本文主要是介绍python bs64爬取中国工程院院士信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作为一个渣硕已经毕业一年了,也工作一年了,得了空闲来写写文章。
前段时间,有个老师叫我写个爬取中国工程院院士信息的爬虫,我写了个大概的代码来实现。
先说一下做这个的整体思路吧:
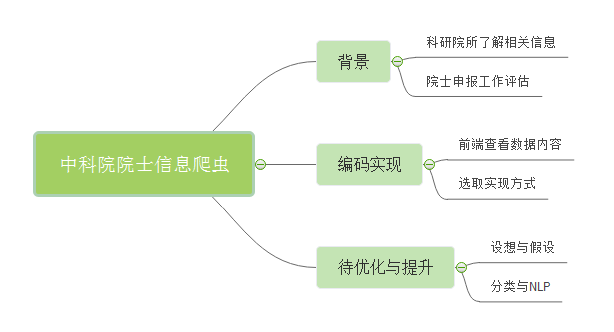
开门见山的说:就是领导想要看看申请院士,从业者的经历等等信息,为了满足领导的需求,我就开始实现我的爬虫程序了
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoupdef get_content(url_string,file):ret = requests.get(url=url_string)ret.encoding = 'utf-8'soup = BeautifulSoup(ret.text, 'html.parser')content = soup.find_all(name='li',class_='name_list')for list_content in content:main_http='http://www.cae.cn'for i in list_content:cotent_url=main_http+i['href'] #拼接URL 获取每个URL下院士的信息cotent_detail = r这篇关于python bs64爬取中国工程院院士信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





