本文主要是介绍数据服务托起大数据产业链兴起,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着大数据概念深入人心,越来越多的企业开始认可数据存在价值。挖掘自身数据价值、获取外部数据是企业两大需求。但在实践中,企业发现两大需求存在同样问题,不论是自身数据还是外部数据,原始数据与有价值数据之间存在鸿沟,自身缺乏填平鸿沟的技术手段。
新兴大数据公司成为解决问题的答案,他们具备处理数据的经验和技术,可以将原始数据转化成能为业务提供支持的数据。数据服务产业链就此形成。
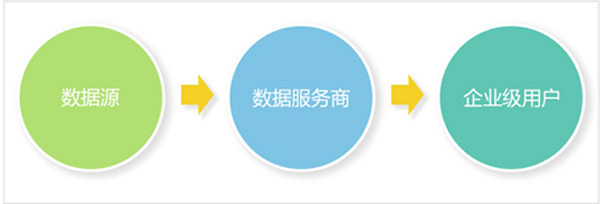
整个数据服务产业链可以分为三个部分,从上游的数据源到中游的数据服务商,再到下游的企业级用户。因为大数据公司大多成立时间较短,自身业务产生数据有限,一般是作为数据源和企业级用户的桥梁,处于整个产业中游。做数据加工和数据应用,挖掘原始数据的价值,为企业业务提供数据支持。
在整个大数据产业生态中,数据服务是生态中重要一环,下接底层技术平台,上接顶层应用。
数据源众多,有价值数据源在巨头手中
政府的数据大部分还尚未被挖掘,目前应用比较多的是公安数据,明略数据、中奥科技等公司在与公安合作,挖掘数据价值。其他政府机关的数据多数还处于沉睡阶段,九次方等公司正与地方政府合作,推进政府机关大数据发展。
传统企业的数据应用程度与该行业的信息化程度有关,像金融、电信等行业信息化程度较高,其数据源价值很大。像医疗、制造业等行业的企业内部数据库尚未实现互联,大数据尚处于起步阶段。这点可以从大数据公司重点涉足的行业看出,多数大数据公司选择将银行、运营商作为切入点,医疗、工业大数据公司相对较少,而且体量较小。
互联网数据乍一看是开放程度最高,应用范围最广的数据源,但实际上互联网数据中最具价值的部分都被BAT等互联网巨头所拥有,目前几乎不对外开放。通过爬虫等方式获取的数据价值非常有限。不过随着移动互联网兴起,移动设备承载的用户行为数据价值被挖掘出来。
目前来看,最有价值的数据源是政府、运营商和BAT,BAT的数据完全不开放,政府的数据同样开放程度有限,而运营商的数据开放程度最高,有十几家大数据公司与运营商合作,可以接触到运营商的数据。
大数据公司承上启下
数据加工是指将数据源的数据进行清洗、整理,而数据应用是将清洗后的数据赋予行业属性,使其能直接为下游客户提供帮助。
目前,数据堂、聚合数据等公司专注于数据加工,而TalkingData、集奥聚合等公司同时在做数据加工和数据应用。
数据堂、聚合数据的业务比较类似,他们将不同渠道的数据进行清洗、整理,将数据进行分类,做成标准化API接口,提供给做数据应用的公司,一般来说,他们并不直接面对企业级客户。工作有点类似于将小麦加工成面粉,做面包的工作交给下一层公司去完成。
TalkingData、集奥聚合不仅仅做数据加工,还在探索数据的场景应用。他们直接服务企业级客户,他们在处理数据的过程中就需要考虑客户的需求,从场景应用层面考虑数据挖掘和数据分析。工作是将小麦加工成适合做面包的面粉,同时做面包。
上述两类公司的区别是,数据堂、聚合数据的业务更贴近数据源,而TalkingData、集奥聚合的业务更贴近企业级用户。

大数据交易中心如雨后春笋般出现
提供数据服务的,除了大数据公司外,大数据交易所也扮演重要角色。自2015年4月贵阳大数据交易所成立,各地大数据交易中心如雨后春笋般冒出。短短一年时间,就出现了长江大数据交易中心、华中大数据交易中心、上海大数据交易中心、浙江大数据交易中心等近十家交易中心。
交易中心要么是地方政府与大数据公司合作成立,如贵阳大数据交易所,要么是由上市公司牵头建立,如浙江大数据交易中心。从目前来看,大数据交易中心还处于探索阶段,数据交易量不大。截至今年8月,成立一年的贵阳大数据交易所的交易总额刚刚突破1亿元。
数据特点决定数据是非标商品,交易存在信息不对称现象
经过几年发展,大数据不再仅仅是概念,开始逐步落地。大家不再迷信数据,对数据的看法开始回归理性。爱分析认为数据具备以下几个特点:
一. 绝大部分数据价值有限。
无论是政府、传统企业还是互联网,每天都在产生TB级、甚至PB级的数据。这其中大部分数据对企业级用户而言,是没有价值的,或者说价值有限的,真正能为企业提供帮助的数据是极小一部分。
每个人都知道数据源越多,数据维度越广,数据对业务的提升越大。但在实际应用中,还是需要摒弃掉大部分数据,集中研究很小规模的数据。一方面,尽管Hadoop、Spark等开源技术已经大大降低了数据存储、处理的成本,但面对海量数据,仍然有些力不从心;另一方面,大数据在各行业的应用尚处于探索阶段,很多数据的场景应用尚未被发掘。
上述两个原因使得绝大部分数据价值有限,这导致数据存在一定聚合效应,有价值的数据源集中在几个行业,甚至是几个公司。

二. 数据与场景应用相结合才有价值。
经济下行,业绩不乐观,企业变得越来越务实。像前十年大量购买IT设备那样在大数据投入是不可能的,企业更加关心数据能带来什么价值。直接把数据给企业是没有用的,需要将数据与企业的业务场景结合起来,使企业真正看到这些数据能为其带来什么,这才是数据的价值。
从这个角度来看,脱离应用场景空谈数据价值是没有意义的。与场景结合的越紧密,数据价值越大,企业级用户付费意愿越强烈。
三. 数据具有时效性,越久远的数据价值越低。
很多人将数据比喻为石油,两者的确有很多相像之处。但是数据与石油有一个非常大的区别,数据具有时效性。只要保存得当,一年前的石油和刚开采的没有本质区别,而一年前的数据价值远低于最新数据。
以精准营销为例,通过数据挖掘找到用户感兴趣的产品,过段时间很可能用户已经购买该产品。这时,原有数据已经失效,用户画像发生变化,需要对最新的数据进行分析,找到新的需求点。
因为上述三个特点,数据是非标准化商品。如果双方仅限于数据交易,没有更加深层次的合作,数据就脱离应用场景而存在,如何进行定价是最大问题,如前文所述,数据只有在应用过程中才能发现其价值。
除以之外,不同数据对更新速度依赖程度是不一样的,在各场景应用上数据时效性也有很大差别。因此,在判断数据价值上,时效性对数据价值影响有多大是难以估量的。
另一方面,数据交易过程中存在信息不对称的现象。数据买方如果不实际使用数据是无法判断买到的数据是否为真正有效数据,现实与想象中有多大差别是不确定的。另一方面,买方很难用一种简单方式去判断获得的数据是否为最新数据,同样需要在应用过程中去鉴别。
目前数据在各行业的应用还处于探索阶段,随着行业发展,数据在各行业应用成熟,数据能带来多大价值会逐渐达成共识,数据将逐渐成为标准化商品,交易过程中的信息不对称将大大降低。
在实际操作上,很多有价值的数据源都是敏感数据,如何进行脱敏处理,如何实现交易是另外一个大问题。针对这样的问题,目前大数据公司采取的方式是将自身的算法架设在数据源的机房,通过原始数据提炼出数据标签,完成数据加工的工作,像数据堂、TalkingData、集奥聚合都采用这类方式。

大数据交易中心还得靠政府
大数据交易中心不仅仅是作为民间数据交易的桥梁,更是作为政府数据开放的桥头堡。目前来看,政府数据的开放存在政策问题。尽管国家近年频频出台大数据相关政策,但是中央关于政府机关数据开放的具体管理办法还未公布,地方政府对开放数据存在疑虑,做法非常谨慎。
如果大数据交易中心仅仅交易一些民间数据,交易所的作用相对有限。正如前文所言,大部分数据价值有限,数据源相对比较集中,数据买方可以直接与数据源进行合作,无需通过交易所这个平台实现。
近期,贵州政府制定发布《政府数据 数据分类分级指南》等4项政府数据系列地方标准。这说明一些地方政府已经开始在政府数据开放上进行尝试,相信国家层面的相关政策为时不远。
数据与应用结合当前发展最佳
随着技术发展,数据加工会更趋于标准化加工流程,同业比拼的不仅仅是技术实力,对接的数据源数目和质量更为重要。目前这一领域还属于早期圈地阶段,很多行业的数据还未被有效存储、采集,未来随着各行业信息化成熟,高质量数据源是最核心竞争力。这个领域会逐步淘汰小公司,最终剩下几个大公司,新公司进入门槛越来越高。
这领域先发优势比较明显,越早进入市场,越容易对接更多的数据源。很多掌握数据源的企业最初是不清楚自身数据源价值,因此早期获取数据源成本相对较低。数据堂深耕这一领域五年时间,现在是这一领域最大公司,数据源通过众包、行业、政府及互联网四个维度进行获取,与同业公司相比优势明显。
数据应用领域发展前景更好,这些公司的优势不仅仅是技术和数据源,还有对数据基于场景应用的理解,各家公司为企业级用户提供的服务具有差异性,市场竞争相对良性。另一方面,数据应用市场规模前景巨大,目前仅仅是冰山一角。以银行客户为例,目前大数据公司为银行提供的主要是风险控制、精准营销等对外业务层面,未来还会涉及到银行客户的内部运营效率提升等方面。市场规模大、业务差异化大,使得各个垂直行业中都会产生巨头公司。
从目前行业发展来看,数据应用领域的公司增速更快、体量更大,TalkingData、集奥聚合估值都超过30亿。这两家公司都是选择以金融、地产作为切入点。金融、地产行业一方面公司自身信息化程度高,对数据非常重视,另一方面大型企业居多,付费能力强。
本文作者:佚名
来源:51CTO
这篇关于数据服务托起大数据产业链兴起的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







