本文主要是介绍缓存替换算法简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在梳理堆栈相关的问题,翻到wiki百科的CPU cache,对其中内容稍作记录,以飨读者。
CPU 缓存定义
CPU 缓存是计算机的中央处理单元 (CPU) 使用的硬件缓存,用于降低从主内存访问数据的平均成本(时间或能源)。
缓存是一种更小、速度更快的内存,位于更靠近处理器内核的位置,它存储来自常用主内存位置的数据副本。 大多数 CPU 具有多个缓存级别(L1、L2,通常是 L3,甚至很少是 L4)的层次结构,L1 会单独特别存储指令缓存和数据缓存。
缓存替换策略
缓存算法(也经常称为缓存替换算法或缓存替换策略)指的是对指令或算法的优化,计算机程序或硬件维护结构可以利用这些指令或算法来管理存储在计算机上的信息的缓存。 缓存算法通过将最近或经常使用的数据项保存在比普通内存存储访问速度更快或计算成本更低的内存位置来提高性能。 当缓存已满时,算法必须选择丢弃哪些条目 (item) 以为新条目腾出空间。
概述
平均内存引用时间为:
其中
为未命中率,
为出现未命中时进行主内存访问的时间,
为延迟:引用缓存的时间(命中和未命中应该相同),
为各种次要效应,例如多处理器系统中的排队效应。
影响缓存的的主要有两个指标:延迟和命中率。
缓存的“命中率”描述了在缓存中实际找到搜索项的频率。更有效的替换策略会跟踪更多使用信息以提高命中率(对于给定的缓存大小)。
缓存的“延迟”描述了在请求所需项目后缓存可以返回该项目的时间(命中时)。更快的替换策略通常会跟踪较少的使用信息——或者,在直接映射缓存的情况下,没有信息——以减少更新该信息所需的时间。
每个替换策略都是命中率和延迟之间的折衷。
命中率测量通常在基准应用程序上执行。实际命中率因应用程序而异。特别是,视频和音频流应用程序的命中率通常接近于零,因为流中的每一位数据都是第一次读取一次(强制缺失)、使用,然后再也不会读取或写入。更糟糕的是,许多缓存算法(尤其是 LRU)允许这些流数据填充缓存,将即将再次使用的缓存信息推出(缓存污染)。
First in first out (FIFO)
使用此算法,缓存的行为方式与 FIFO 队列相同。 缓存按块添加的顺序逐出块,而不考虑它们之前被访问的频率或次数。
Last in first out (LIFO) or First in last out (FILO)
使用此算法,缓存的行为方式与栈相同。 缓存逐出最近添加的块,而不考虑它之前被访问的频率或次数。 LIFO 与 FIFO 队列的行为方式相反。
Least recently used (LRU)
首先丢弃最近最少使用的项目。 如果想要确保算法总是丢弃最近最少使用的项目,则需要算法跟踪条目什么时候被使用过,代价昂贵。 该技术的一般实现需要为缓存行保留“年龄位”并根据年龄位跟踪“最近最少使用”缓存行。 在这样的实现中,每次使用缓存行时,所有其他缓存行的年龄都会发生变化。 LRU 还可以拓展为其他的缓存算法。
以下示例的访问顺序为 A B C D E D F。

在上面的例子中,一旦 A B C D 被安装在具有序列号的块中(每个新访问增加 1),当访问 E 时,它是一个未命中,它需要安装在其中一个块中。 根据 LRU 算法,由于 A 的 Rank(A(0)) 最低,E 将替换 A。
在倒数第二个步骤 D 被访问,因此序列号被更新。
LRU 与许多其他替换策略一样,可以使用向量空间中的状态转换场来表征,它决定动态缓存状态的变化,类似于电磁场如何决定放置在其中的带电粒子的运动。
Time aware least recently used (TLRU)
时间感知最近最少使用(TLRU)是 LRU 的一种变体,专为缓存中存储的内容具有有效生命周期的情况而设计。该算法适用于网络缓存应用,例如信息中心网络 (ICN)、内容交付网络 (CDN) 和一般分布式网络。 TLRU 引入了一个新术语:TTU(使用时间)。 TTU 是一个内容/页面的时间戳,它根据内容的位置和内容发布者的公告规定了内容的可用时间。由于这种基于位置的时间戳,TTU 为本地管理员提供了更多的控制来调节网络存储。在TLRU算法中,当一条内容到达时,缓存节点根据内容发布者分配的TTU值计算本地TTU值。本地 TTU 值是通过使用本地定义的函数来计算的。一旦计算出本地 TTU 值,就对存储在缓存节点中的总内容的子集执行内容替换。 TLRU 确保应将不太受欢迎的内容替换为新传入的内容。
Most recently used (MRU)
与最近最少使用(LRU)相反,MRU 首先丢弃最近使用的项目。 在第 11 届 VLDB 会议上发表的研究结果中,Chou 和 DeWitt 指出,“当一个文件以 [Looping Sequential] 参考模式被重复扫描时,MRU 是最好的替换算法。”随后,其他研究人员在 22 日发表了演讲 VLDB 会议指出,对于随机访问模式和对大型数据集的重复扫描(有时称为循环访问模式),MRU 缓存算法比 LRU 具有更多的命中率,因为它们倾向于保留较旧的数据。 MRU 算法在项目越旧,越有可能被访问的情况下最有用。
以下示例的访问顺序为 A B C D E C D B。
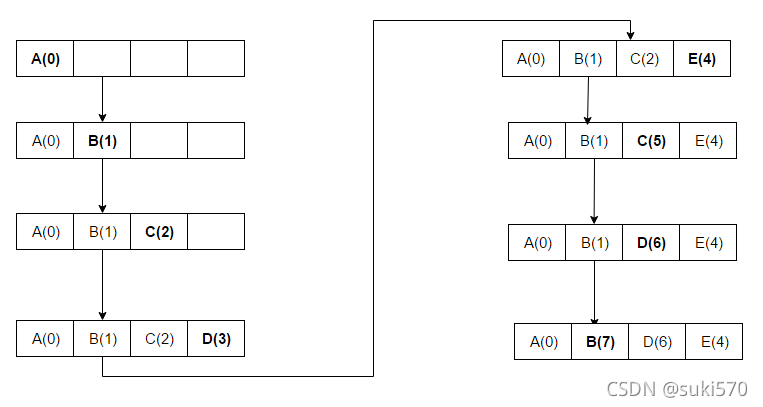
这里,A B C D 被放置在缓存中,因为仍有可用空间。 在第 5 次访问 E 时,我们看到持有 D 的块现在被 E 替换,因为该块最近被使用过。 对 C 的另一次访问和在下一次访问 D 时,C 被替换,因为它是在 D 之前访问的块,依此类推。
Least-frequently used (LFU)
计算需要一个项目的频率。 那些最不常用的首先被丢弃。 这与 LRU 的工作原理非常相似,不同之处在于我们不是存储块最近被访问的值,而是存储它被访问次数的值。 因此,当然在运行访问序列时,我们将替换缓存中使用次数最少的块。 例如,如果 A 被使用(访问)5 次,B 被使用 3 次,其他 C 和 D 各被使用 10 次,我们将替换 B。
Adaptive replacement cache (ARC)
在 LRU 和 LFU 之间不断平衡,以提高组合结果。 ARC 通过使用有关最近被逐出的缓存项的信息来动态调整受保护段和试用段的大小以充分利用可用缓存空间,从而改进了 SLRU。
Nimrod Megiddo and Dharmendra S. Modha. Arc: A self-tuning, low overhead replacement cache. In Pro- ceedings of the 2Nd USENIX Conference on File and Storage Technologies, FAST ’03, pages 115–130, Berke- ley, CA, USA, 2003. USENIX Association.
Multi queue (MQ)
开发多队列算法或 MQ 是为了提高二级缓冲区缓存的性能,例如服务器缓冲区缓存。 Zhou、Philbin 和 Li 在一篇论文中介绍了它。 MQ 缓存包含 m 个 LRU 队列:Q0、Q1、...、Qm-1。这里,m 的值表示基于该特定队列中所有块的生命周期的层次结构。例如,如果 j>i,则 Qj 中的块将比 Qi 中的块具有更长的生命周期。除了这些,还有另一个历史缓冲区 Qout,这是一个维护所有块标识符及其访问频率的列表的队列。当 Qout 已满时,最旧的标识符将被逐出。块在 LRU 队列中保留给定的生命周期,该生命周期由 MQ 算法动态定义为对同一文件的两次访问之间的最大时间距离或缓存块的数量,以较大者为准。如果一个块在其生命周期内没有被引用,它会从 Qi 降级到 Qi-1,或者如果它在 Q0 中,则从缓存中驱逐。每个队列也有一个最大访问计数;如果队列 Qi 中的块被访问超过 2i 次,则该块被提升为 Qi+1,直到它被访问超过 2i+1 次或它的生命周期到期。根据 LRU,在给定的队列中,块按访问的新近度排序。
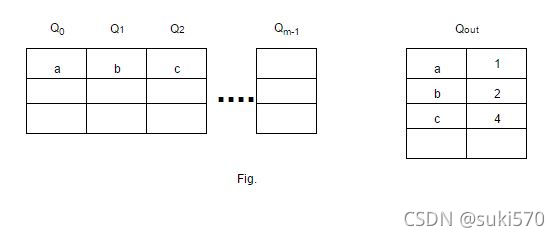
我们可以从图中看出 m 个 LRU 队列是如何放置在缓存中的。 还可以从图中看出 Qout 是如何存储块标识符及其对应的访问频率的。 a 被放置在 Q0 中,因为它最近只被访问过一次,我们可以在 Qout 中检查 b 和 c 如何分别放置在 Q1 和 Q2 中,因为它们的访问频率是 2 和 4。放置块的队列取决于访问 频率(f)作为 log2(f)。 当缓存已满时,在这种情况下,第一个被驱逐的块将是 Q0 的头部。 如果 a 被再次访问,它将移动到 b 下方的 Q1。
Yuanyuan Zhou, James Philbin, and Kai Li. The multi- queue replacement algorithm for second level buffer caches. In Proceedings of the General Track: 2001 USENIX Annual Technical Conference, pages 91–104, Berkeley, CA, USA, 2001. USENIX Association.
这篇关于缓存替换算法简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








