本文主要是介绍一文读懂:什么是DataOps可观察性?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:https://datakitchen.io/what-is-dataops-observability/
编译 | June
如果没有 DataOps,以业务需要的所有方式保持数据流动几乎是不可能的。如果没有可观测性,DataOps 就会盲目运行。“可观测性”意味着 DataOps 可以观测数据基础设施、数据流和数据本身。当出现问题时,自动警报会通知 DataOps 或数据工程师,以便他们解决问题——或者至少暂停信任这些不可信数据的人员和程序。
DataOps可观察性是实时监控、测试、警报和分析你的数据状态。它提供了从数据源到客户价值、从任何团队开发环境到生产、跨工具、团队、环境和客户的每个数据旅程的视图,以便立即发现、定位和理解问题。
为什么选择DataOps可观察性?
问题1:许多工具和管道--错误和延迟太多:
在企业范围内看不到100、1000个工具、管道和数据集
无端到端质量控制
难以诊断问题
数据和其他地方的错误会产生干扰,从而限制新的洞察力开发
问题2:数据和分析团队在解决这些问题方面存在摩擦
非常忙:团队已经很忙压力很大了,知道他们没有达到客户的期望。
低变化需求:团队拥有复杂的数据架构和工具(可能包括其他日志记录和可观测性技术)。他们担心已经发生的事情会发生变化。
没有单一管理平台:无法在一个地方查看所有工具、管道、数据集和团队。
团队不知道在哪里或如何检查数据或人工问题。
团队看到了很多指责和愧疚,没有共享的上下文来实时查看和诊断问题。
DataOps可观察性试图解决什么问题?
许多公司陷入了一种“希望和祈祷”的文化中,认为他们的改变和整合不会破坏任何东西。当事情不可避免地出错时,他们就会练习“灭火”。他们等待客户发现问题。他们盲目地相信其提供商能在不改变数据结构的情况下及时提供好数据。他们甚至会中断一个最聪明的人的日常工作,以追踪和修复特定管道中的单个错误。他们不知道其他成千上万个数据管道和任务是否失败了。
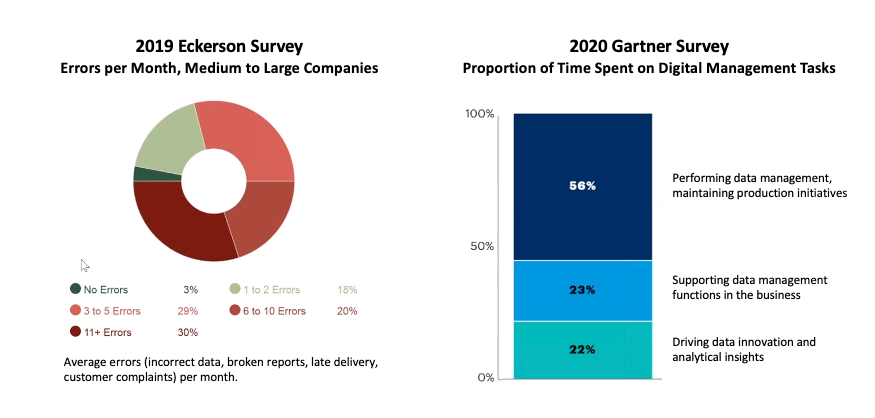
这是一种生产力流失的文化,导致客户对数据失去信任。另一个结果是造成数据团队内部极度沮丧。DataKitchen在2022年对数据工程师进行的一项调查,其统计数据令人震惊:78%的人认为他们需要去看治疗师,同样数量的人也考虑过辞职或转行。由于供应问题,该行业正在经历数据工作人员的短缺,而且由于压力太大,大量人员离开该行业。
团队在从源到价值的整个数据过程中没有可见性,无法对数据、硬件、代码或软件问题进行深入诊断,以发现和分析问题影响。
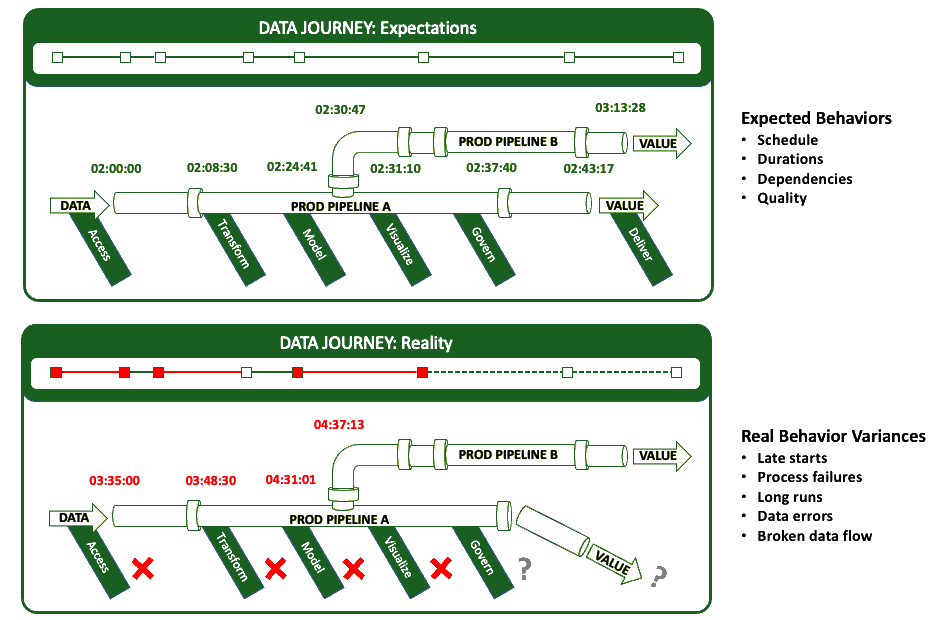
什么是数据之旅?
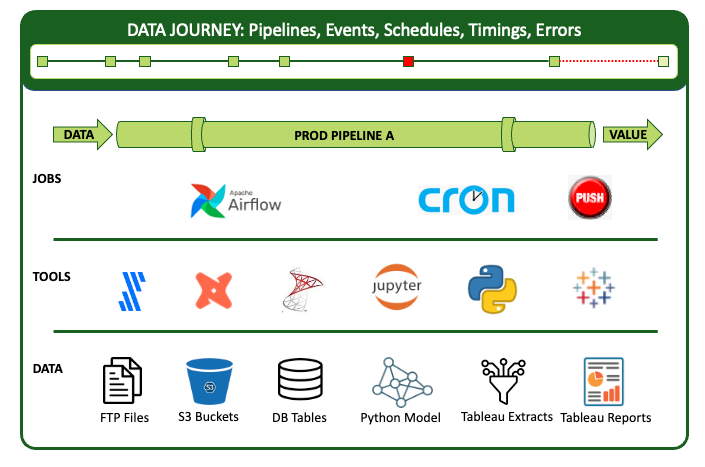
数据之旅是关于观察你所做的事情,而不是改变你现有的数据属性。数据旅程跟踪和监控数据堆栈的所有级别,从数据到工具,从代码到跨所有关键维度的测试。它提供关于开始时间、处理持续时间、测试结果和基础设施事件等指标的实时状态和警报。有了这些信息,你可以知道一切是否都按时无误地运行,并立即识别出没有运行的特定部分。
为什么“现代数据堆栈”如此复杂?
该行业充满了数据、自动化和数据科学/分析工具。但这些工具都不能完全解决这个问题。你必须监控您的整个数据资产以及管道可能成功或失败的所有原因,而不仅仅是服务器、负载测试以及测试单个工具和事务。这是一个每年价值600亿美元的行业,拥有数百家供应商。
https://a16z.com/2020/10/27/blueprints-for-data-infrastructure-lakehouse-storage-data-is-not-the-new-oil-more/
“DataOps可观测性”与“数据沿袭”有何不同?
数据沿袭回答了这样一个问题:“这些数据来自何处,又将流向何处?”它是一种描述组织中的数据资产的方法。它是一种描述,用于帮助数据用户了解数据来自何处,以及使用数据目录了解特定数据表或文件的内容。但是数据沿袭并不能回答其他关键问题。例如,数据学沿袭不能回答以下问题:“我可以信任这个数据吗?”“如果没有,在数据传输过程中发生了什么导致了这个问题?”?"“这些数据是否已使用最新文件更新”?了解你的数据旅程,并构建一个系统来监控这一系列复杂的步骤,这是一种主动的、面向行动的方式,可以改进交付给客户的结果。
DataOps数据旅程可观察性是“运行时沿袭”。这样想:如果你的房子着火了,你就不想去市政厅拿到你家的蓝图,以便更好地了解火灾是如何蔓延的。你需要在每个房间都安装烟雾探测器,这样你就可以迅速得到警报,避免损坏。数据沿袭是房子的蓝图;数据旅程是一组实时向您发送信号的火灾探测器。理想情况下,您运行时间和数据沿袭都需要。
为什么应该关心数据之旅中的错误和瓶颈?
您在数据和基础设施以及团队用来创造价值的工具方面进行了大量投资。你知道这一切都是正确的吗?或者你希望并祈祷源数据更改、代码修复或新的集成不会破坏任何问题?如果出现问题,是否能够高效快速地发现问题,或者团队是否花费数天时间来诊断问题?你是否害怕一个愤怒的客户在你发现问题之前打来的电话或电子邮件?您如何能相信什么都不会出错,而您的客户会继续信任你的交付成果呢?你害怕第一天早上的工作邮件和它可能带来的问题吗?
当前的IT应用程序性能监视器工具还没有做到这一点吗?
要了解数据在技术和数据堆栈上下移动的所有过程,需要一个超越典型应用程序性能监控和IT基础设施监控软件产品的元结构。这些解决方案虽然很有价值,但都产生了滞后的指标。例如,您可能知道磁盘空间已接近极限,但无法确定磁盘上的数据是否正确。您可能知道某个特定的过程已经完成,但看不到它是否按时完成或输出正确。您无法仅通过一些细节来对数据集成或报告进行质量控制。
由于数据错误比资源故障发生得更频繁,因此数据传输为管道作业、工具及其生产的产品提供了重要的附加环境。他们观察并收集信息,然后将其合成一致的视图、警报和分析,以便人们预测、预防和应对问题。
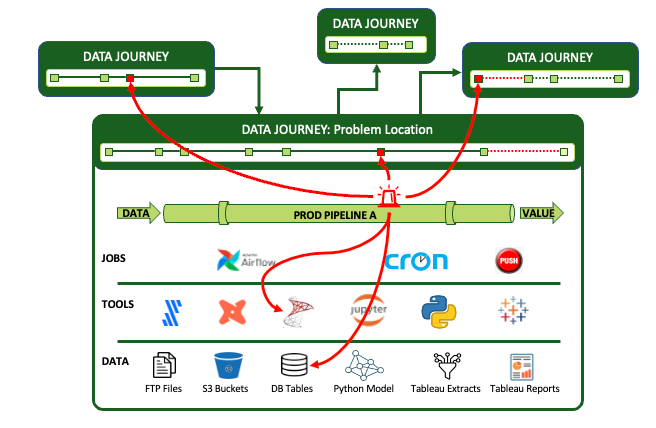
DataOps可观测性解决方案的组成部分是什么?
1.代表完整的数据旅程:能够在工具、数据和基础架构以及复杂的组织边界内深入监控数据旅程中的每一步。
2.生产预期、数据和工具测试和警报:能够设置时间、质量控制和处理步骤顺序规则/预期,并主动推送通知。
3.开发数据和工具测试:验证开发过程中的整个数据过程。使团队成员能够“克服困难”,以提高交付率并降低部署新见解的风险。
4.历史仪表板和根本原因分析:随着时间的推移,存储有关每个数据旅程中发生的情况的数据,以从错误中吸取教训并改进
5.特定于每个角色的用户界面:易于理解,基于角色的UI允许团队中的每个人——IT、经理、数据工程师、科学家、分析师和业务客户,都在同一页上。
6.简单的集成和开放的API:解决方案应包括预构建、快速、简单的集成,开放的API可在不替换现有工具的情况下推动快速集成。
7.监控成本和最终用户使用情况跟踪:能够将特定成本项目(例如,服务器成本)作为数据旅程的一部分。同样,能够监视表和报告的用户使用数据。这些数据可以帮助您判断一个数据旅程的成本是否大于它的收益。
8.加速器和自动化人员:团队希望快速开始了解他们的数据旅程,并创建一组数据测试和预期,以告诉他们哪里出了问题。DataOps可观测性应该能够自动生成一组基本的数据测试和期望值,以便团队能够快速获得价值。
谁关心DataOps的可观测性?
数据和分析团队及其领导(CDO,数据工程/架构/可实施性/科学总监)。第二,开发和支持面向客户的数据和分析系统的小型数据团队。数据团队关心为客户提供没有错误和高变化率。洞察力。最后,任何想要少一些尴尬、麻烦和更多时间工作的团队都会创造出独到的见解。
这与数据质量相比如何?
许多企业对通过其数据工厂流动的数据几乎没有过程控制。“希望得到最好的结果”并不是一个有效的制造策略。您希望在处理过程中尽早发现错误。依靠客户或业务用户来发现错误,将会逐渐削弱人们对分析人员和数据团队的信任。
仅仅关注源数据的质量并不能解决所有的问题。在治理中,人们有时会执行手动的数据质量评估。这些劳动密集型的数据质量评估会定期进行,从而提供特定时间的质量说明。DataOps可观察性侧重于降低错误率,确保持续的测试和数据完整性的改进。DataOps可观察性24×7工作,来验证数据和分析过程的正确性。
我们的源数据状态非常好,所以我们不需要DataOps的可观察性,对吧?
检查数据很重要,但错误也可能源于工作流、端到端工具链或作用于数据的配置/代码中的问题。例如,纠正延迟交付的数据(错过SLA)也可能是一个大问题。DataOps可观察性方法可以鸟瞰数据工厂,并从各个方面攻击错误。
在开发过程中进行了大量的手动QC检查,因此不需要DataOps可观察性?
避免手动测试,手动测试由一个人逐步执行,这会在流程流程中造成瓶颈。手动测试非常昂贵,因为它需要有人创建一个环境并一次运行一个测试。它也很容易出现人为错误。自动化测试是DataOps可观测性的重要支柱。将自动化测试构建到发布和部署工作流中。测试证明,分析代码已准备好用于生产。在分析开发阶段,用于验证代码的大多数测试都与分析一起投入到生产中,以验证和验证数据旅程的操作。
DataOps可观测性与数据可观测性有何不同?
数据可观察性工具可以测试数据库中的数据。您需要将这些信息与数据旅程中的其他关键要素相关联,这需要基本的理解。
现在大家应该清楚的知道DataOps 可观测性对于企业来说有多重要。那么,目前由国内企业大数据平台解决方案提供商智领云自主研发的新一代在线DataOps大数据平台--BDOS Online,就具备完备的 DataOps 能力,其数据可观测、可管理、可发现,正可以观测数据基础设施、数据流和数据本身,从而快速帮助企业更好的运用数据。当然这只是BDOS Online的优势之一,详情大家可以扫描下方二维码并领取试用机会。

免费试用
- FIN -

更多精彩推荐
Gartner:DataOps驱动数据工程最佳实践精华
智领云入选开源GitOps产业联盟生态图景2.0
国家数据局成立,为云原生大数据平台提供新机遇
Kubernetes使用现状,直面数据管理问题和挑战
真正的云原生大数据平台,让Kubernetes又牛了一把
👇点击阅读原文,了解云原生DataOps
这篇关于一文读懂:什么是DataOps可观察性?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






