本文主要是介绍Jetson nano配置排坑系列,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Jetson nano配置排坑系列
烧写镜像
利用balenaEtcher将镜像文件~~(使用官方镜像,下载速度也够快,毕竟官方的更保险)nv-jetson-nano-sd-card-image-r32.4.2.zip~~(踩坑系列一:tm的,垃圾官方,镜像文件烧入会一直出错,垃圾玩意,错了几个小时,推荐这个链接里面的https://developer.nvidia.com/embedded/dlc/jetson-nano-dev-kit-sd-card-image)写入tf卡中,插入Jetson nano卡槽,通电即可启用。

换源
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
sudo vim /etc/apt/sources.list
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial main multiverse restricted universedeb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial-security main multiverse restricted universedeb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial-updates main multiverse restricted universedeb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial-backports main multiverse restricted universedeb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial main multiverse restricted universedeb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial-security main multiverse restricted universedeb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial-updates main multiverse restricted universedeb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial-backports main multiverse restricted universe
换源之后,进行更新。
sudo apt-get update
sudo apt-get full-upgrade
中文拼音配置
sudo apt-get install ibus-pinyin
之后在系统设置里,打开Language Support。我自己的Jetson nano上自动弹出了一个更新(更新了大概10多分钟)。之后就有了汉语(中国)语言。


在命令行中,输入
reboot
#重启计算机,更新语言
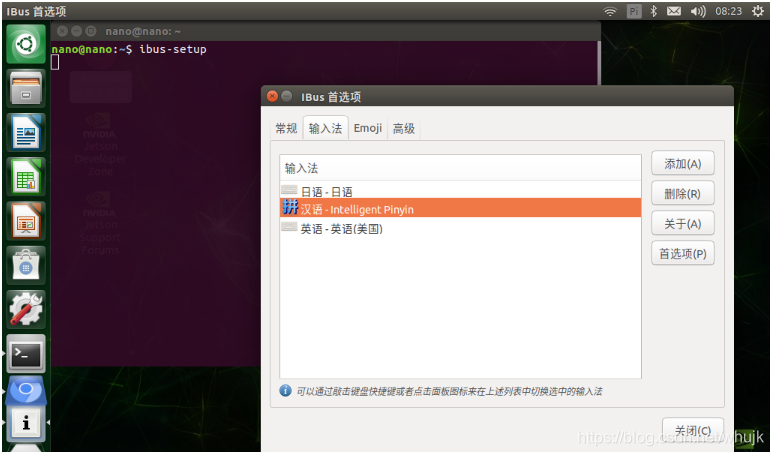
ibus-setup
弹出窗口,在输入法里面添加拼音。之后便可以使用中文。
配置python环境
sudo apt-get install python3-pip python3-dev
#安装pip
python -m pip install -U --force-reinstall pip
#升级pip至20.1.1
只安装了pip3。
-
pip换源
mkdir .pip sudo vim .pip/pip.conf内容如下:
[global]trusted-host = mirrors.aliyun.com index-url = http://mirrors.aliyun.com/pypi/simple
安装Typora
想下载个Typora在Jetson nano上也能编辑进度,以及处理方法,但是用网上的办法都会由于网速过慢导致失败。想来还是外网速度较慢的问题。
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys BA300B7755AFCFAEsudo add-apt-repository 'deb http://typora.io linux/'sudo apt-get updatesudo apt-get install typora
但实际多运行了几次后发现只是外网链接网络状态不稳定,可是运行后还是有报错,根据其他博客补添依赖包。
sudo apt-get install libapt-pkg-dev
sudo apt-get install apt-transport-https
sudo apt-get update
最后还是以失败告终。回到/etc/apt/sources.list里面将文件修改回原内容。
关于此文档的编辑,还只能停留在windows上,用Jetson nano网页传图片过来。
(由此我也发掘了另外一种思路:通过xshell(------一个软件)远程连接!!然后也可以进行文件传输,特喵的,既然nano上这么多软件这毛病那毛病的,就在windows上编写呗,只需要一个较快的文件传输渠道就行了。)
远程连接
ok,为了上一个文件传输的目标,这里又想办法开始了远程连接,当然,远程连接的好处自然不止文件传输一个目的。
这个比较简单,只需要安装好xshell软件(windows上的,淘宝上到处卖正版的,4,5块钱就一个,比起800多的板子,这个够便宜的了)
首先在Jetson nano的命令行上,查看Jetson nano主机号地址。无线网就在wlan中找inet地址。
ifconfig

找到inet地址后直接在xshell中新建对话,主机号输入刚刚的地址:
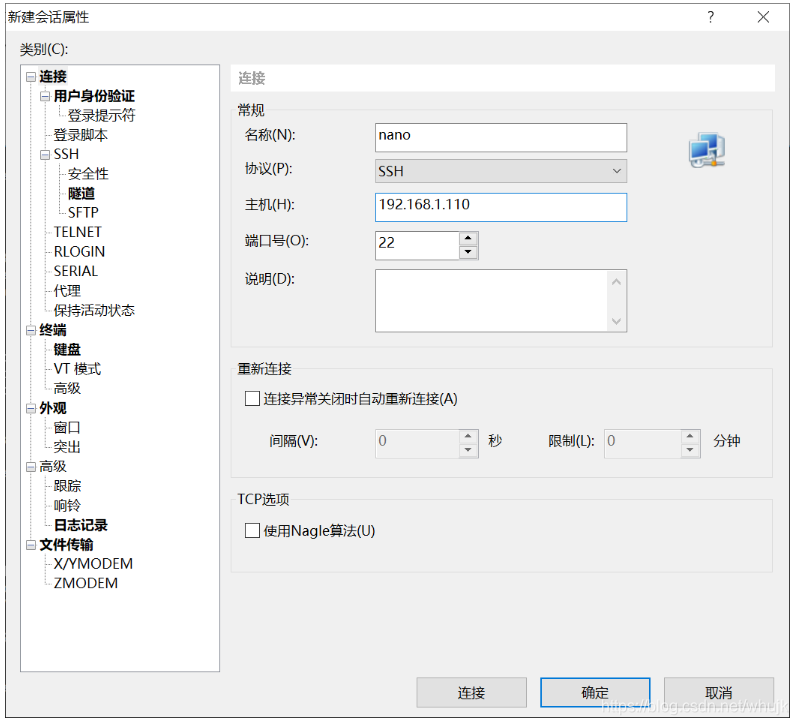
之后第一次连接出现用户名和密码的验证,以后只需要连接电源(必须要有连接HDMI显示器,此处我觉得原因在于没有连接显示器,Jetson nano不会自动连接一个wifi,导致ip地址变化,通过ip地址无法连接,如果是连接有线网,则可以在第一次连接后记住ip地址,此后通过有线网即可连接),打开会话便可以使用远程连接。
文件传输功能通过

点开之后选定nano里面的文件夹,在左侧设定目标地址,便可以自由传输文件

tensorflow安装与配置
-
提前准备在windows下下载好tensorflow_gpu-2.0.0+nv19.11-cp36-cp36m-linux_aarch64.whl。地址如下:https://developer.download.nvidia.cn/compute/redist/jp/v42/tensorflow-gpu/。以下为踩坑环节。。。。。。
sudo apt-get install libhdf5-serial-dev hdf5-tools zlib1g-dev zip libjpeg8-dev libhdf5-dev python3-pip #安装相关依赖 pip3 install -U numpy # 需要编译安装,用时很长,所以单独安装 pip3 install -U h5py # 需要编译安装,用时非常长,我的板子装这个20多分钟才装完 pip3 install -U grpcio absl-py py-cpuinfo psutil portpicker six mock requests gast astor termcolor #安装相关python库 pip3 install --pre --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v42 tensorflow-gpu下载了这么多东西,你是不是也头疼了,因为东西太多了,而且各种配置都缺东少西,虽然我之前在自己电脑的ubuntu上,是使用的Tensorflow,也跑过各种不一样的坑,但是还是听从了一个学姐的建议,转向了pytorch,而接下来几天配置的顺利,也让我直呼,pytorch真香。
pytorch安装与配置
-
提前准备
在windows下提前下载好torch-1.0.0a0+bb15580-cp36-cp36m-linux_aarch64.whl(前述为1.0版,这里我用的1.1版)。
-
代码配置
参考如下配置表格:

-
torchvision安装
torchvision包是服务于pytorch深度学习框架的,用来生成图片,视频数据集,和一些流行的模型类和预训练模型,所以下载是有必要的。
直接在torchvision中执行python setup.py,出现问题。

原因在于python代指了python2.7,所以要把之前图片上的python改为python3.这之后也是终于配置成功。
sudo python3 setup.py install
- 验证安装成功:

装成功:
这篇关于Jetson nano配置排坑系列的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






