本文主要是介绍T5论文总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
最近一个项目中用到了Google的T5模型,之前只是有被“文本生成干所有”的理念小小惊艳到,但没有阅读过论文,趁此机会对这篇更像是大规模实验报告的论文进行总结。当然必备基础一定是对Transformer有足够的了解。
《Text-to-Text Transfer Transformer》![]() https://arxiv.org/pdf/1910.10683.pdf
https://arxiv.org/pdf/1910.10683.pdf
这是一篇实验报告而非创新性论文
这篇论文页数有60+,如果埋头读的话很容易在读完后迷茫这篇文章到底是讲了什么,其实这篇论文就是一系列与NLP Transfer Learning相关的方法的实验报告,有可能你会觉得在NLP领域提Transfer Learning还是挺别扭的(反正我对于这个短语第一印象是CV),但实际上这个NLP中的Transfer指的就是现在流行的预训练模型,所以说首先要了解,这是一篇对当下最流行的NLP预训练技术各个环节方法(模型架构、无监督预训练目标等)的对比实验报告。
“文本生成干所有”不是邀功,而是源点
“With this unified approach, we can compare the effectiveness of different transfer learning objectives, unlabeled data sets, and other factors, while exploring the limits of transfer learning for NLP by scaling up models and data sets beyond what has previously been considered.”
虽然口号很霸气,但当你阅读论文时就会发现,其实它并非这篇论文的主要目标,而是:为了能够在实验中比较在各环节方法(哪个训练目标效果最好?哪种mask方式最好?如何fine-tune最好?等等)的效果,需要一个统一的任务,在这统一的任务上对各个方法进行对比实验评判。说白了就是控制变量,连任务都不同的话谈什么环节方法对比?所以先放到同一个任务上来,再在此任务上开展对比实验。
"We systematically study these contributions by taking a reasonable baseline (described in Section 3.1) and altering one aspect of the setup at a time. For example, in Section 3.3 we measure the performance of different unsupervised objectives while keeping the rest of our experimental pipeline fixed."
当然,通过将不同的NLP任务都统一成相同的任务使得模型可以直接用各种任务数据进行统一训练,这看上去似乎确实是一个优点,但是个人认为并不尽然:多任务学习带来提升有两种情况:①多个任务之间的共通关联有益于各任务自身,但这种情形在实际遇到的任务中少之又少;②某个任务数据太少,通过多任务中的其它任务进行“知识”的补充,那么又回到了第①种情况,“知识”的补充需要任务之间具有一定程度的“相关性”。并且,从直觉上讲,统一则需要个体的牺牲,所以一个什么任务都能干的方法比不过在某任务上进行精心优化的方法。
在谈了一大堆对“文本生成干所有”的认识后,就轮到介绍是怎么“干”的部分了,其实就是简单的输入处理(将任务以前缀prefix的方式加入到文本中),下面贴一张论文原图很清晰不赘述了。
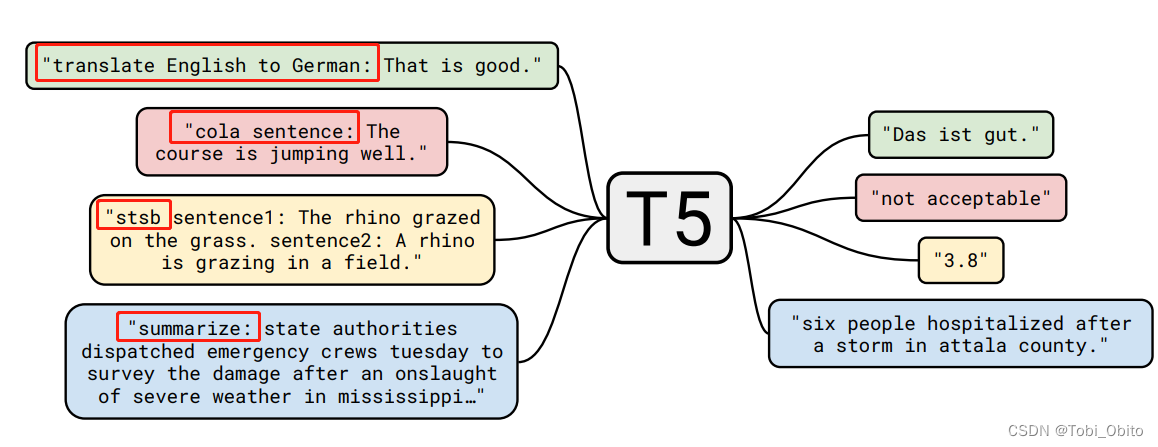
Data & Base Model
在开始实验之前还差model和data两个部分
这篇关于T5论文总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





