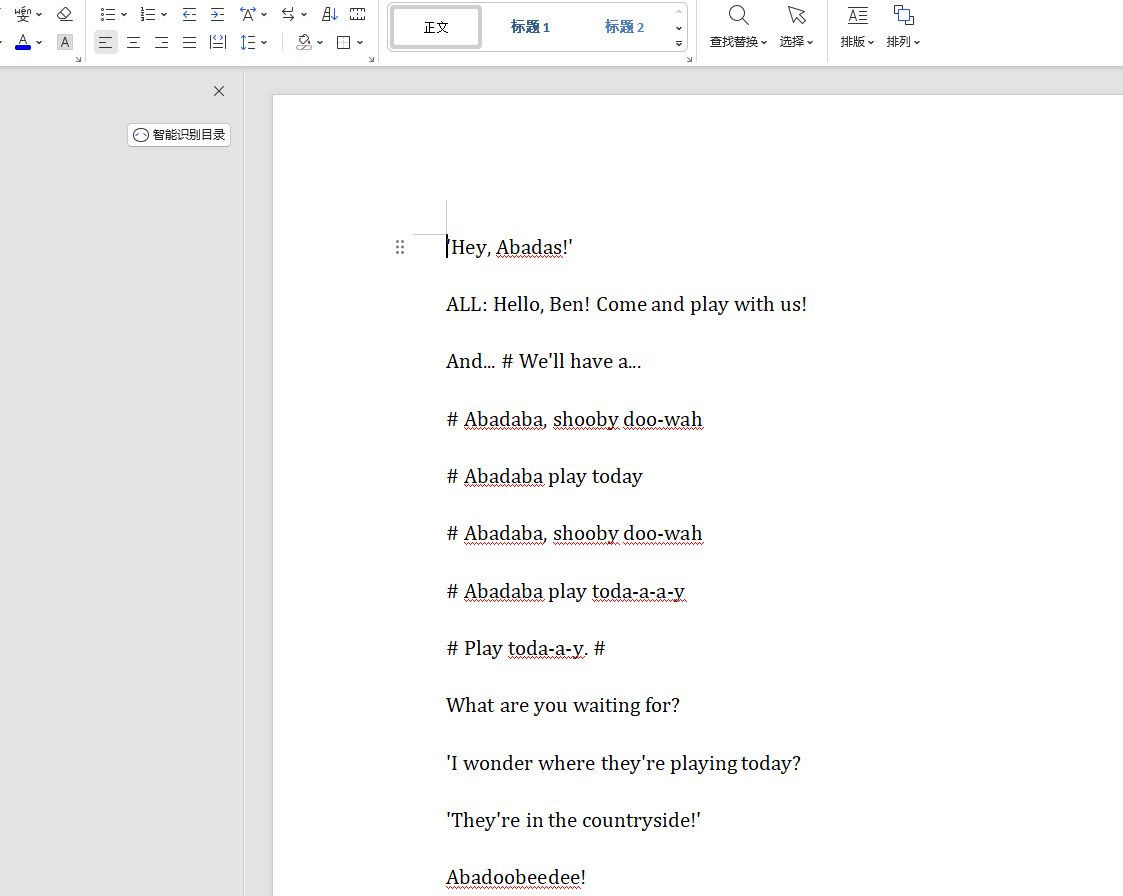
转换后的word文档如下:
这篇关于零代码编程:用ChatGPT将SRT字幕文件批量转为Word文本文档的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






