本文主要是介绍交叉验证,五次五折,十次十折,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
交叉验证是一种评估机器学习模型的表现;
其中k折交叉验证就是指:将一个数据集分成k个部分,每次取其中的一份作为测试集,k-1份作为训练集;因此,k折交叉验证就会进行k次,获得k个结果后取平均值
以10折交叉验证为例:
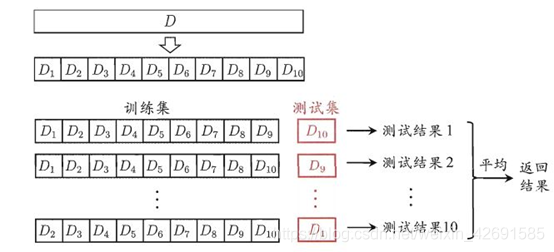
图源周志华《机器学习》
底层实现代码:
for i in range(10): # 十次data = readdataset("E:\ML\smote\Synthetic_pima_naivesmote.xlsx")lines = data.shape[0] # 行数test_ratio = 0.1 # 测试集比例t=data.shape[1] label = data[:, t-1]test_line = int(lines * test_ratio)counts = 0for k in range(10): # 十折for i in range(test_line):classifyresults = classify(data[i], data[test_line:lines], label[test_line:lines], 3)if classifyresults == label[i]:counts += 1aa = copy.deepcopy(data[0:test_line])data[0:lines - test_line] = data[test_line:lines]data[lines - test_line:lines] = aa#print(norm_data)bb = copy.deepcopy(label[0:test_line])label[0:lines - test_line] = label[test_line:lines]label[lines - test_line:lines] = bbprint('knn10次10折交叉验证的正确率为{}'.format(100*counts/lines))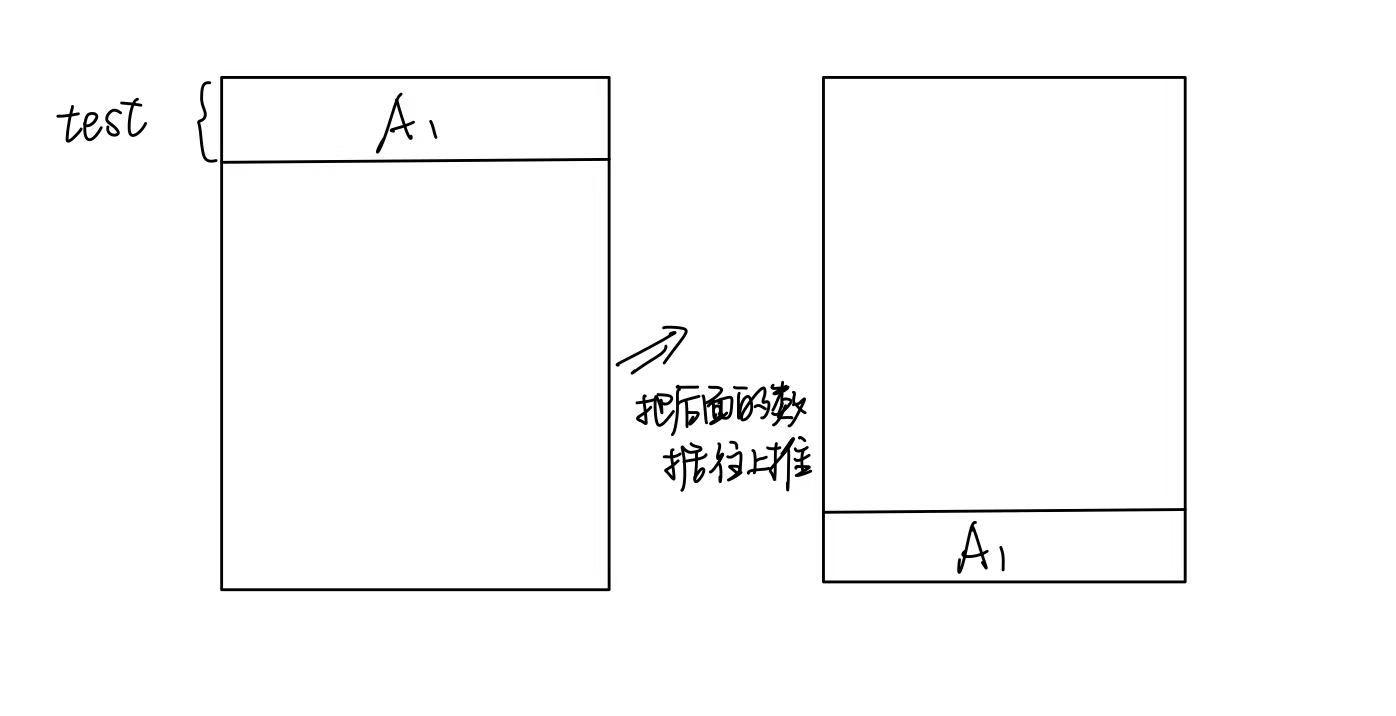
也可以选择sklearn中stratifiedkFold分层采样函数,分层采样可以使得不平衡数据集中各个类别的平衡性,即不会出现测试集中没有少数类的现象
代码如下
from sklearn.model_selection import StratifiedKFold
id = 0
for i in range(5):skf = StratifiedKFold(n_splits=5, shuffle=True,random_state=None)id = 0for train_index,test_index in skf.split(X,y):id+=1X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]y_train = y_train[:, np.newaxis]y_test = y_test[:,np.newaxis]train = np.hstack((X_train,y_train))test = np.hstack((X_test,y_test))train = pd.DataFrame(train)test = pd.DataFrame(test)train.to_excel('E:\\ML\\smote\\数据集划分\\page-blocks-1-3_vs_4\\'+str(i+1)+'\\train'+str(id)+'.xlsx',index = False)test.to_excel('E:\\ML\\smote\\数据集划分\\page-blocks-1-3_vs_4\\'+str(i+1)+'\\test'+str(id)+'.xlsx',index = False)这篇关于交叉验证,五次五折,十次十折的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







