本文主要是介绍【CHI】Ordering保序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本节介绍CHI协议所包含的支持系统保序需求的机制,包括:
• Multi-copy atomicity
• Completion response and ordering
• Completion acknowledgment
• Transaction ordering
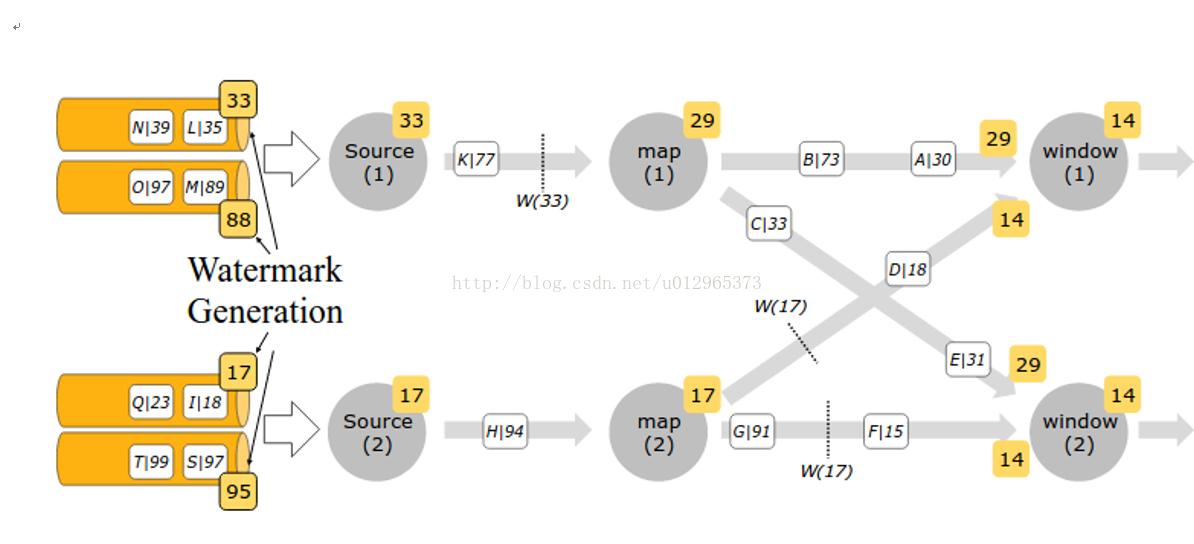
一、 Multi-copy atomicity
CHI协议中所使用的memory model要求为multi-copy atomic,所有相关组件必须确保所有的write-type必须是multi-copy atomic。一个写操作被定义为multi-copy atomic必须满足以下两个条件:
- 所有对相同位置的写入都是序列化串行的,也就是说,所有的请求者都以相同的顺序观察到它们,尽管一些请求者可能不会观察到所有的写操作。
- 一笔写操作只有被所有Requester观察到后,才能被同地址的Read操作读出该值;
注意:在本规范中,如果两个地址的cacheline地址和物理地址空间(PAS)属性相同,则认为它们在一致性、可观察性和冲突性方面是相同的。
二、 Completion Response and Ordering
不管是同一个agent还是不同agents,为了保证当前transaction和后续的transactions之间的顺序,CHI采用Comp,RespSepData,CompData响应来保证。如下表所示:


- 对于Requester访问Non-cacheable或Device区间的Read transaction,RespSepData或CompData响应可以保证当前的传输访问的endpoint范围 可以被后续的transactions观察到;
- 对于Requester访问Cacheable地址的Read transaction,CompData或DataSeqResp响应可以保证当前的传输被后续任何agent发送的transactions观察到;
- 对于Requester访问Cacheable地址的Read transaction,RespSepData响应可以保证没有更早之前的transactions将会发送snoop请求给这个Requester,之后的transactions需要发送snoop请求只有等到HN收到该笔read transaction的CompAck之后才可以;
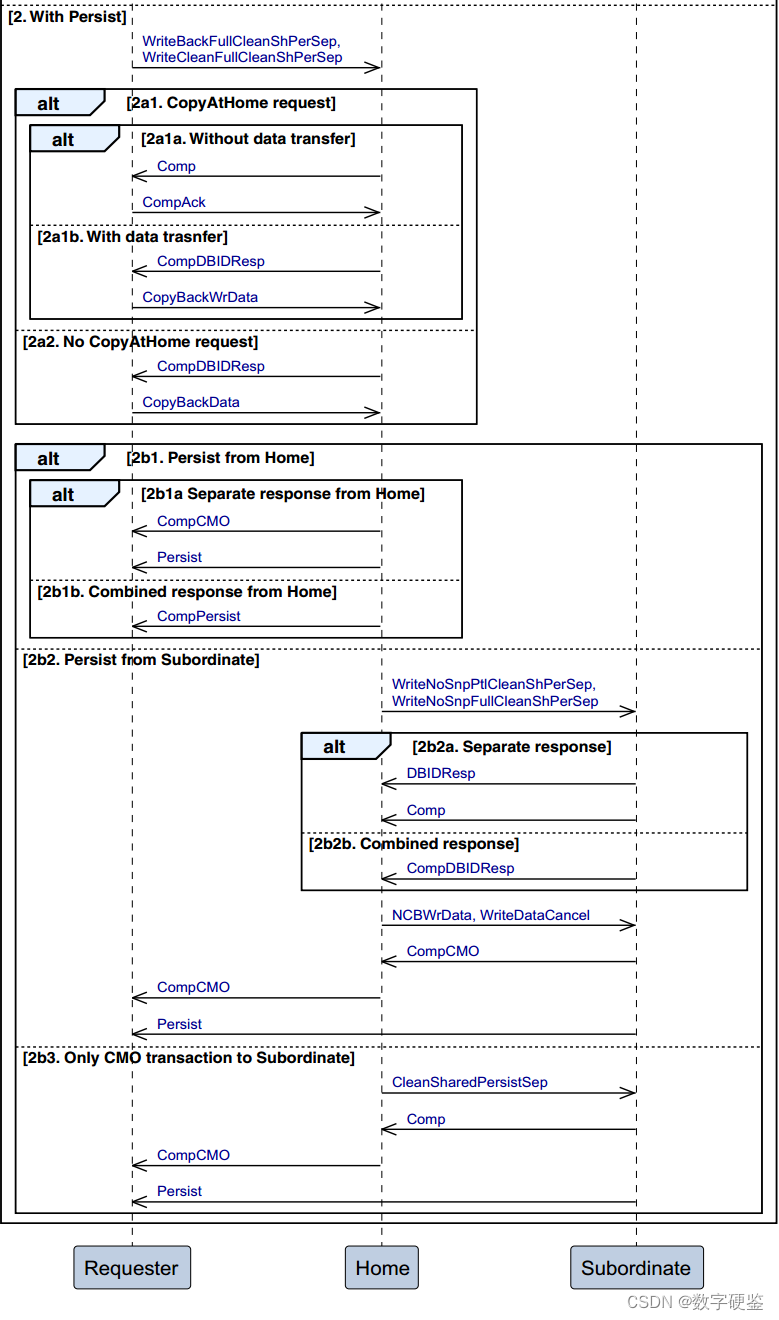
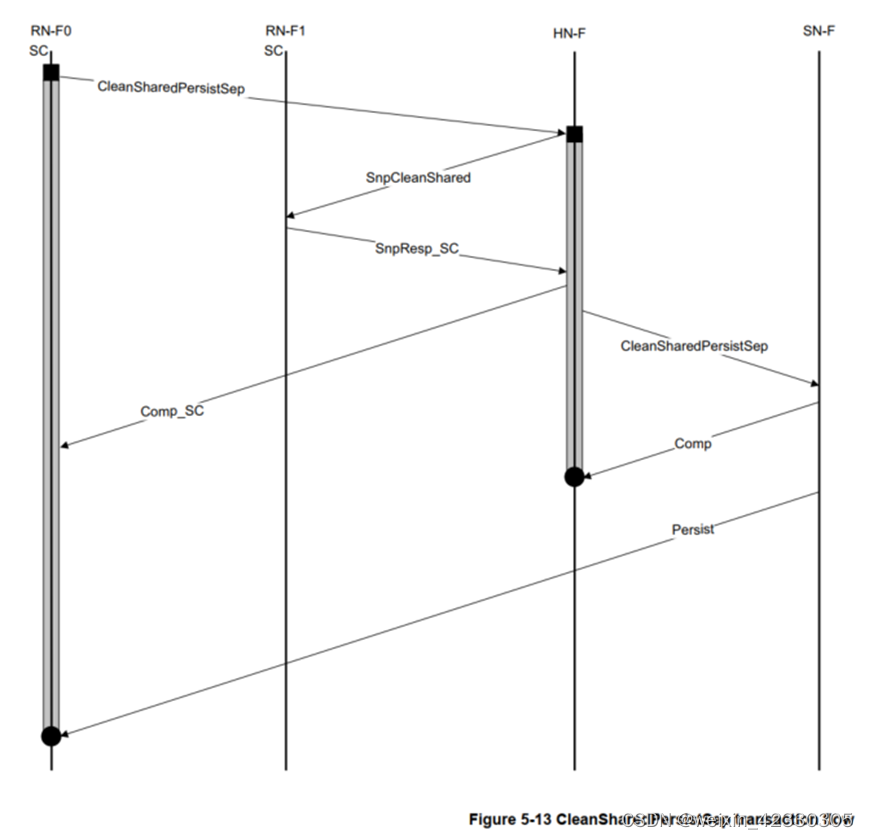
- 对于Dataless transaction,只能访问Cacheable memory空间,Comp响应就可以保证同地址的当前transaction可以被任何agent的后续transactions观察到;另外CleanSharePersist transaction,HN必须收到下游Persist节点的响应之后,才能往RN返回Comp;
- 对于访问Non-cacheable或Device nRnE或Device nRE的Write or Atomic transactions,Comp或CompData响应可以保证同endpoint范围的当前传输可以被任何agent的后续transactions观察到;
- 对于访问Cacheable或Device RE的Write or Atomic transactions,Comp或CompData响应可以保证同地址的当前传输可以被任何agent的后续transactions观察到;
注意:
endpoint address range取决于具体实现,通常的定义如下:对于外设,则是整个peripheral device区域;对于memory空间,则是整个cacheline大小;
对于EWA的Write transaction去访问Non-cacheable或Device空间,Comp不能保证同endpoint地址范围的该transaction被后续的transactions所观察到,如果需要确保保序,可以使用Endpoint Order来访问同一个endpoint address range;
三、Completion acknowledgement
对于Requester发送的transactions和其它Requester transactions产生的snoop transactions之间的相对保序关系是通过Completion Acknowledgment响应来确保的。这个可以保证在Requester的transaction之后的保序的snoop transaction是在Requester完成响应之后才被接收;
一笔transaction完成和发送CompAck之间的顺序如下:
- RN-F在收到Comp、RespSepData或CompData、RespSepData和DataSepResp两者之后,才发送CompAck;
- 除了ReadOnce*,HNF只有在收到CompAck之后,才会发送下一笔同地址的snoop transaction;对于CopyBack transactions,WriteData蕴涵着CompAck,因此HNF必须等到WriteData之后再发送同地址的snoop transaction;
这个序列保证了RNF按照相同的顺序 HNF发出到同一cacheline的 a transaction 和 a snoop的相同顺序接收到。这可以确保以正确的顺序观察到相同cacheline的事务。
除了ReadOnce*,以上这个机制保证了Requester收到Comp和发送CompAck之间,不能收到任何的同地址的snoop请求。
对于一笔transaction中CompAck是否使用是取决于ExpCompAck域,RN在合适需要将ExpCompAck置位且产生CompAck响应有如下规定:
- 除了ReadNoSnp和ReadOnce*操作,RN-F其它所有读操作都需要发送CompAck;
- RN-F允许但不要求ReadNoSnp和ReadOnce*命令发送CompAck响应;
- 在StashOnce*、CMO、Atomic、Evict操作中,不能发送CompAck响应;
- RN-I和RN-D允许但不要求在读操作中要包含CompAck响应;
- RN-I和RN-D的Dataless和Atomic传输不能包含CompAck响应;
- 保序的ReadNoSnp和ReadOnce*如果要使用DMT,那么必须使用CompAck响应;
- 对于写操作,CompAck只能用于:
——WriteUnique和WriteNoSnp在要求OWO时;
——在HNF提供了Comp响应的CopyBack write事务,表明请求者不能发送CBWrData。当HNF提供了一个Comp响应时,请求者必须发送一个CompAck,而不管原始的ExpCompAck值如何。
HNF必须支持所有允许或需要使用CompAck的transactions。
SN不需要支持CompAck的使用。
请求者,如HNF或HNI与SNF或SNI通信时,不能发送CompAck响应。
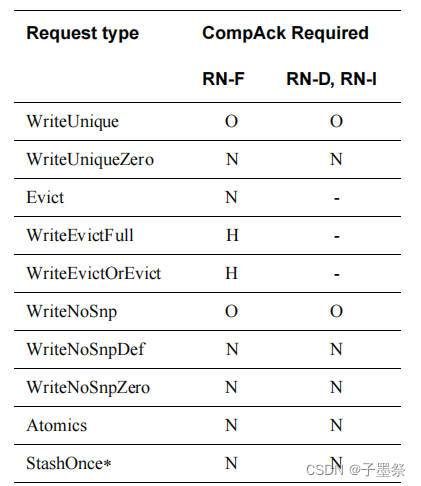
下表展示了需要CompAck响应的请求程序类型,以及提供该响应所需的相应请求者类型:
Y :Yes, required
N :No, not required
H :Dependent on transaction flow chosen by Home in response to the CopyBack Write request.
O :Optional
- :Not applicable

四、Transaction ordering
未完待续。。
这篇关于【CHI】Ordering保序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!