本文主要是介绍公开数据集:灵长类动物多通道感觉运动皮层电生理学的研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Nonhuman Primate Reaching with Multichannel Sensorimotor Cortex Electrophysiology. 1
公开数据集网址:https://zenodo.org/records/3854034
目录
- General Description
- Possible uses
- Variable names
- Decoder Results
- Videos
- Supplements
- Contact Information
- Citation
General Description
该数据集包括:
- 细胞外和同时记录的峰值的阈值跨越时间,排序成单位(最多5个,包括一个“散列”单位) ,以及排序的波形片段;
- 触手指尖的 x,y 位置和触及目标的 x,y 位置(两者均以250赫兹采样)。
行为任务是使自我节奏达到目标排列在一个网格(例如8x8)没有间隔或移动前延迟间隔。一只猴子伸出右臂(左半球记录) ,另一只猴子伸出左臂(右半球)。在一些会议记录从 M1和 S1阵列(192个通道) ; 在大多数会议 M1记录是单独的(96个通道)。
来自两个灵长类受试者的数据包括: 猴子1(“ Indy”,跨越约10个月)的37个sessions和猴子2(“ Loco”,跨越约1个月)的10个sessions,分别达到约20,000次和猴子1和6,500次的2。
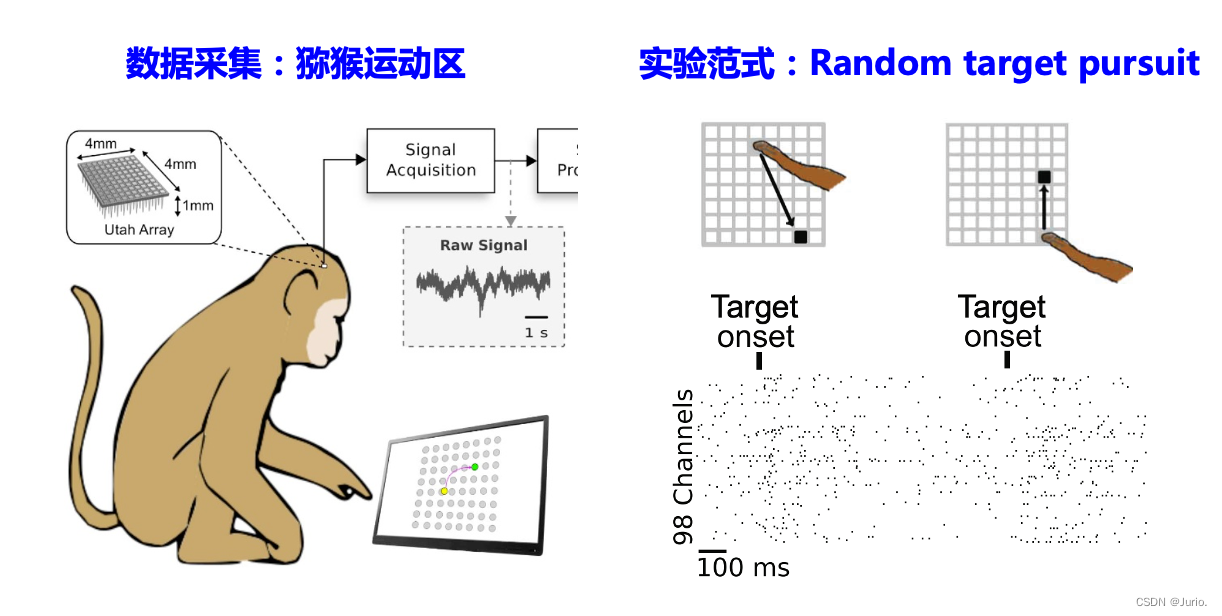
Possible uses
这些数据对于训练 BCI 解码器是理想的,特别是因为它们没有被分割成试验。我们期望该数据集对于那些希望设计改进的感觉运动皮层电刺激模型或者为比较不同的脑机接口解码器提供同等基础的研究人员将是有价值的。其他用途可能包括手臂运动学统计分析,尖峰噪声相关性或信号相关性,或用于探索会话期间细胞外记录的稳定性或变异性。
Variable names
每个文件包含以下格式的数据。在下面,n 表示记录通道的数量,u 表示排序单元的数量,k 表示样本的数量。
chan_names- n x 1- 信道标识符字符串的单元格数组,例如“ M1001”。
cursor_pos- k x 2- 光标在笛卡尔坐标系(x,y)中的位置,mm。
finger_pos- k x 3 or k x 6- 工作指尖在笛卡尔坐标系(z,-x,-y)中的位置,由手动跟踪器以厘米为单位报告。因此,光标位置是指尖位置的仿射变换,使用以下矩阵:
( 0 0 − 10 0 0 − 10 ) \begin{pmatrix} 0 & 0 \\ -10 & 0 \\ 0 & -10 \end{pmatrix}\ 0−10000−10
注意,对于某些会话,finger_pos 还包括传感器的方向; 因此,完整状态是: (z,-x,-y,方位角,仰角,滚动)。
- 工作指尖在笛卡尔坐标系(z,-x,-y)中的位置,由手动跟踪器以厘米为单位报告。因此,光标位置是指尖位置的仿射变换,使用以下矩阵:
target_pos- k x 2- 目标在笛卡尔坐标系(x,y)中的位置,mm。
t- k x 1- 对应于 cursor_pos、 finger_pos 和 target_pos 的每个示例的时间戳,秒。
spikes- n x u- 尖峰事件向量的细胞阵列。单元格数组中的每个元素都是峰值事件时间戳的向量(以秒为单位)。第一个单元(u1)是“未排序”单元,这意味着它包含在该通道上的峰值被排序成其他单元(u2,u3等)后仍然存在的阈值交叉。对于一些会话峰值被排序成多达2个单元(即 u = 3) ; 对于其他会话,4个单元(u = 5)。
wf- n x u- 尖峰事件波形“片段”的单元阵列。细胞阵列中的每个元素都是尖峰事件波形的矩阵。每个波形对应一个“尖峰”的时间戳。波形样本是微伏的。
Decoder Results
这些数据被用来拟合解码器模型,如 Makin 等[1]所报道的。为了帮助与其他解码器进行比较,我们在文件 refh_result 中包含性能摘要(对于每个会话、解码器、 bin-width 等)。Csv,包含以下列:
session- 标识符,例如 “indy_20160407_02”monkey- “indy” 或 “loco” 之一num_neurons- 解码器中使用的特征总数num_training_samples- 用于训练解码器的样本数(在指定的容量宽度)(从文件开始按顺序)num_testing_samples- 用于评估解码器的样本数(顺序,直到文件结束)kinematic_axis- “posx”, “posy”, “velx”, “vely”, “accx” 或 “accy” 之一bin_width- “16”, “32”, “64” 或 “128” 之一decoder- “regression”, “KF_observed”, “KF_static”, “KF_dynamic”, “UKF”, “rEFH_static” 或 “rEFH_dynamic” 之一rsq- 决定系数,R2snr- 信噪比,SNR = -10 log10(1-R2)
Videos
在一些session中,我们使用一个专用的硬件视频采集器记录刺激呈现显示的屏幕播放。因此,这些视频是对猴子受到的刺激和反馈的忠实表达,可以在以下会议中使用:
- indy_20160921_01
- indy_20160930_02
- indy_20160930_05
- indy_20161005_06
- indy_20161006_02
- indy_20161007_02
- indy_20161011_03
- indy_20161013_03
- indy_20161014_04
- indy_20161017_02
Supplements
从这个数据集中提取的原始宽带神经记录可用于以下session:
- indy_20160622_01: doi:10.5281/zenodo.1488440
- indy_20160624_03: doi:10.5281/zenodo.1486147
- indy_20160627_01: doi:10.5281/zenodo.1484824
- indy_20160630_01: doi:10.5281/zenodo.1473703
- indy_20160915_01: doi:10.5281/zenodo.1467953
- indy_20160916_01: doi:10.5281/zenodo.1467050
- indy_20160921_01: doi:10.5281/zenodo.1451793
- indy_20160927_04: doi:10.5281/zenodo.1433942
- indy_20160927_06: doi:10.5281/zenodo.1432818
- indy_20160930_02: doi:10.5281/zenodo.1421880
- indy_20160930_05: doi:10.5281/zenodo.1421310
- indy_20161005_06: doi:10.5281/zenodo.1419774
- indy_20161006_02: doi:10.5281/zenodo.1419172
- indy_20161007_02: doi:10.5281/zenodo.1413592
- indy_20161011_03: doi:10.5281/zenodo.1412635
- indy_20161013_03: doi:10.5281/zenodo.1412094
- indy_20161014_04: doi:10.5281/zenodo.1411978
- indy_20161017_02: doi:10.5281/zenodo.1411882
- indy_20161024_03: doi:10.5281/zenodo.1411474
- indy_20161025_04: doi:10.5281/zenodo.1410423
- indy_20161026_03: doi:10.5281/zenodo.1321264
- indy_20161027_03: doi:10.5281/zenodo.1321256
- indy_20161206_02: doi:10.5281/zenodo.1303720
- indy_20161207_02: doi:10.5281/zenodo.1302866
- indy_20161212_02: doi:10.5281/zenodo.1302832
- indy_20161220_02: doi:10.5281/zenodo.1301045
- indy_20170123_02: doi:10.5281/zenodo.1167965
- indy_20170124_01: doi:10.5281/zenodo.1163026
- indy_20170127_03: doi:10.5281/zenodo.1161225
- indy_20170131_02: doi:10.5281/zenodo.854733
Contact Information
我们将很高兴听到你如果你发现这个数据集有价值。通讯作者: J. E. O’Doherty joeyo@neuroengineer.com。
Citation
@misc{ODoherty:2017, author = {O'{D}oherty, Joseph E. and Cardoso, Mariana M. B. and Makin, Joseph G. and Sabes, Philip N.}, title = {Nonhuman Primate Reaching with Multichannel Sensorimotor Cortex electrophysiology}, doi = {10.5281/zenodo.788569}, url = {https://doi.org/10.5281/zenodo.788569}, month = may, year = {2017}
}
Makin, J. G., O’Doherty, J. E., Cardoso, M. M. B. & Sabes, P. N. (2018). Superior arm-movement decoding from cortex with a new, unsupervised-learning algorithm. J Neural Eng. 15(2): 026010. doi:10.1088/1741-2552/aa9e95 ↩︎
这篇关于公开数据集:灵长类动物多通道感觉运动皮层电生理学的研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







