本文主要是介绍用Python制作欧洲杯可视化图表!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

最近不少小伙伴都会熬夜看欧洲杯。今年的欧洲杯相比起往年的欧洲杯来说,可谓是冷门频出,出乎意料。
真的不知道,第一会花落谁家~
本期小F就和大家分享一下,用Python和Matplotlib绘制一个足球运动员的数据可视化图表。
来看一下C罗的情况,跟老詹一样高龄,真的佩服。
数据来源于下面两个网站,Understat和Fbref。
链接:https://understat.com/
链接:https://fbref.com/en/
欧洲足球五大联赛,英超、意甲、西甲、德甲、法甲。
先看一下射门数据的可视化,本质上和篮球的出手点图差不多,都是散点图类型。
导入相关的Python库。
import requests
from bs4 import BeautifulSoup as soup
import json
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import matplotlib as mpl从Understat网站爬取射门数据,使用BeautifulSoup、JSON和pandas解析和处理数据。
# 请求数据, C罗的ID为2371
url = 'https://understat.com/player/2371'
html = requests.get(url)# 解析处理数据
parse_soup = soup(html.content, 'lxml')
scripts = parse_soup.find_all('script')
strings = scripts[3].stringind_start = strings.index("('")+2
ind_end = strings.index("')")
json_data = strings[ind_start:ind_end]
json_data = json_data.encode('utf8').decode('unicode_escape')
data = json.loads(json_data)
print(data)
# 处理数据, 包含射门位置、预期进球、射门结果、赛季
x = []
y = []
xg = []
result = []
season = []
for i, _ in enumerate(data):for key in data[i]:if key == 'X':x.append(data[i][key])if key == 'Y':y.append(data[i][key])if key == 'xG':xg.append(data[i][key])if key == 'result':result.append(data[i][key])if key == 'season':season.append(data[i][key])
columns = ['X', 'Y', 'xG', 'Result', 'Season']
df_understat = pd.DataFrame([x, y, xg, result, season], index=columns)
df_understat = df_understat.T
df_understat = df_understat.apply(pd.to_numeric, errors='ignore')
# 得到最终的结果
print(df_understat)此处的ID,通过查询球员名字可知
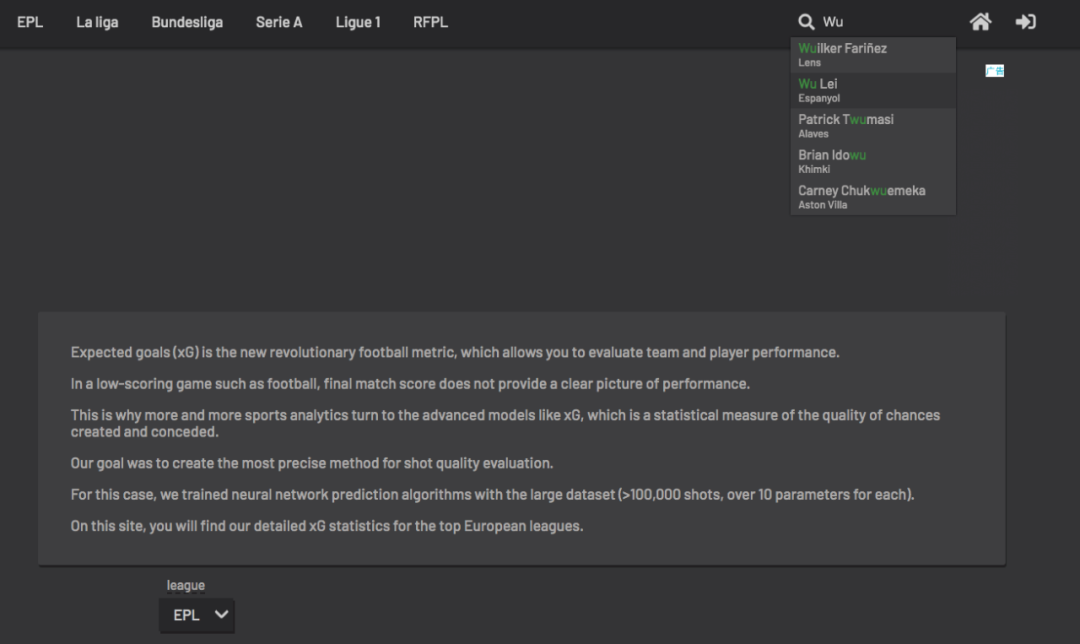
查询中国球员武磊,点击访问,在地址栏处,可以看到球员ID。
得到数据如下。
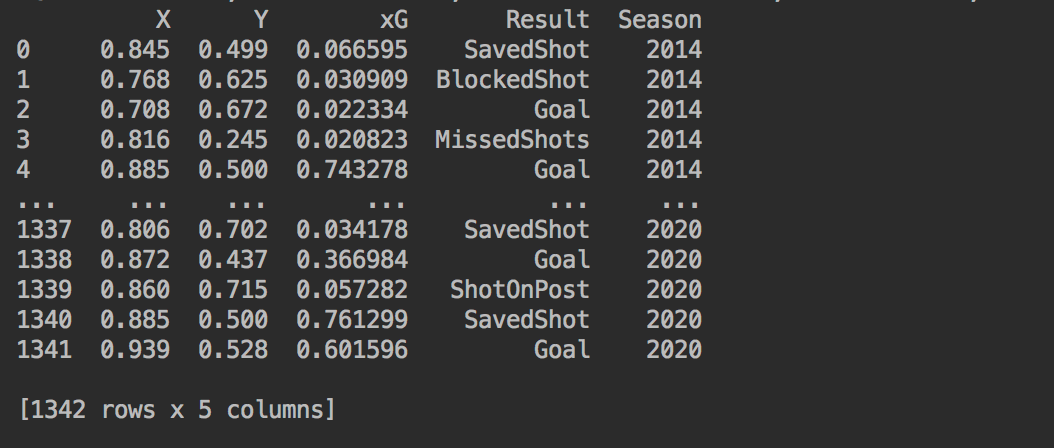
包含射门位置(x、y)、xG(预期进球)、射门结果、赛季。
其中x、y的坐标值为0~1之间,不适合在Matplotlib显示,所以选择放大100倍。
df_understat['X'] = df_understat['X'].apply(lambda x: x*100)
df_understat['Y'] = df_understat['Y'].apply(lambda x: x*100)
print(df_understat)得到结果如下。
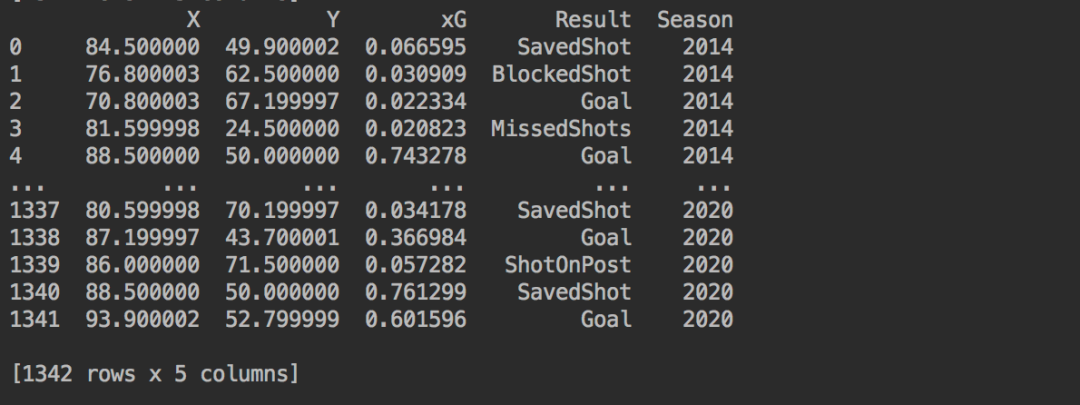
既然已经成功获取Understat网站的数据,就可以去获取Fbref网站的数据啦。
这里是球员的一些个人信息,以及赛季的平均数据。
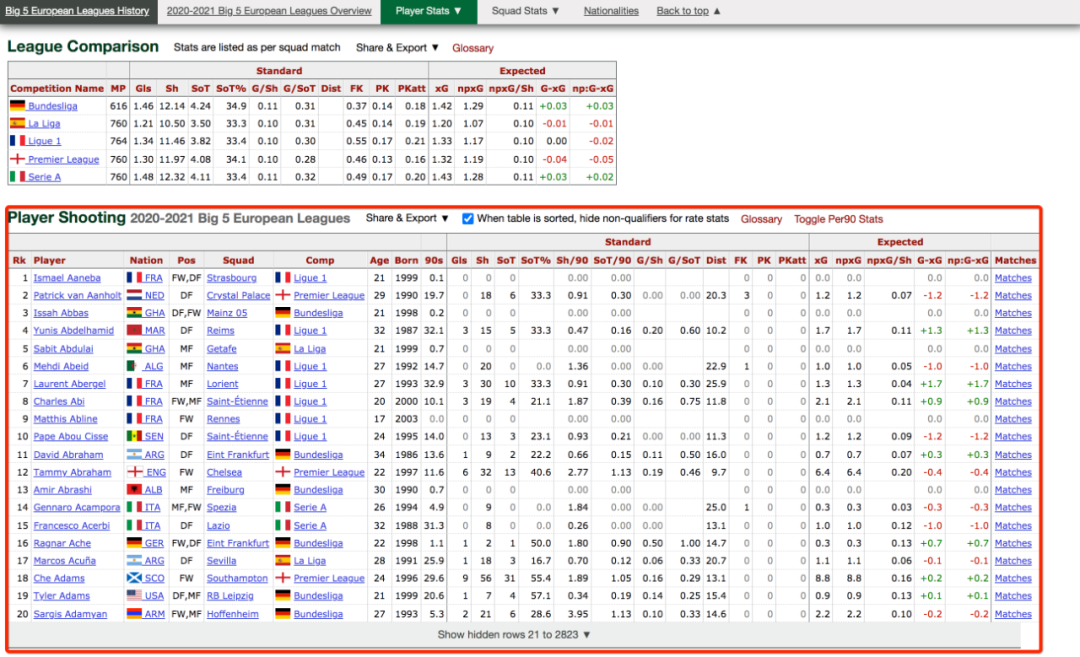
比如全名、国家、位置、俱乐部、联赛、年龄、出生年份、上场时间、得分数据等等。
因为网页的数据是表格形式,所以直接使用pandas的read_html函数,解析表格爬取数据。
这个网站需要取消一下证书验证,要不然连接不成功。
# 全局取消证书验证import ssl
ssl._create_default_https_context = ssl._create_unverified_context获取球员的相关数据。
def readfromhtml(filepath):# 选择第二个表格df = pd.read_html(filepath)[0]column_lst = list(df.columns)for index in range(len(column_lst)):column_lst[index] = column_lst[index][1]df.columns = column_lstdf.drop(df[df['Player'] == 'Player'].index, inplace=True)df = df.fillna('0')df.set_index('Rk', drop=True, inplace=True)try:df['Comp'] = df['Comp'].apply(lambda x: ' '.join(x.split()[1:]))df['Nation'] = df['Nation'].astype(str)df['Nation'] = df['Nation'].apply(lambda x: x.split()[-1])except:print('Error in uploading file:' + filepath)finally:df = df.apply(pd.to_numeric, errors='ignore')return df# 获取2020-2021欧洲五大联赛球员数据
df_fbref = readfromhtml('https://fbref.com/en/comps/Big5/shooting/players/Big-5-European-Leagues-Stats')
print(df_fbref)得到结果如下。
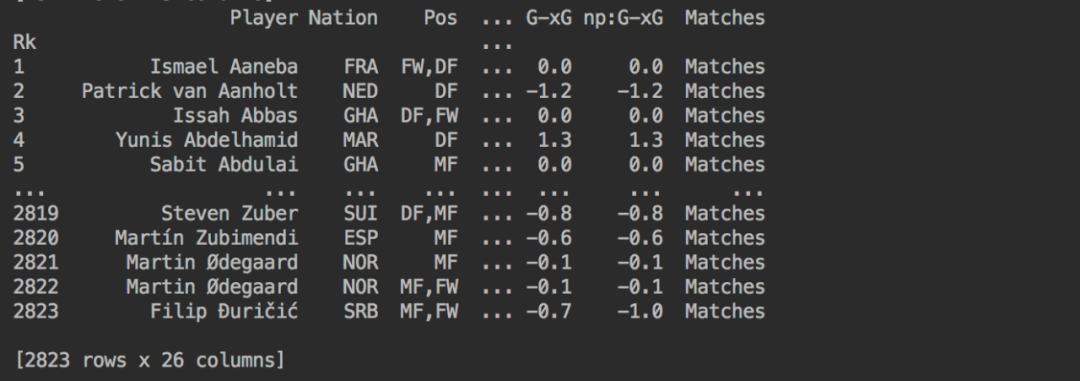
数据都已经准备好了,那么我们就可以将数据绘制到图表上。
# 安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple mplsoccer
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple highlight_text先安装mplsoccer、highlight_text这两个Python库。
其中mplsoccer库可以自定义绘制足球场,无需我们自己绘制场地图。
想了解更多,可以访问它的GitHub地址。
https://github.com/andrewRowlinson/mplsoccer

初始化一些设置,画布背景色、字体颜色、默认字体,字体大小,此处选择中文字体。
from highlight_text import ax_text,fig_text
import mplsoccer# 背景色
background = '#D6DBD9'
# 字体颜色
text_color = 'black'
mpl.rcParams['xtick.color'] = text_color
mpl.rcParams['ytick.color'] = text_color
mpl.rcParams['text.color'] = text_color
# 中文字体
mpl.rcParams['font.family'] = 'Songti SC'
mpl.rcParams['legend.fontsize'] = 12新建一个画布。
# 新建画布
fig, ax = plt.subplots(figsize=(10, 8))
# 关闭坐标轴
ax.axis('off')
# 背景色填充
fig.set_facecolor(background)
plt.show()显示如下。
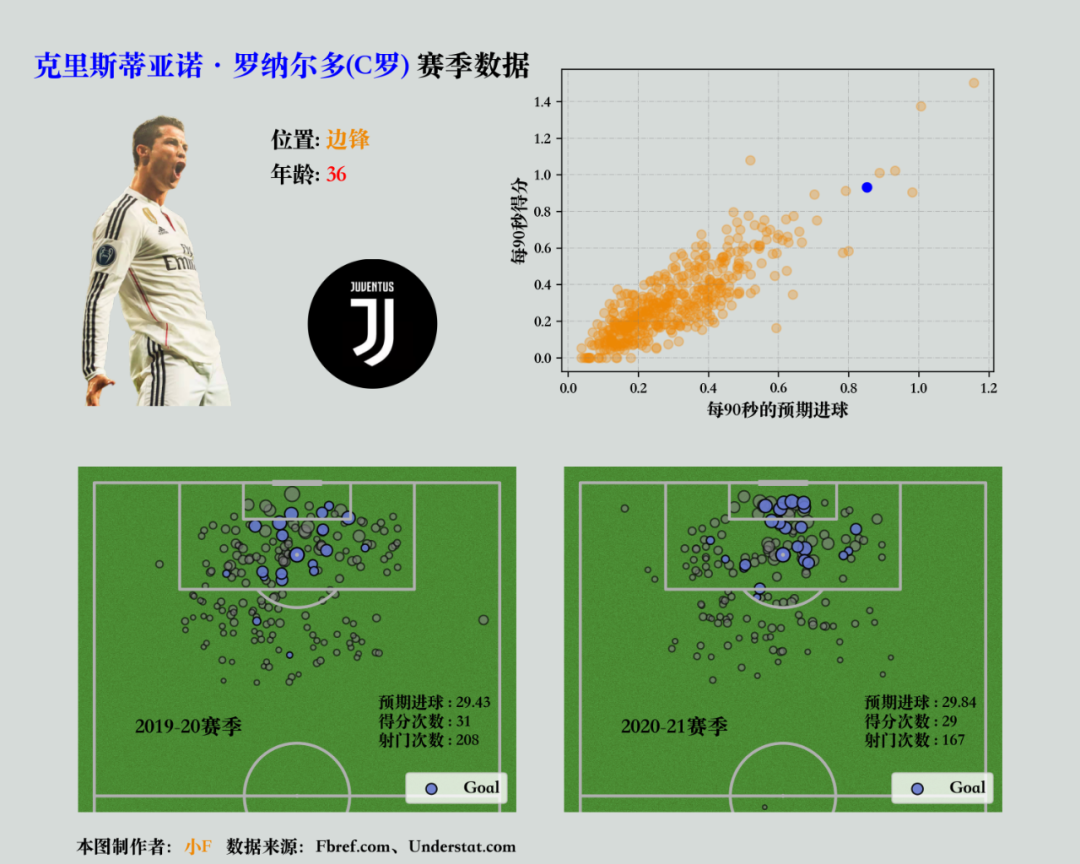
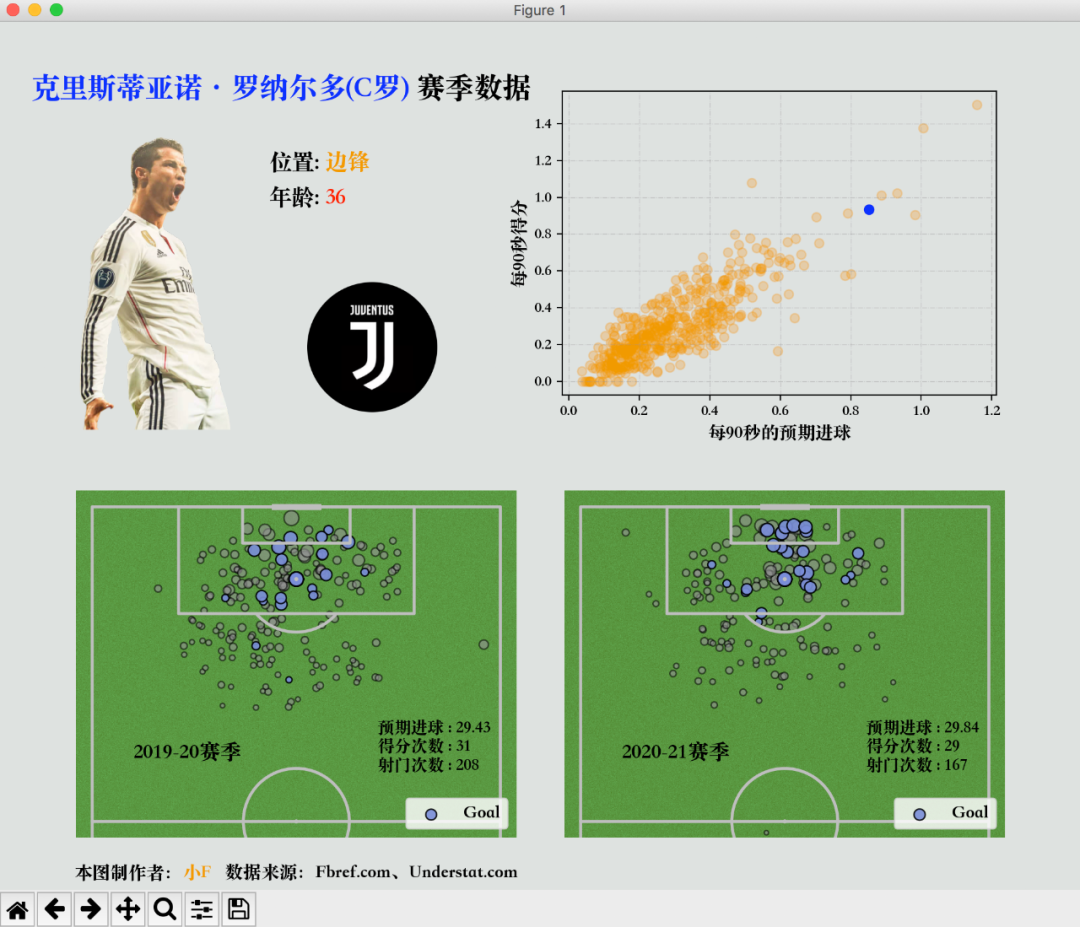
绘制19-20赛季,C罗的进球情况。
# 垂直方向半个足球场
pitch = mplsoccer.VerticalPitch(half=True, pitch_type='opta', line_zorder=3, pitch_color='grass')
# 图表大小
ax_opta1 = fig.add_axes((0.05, 0.06, 0.45, 0.4))
ax_opta1.patch.set_facecolor(background)
pitch.draw(ax=ax_opta1)
plt.show()通过设置mplsoccer的参数,绘制半个足球场。
果然,左下方有半个足球场。
将射门数据用散点图表示,分为进球得分和未成功进球得分两种情况。
# 2019-2020赛季, C罗射门位置散点图(未得分), 透明度0.6
df_fil = df_understat.loc[df_understat['Season'] == 2019]pitch.scatter(df_fil[df_fil['Result'] != 'Goal']['X'], df_fil[df_fil['Result'] != 'Goal']['Y'],s=np.sqrt(df_fil[df_fil['Result'] != 'Goal']['xG'])*100, marker='o', alpha=0.6,edgecolor='black', facecolor='grey', ax=ax_opta1)
plt.show()未得分射门散点图。

得分散点图。
# 2019-2020赛季, C罗射门位置散点图(得分), 透明度0.9
pitch.scatter(df_fil[df_fil['Result'] == 'Goal']['X'], df_fil[df_fil['Result'] == 'Goal']['Y'],s=np.sqrt(df_fil[df_fil['Result'] == 'Goal']['xG'])*100, marker='o', alpha=0.9,edgecolor='black', facecolor='#6778d0', ax=ax_opta1, label='Goal')plt.show()结果如下,失败的比成功的多。

这样,我们就将C罗在2019-2020赛季的所有射门点数据可视化出来了。
其中散点的大小,是预期进球的大小。
添加标签及图例,设置相应的位置、文字、字体等设置。
# 添加图例
ax_opta1.legend(loc='lower right').get_texts()[0].set_color("black")# 文字信息
ax_opta1.text(30, 61, '得分次数 : '+str(len(df_fil[df_fil['Result'] == 'Goal'])), weight='bold', size=11)
ax_opta1.text(30, 64, f"预期进球 : {round(sum(df_fil['xG']),2)}", weight='bold', size=11)
ax_opta1.text(30, 58, '射门次数 : '+str(len(df_fil)), weight='bold', size=11)
ax_opta1.text(90, 60, '2019-20赛季', weight='bold', size=14)plt.show()成功添加附加信息。
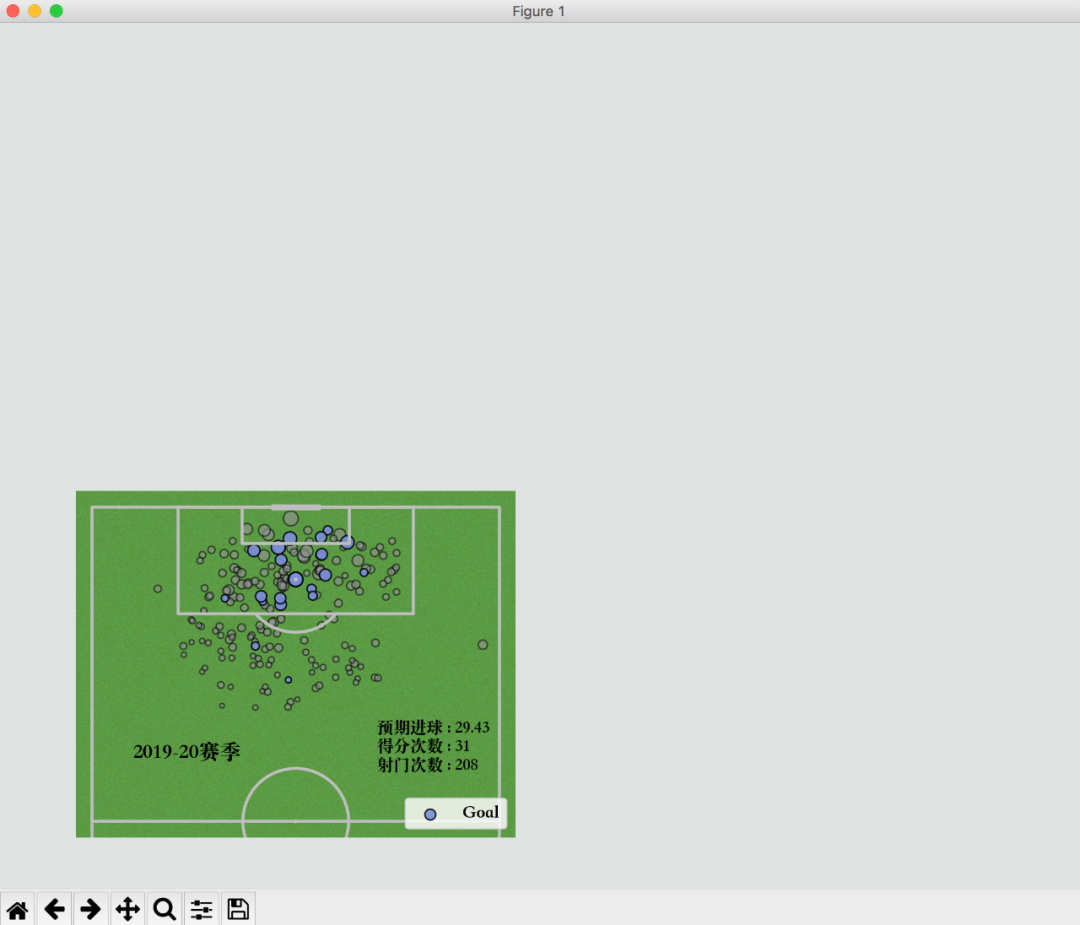
显示赛季、xG、得分次数、射门次数信息。
同样将20-21赛季的数据绘制出来,放置在19-20赛季的右侧。
# 2020-2021赛季, C罗射门位置散点图
ax_opta2 = fig.add_axes((0.50, 0.06, 0.45, 0.4))
ax_opta2.patch.set_facecolor(background)
pitch.draw(ax=ax_opta2)# 根据条件, 筛选数据
df_fil = df_understat.loc[df_understat['Season'] == 2020]
# 未得分
pitch.scatter(df_fil[df_fil['Result'] != 'Goal']['X'], df_fil[df_fil['Result'] != 'Goal']['Y'],s=np.sqrt(df_fil[df_fil['Result']!='Goal']['xG'])*100, marker='o', alpha=0.6,edgecolor='black', facecolor='grey', ax=ax_opta2)
# 得分
pitch.scatter(df_fil[df_fil['Result']=='Goal']['X'], df_fil[df_fil['Result'] == 'Goal']['Y'],s=np.sqrt(df_fil[df_fil['Result'] == 'Goal']['xG'])*100, marker='o', alpha=0.9,edgecolor='black', facecolor='#6778d0', ax=ax_opta2, label='Goal')# 添加图例, 文字信息
ax_opta2.legend(loc='lower right').get_texts()[0].set_color("black")ax_opta2.text(30, 61, '得分次数 : '+str(len(df_fil[df_fil['Result'] == 'Goal'])), weight='bold', size=11)
ax_opta2.text(30, 64, f"预期进球 : {round(sum(df_fil['xG']),2)}", weight='bold', size=11)
ax_opta2.text(30, 58, '射门次数 : '+str(len(df_fil)), weight='bold', size=11)
ax_opta2.text(90, 60, '2020-21赛季', weight='bold', size=14)plt.show()结果如下。
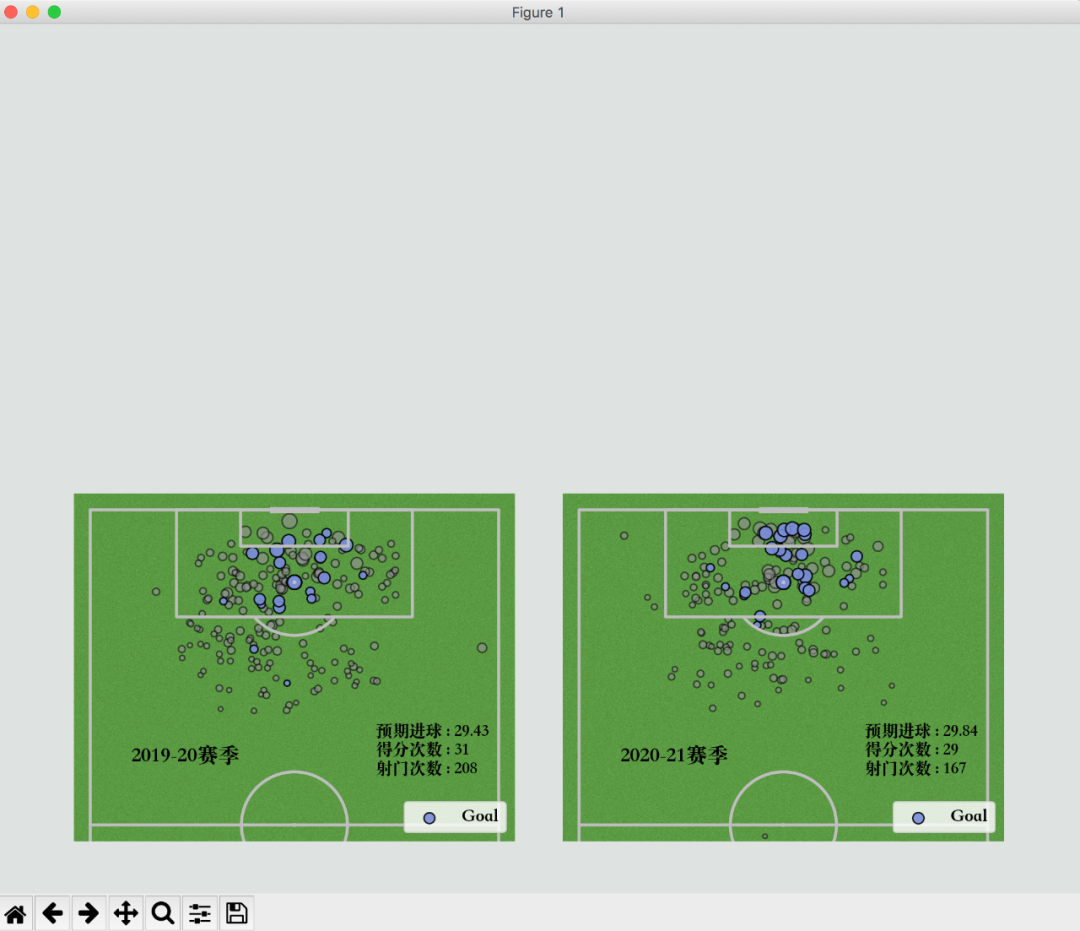
C罗老当益壮啊,状态一点也没有下滑。
下面接着绘制所有球员的数据散点图,看看C罗的数据能在哪一档?
# 初始化
ax_scatter = fig.add_axes([0.52, 0.57, 0.4, 0.35])
ax_scatter.patch.set_facecolor(background)
plt.show()创建一个坐标轴。
首先对数据进行筛选,上场时间最少要有900s,而且位置为前锋此类的。
毕竟我们不能拿个守门员,跟C罗比数据吧,参考意义不大。
# 得到散点图的X, Y坐标值
no_90s = 10
df_fil = df_fbref[df_fbref['90s'] >= no_90s]
# 前锋位置
df_fil = df_fil[df_fil['Pos'].apply(lambda x: x in ['FW', 'MF,FW', 'FW,MF'])]# 每90s预期进球和得分次数
x, y = (df_fil['xG']/df_fil['90s']).to_list(), (df_fil['Gls']/df_fil['90s']).to_list()# 生成所有前锋位置, 数据散点图
ax_scatter.scatter(x, y, alpha=0.3, c='#EF8804')plt.show()所有球员每90s预期进球和得分次数的数据情况。

现在我们筛选出C罗的数据,在散点图上用不同的颜色及透明度来突出显示它。
# C罗的数据
df_player = df_fil[df_fil['Player'] == 'Cristiano Ronaldo']
ax_scatter.scatter(df_player['xG']/df_player['90s'], df_player['Gls']/df_player['90s'], c='blue')plt.show()结果如下。
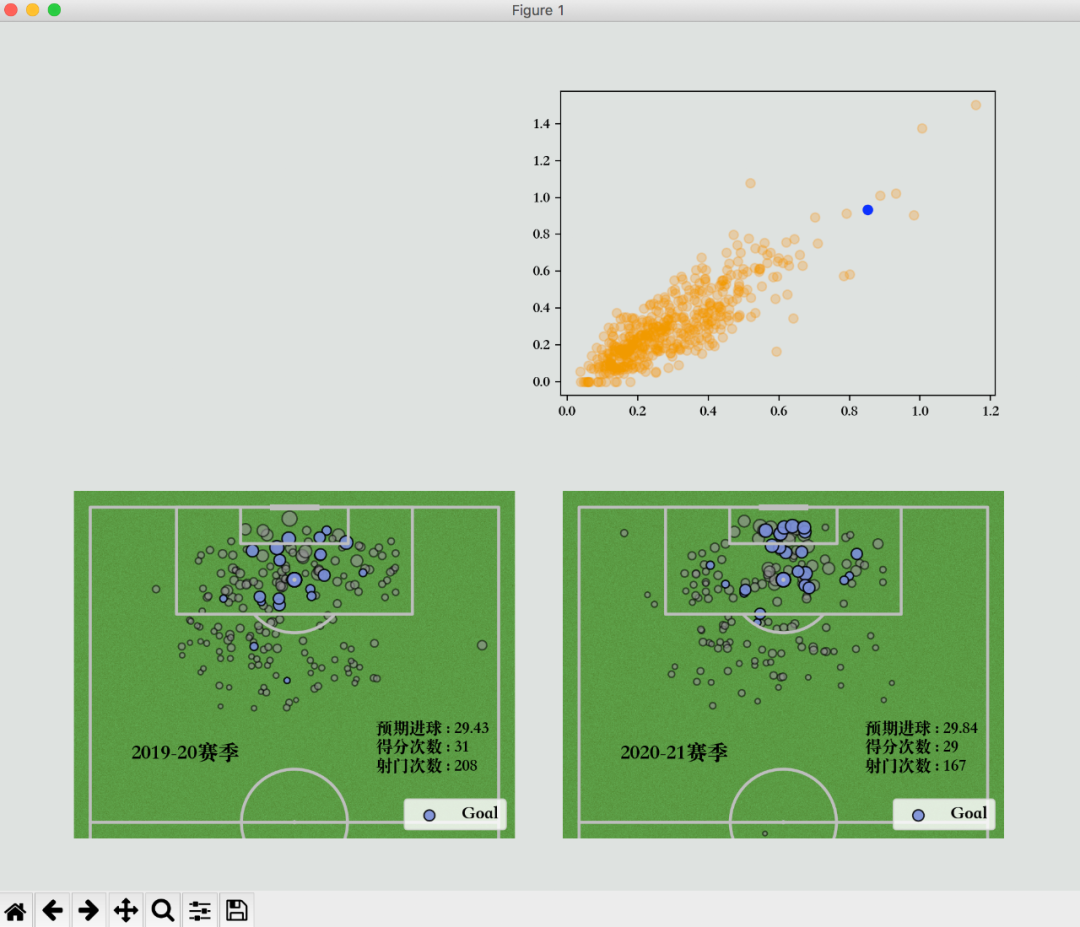
可以看到C罗的数据还是比较高效的,虽不是第一,但也是前几的存在。
最后给散点图添加网格线,以及x轴和y轴标签。
# 添加网格线及标签
ax_scatter.grid(b=True, color='grey',linestyle='-.', linewidth=0.5,alpha=0.4)
ax_scatter.set_xlabel('每90秒的预期进球', fontdict={'fontsize': 12, 'weight': 'bold', 'color': text_color})
ax_scatter.set_ylabel('每90秒得分', fontdict=dict(fontsize=12, weight='bold', color=text_color))plt.show()结果如下。
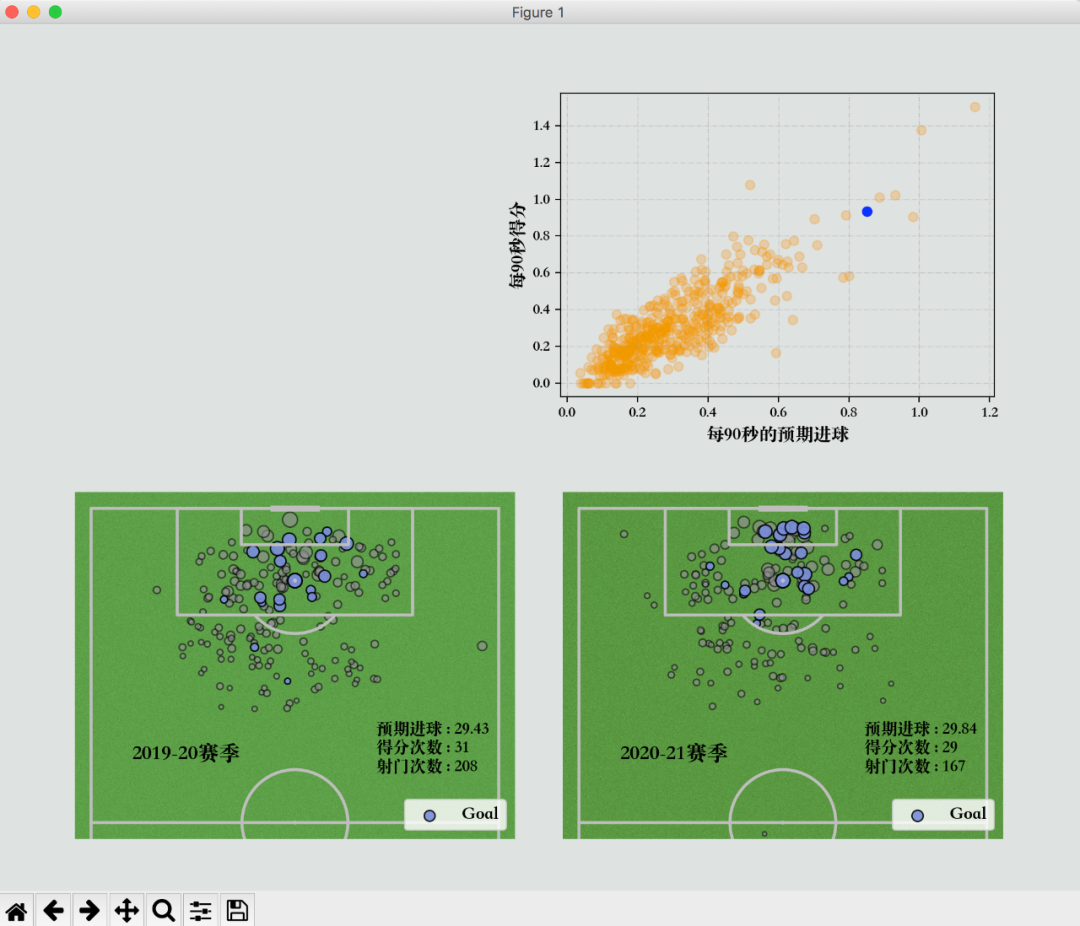
不愧是C罗,在2020-21赛季几乎每90秒就能进1颗球。
18年就已经有一个记录!C罗成历史第一位在90分钟内每分钟都有进球的球员。
最后添加文本信息,包含标题,C罗的头像,场上位置、年龄、效力球队。
此处使用hightlight-text库,可以高亮文本。
# 添加C罗的头像
ax_player = fig.add_axes([0.03, 0.53, 0.25, 0.45])
ax_player.axis('off')
im = plt.imread('ronaldo.png')
ax_player.imshow(im)# 添加标题信息
fig_text(0.03, 0.94, "<克里斯蒂亚诺·罗纳尔多(C罗)> 赛季数据", weight='heavy', size=19, highlight_textprops=[{'color': 'blue'}])
fig_text(0.25, 0.85, '位置: <边锋>',weight='bold', size=15, highlight_textprops=[{'color':'#EF8804'}])
fig_text(0.25, 0.81, '年龄: <36>',weight='bold', size=15, highlight_textprops=[{'color':'red'}])# 添加俱乐部logo
ax_team = fig.add_axes([0.27, 0.55, 0.15, 0.15])
ax_team.axis('off')
im = plt.imread('FCJ.png')
ax_team.imshow(im)# 添加备注
fig_text(0.07, 0.03, '本图制作者:<小F> 数据来源:Fbref.com、Understat.com',size=12, highlight_textprops=[{'color': '#EF8804'}], weight='bold')
plt.show()C罗的头像、效力的队伍logo,都是小F自己制作的。
得到结果如下。
保存为图片。
# 保存为图片
plt.savefig('ronaldo_viz.png', dpi=300, facecolor=background)看起来还不错哦。
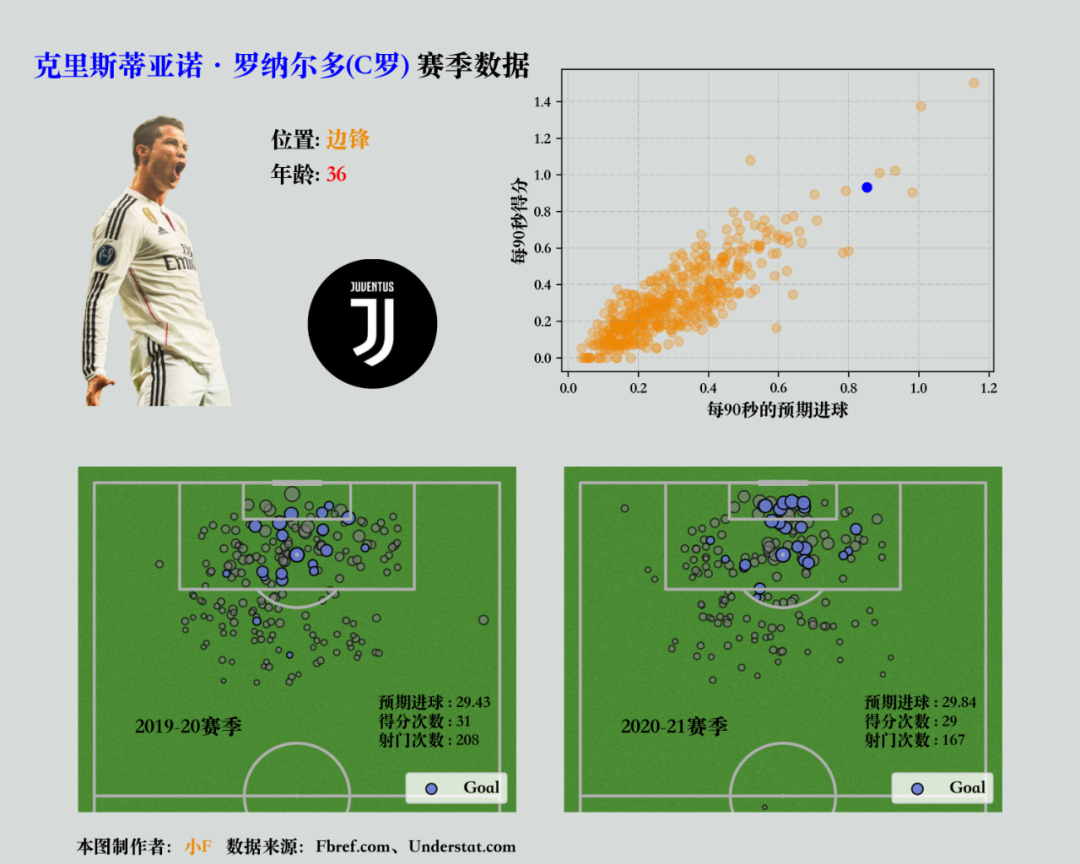
好了,本期的分享就到此结束了,有兴趣的小伙伴可以自行去实践学习。
使用到的代码及文件都已上传,公众号回复「小助手」即可获取足球的源码。
快给自己喜欢的足球运动员,也制作一个赛季数据面板吧!
推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领AI全套资料!
这篇关于用Python制作欧洲杯可视化图表!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




