本文主要是介绍探索未来,开启无限可能:打造智慧应用,亚马逊云科技大语言模型助您一臂之力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 什么是大模型?
- 大模型训练方法
- 亚马逊云科技推出生成式AI新工具 —— aws toolkit
- 使用教程
- 总结
什么是大模型?
近期,生成式大模型是人工智能领域的研究热点。这些生成式大模型,诸如文心一言、文心一格、ChatGPT、Stable Diffusion等等,不仅在自然语言处理领域大放异彩,还在计算机视觉等众多其他领域中展现了卓越的性能。造成如此大变革的关键:以模型的形式存储数据,更理解人类语言。
以往的NLP模型或者CV模型,均是通过判别式的方法对单一任务进行建模,而生成式模型则是通过学习以往数据分布,从而实现对信息的生成与处理。

如果你了解过大模型,那你一定知道亚马逊云科技大语言模型,推出 Amazon Bedrock 服务和 Amazon Titan 大语言模型,以帮助云企业提高效率和创新能力。特别是发布 AI 编码助手 Amazon CodeWhisperer,面向所有个人用户免费开放,不设任何资质或使用时长的限制!我个人是搞Java开发的,一直在用,使用起来非常棒!
「大多数公司都想用上大型语言模型,但真正好用的语言模型需要数十亿美元和多年的时间来训练,人们不想经历这些,」安迪?贾西表示。「因此,他们期待从一个已经非常庞大的基础模型中进行提升,然后能够根据自己的目的对其进行定制。这就是 Bedrock。」
这也是亚马逊特别强大的一处,减轻企业的财力和人力,助力企业大模型的开发和使用。
大模型训练方法
随着深度学习技术的不断发展,大型预训练模型在各个领域取得了显著的成果。这些大模型通过海量的数据和复杂的网络结构,有效地捕捉到了输入与输出之间的关系,从而在诸如图像分类、自然语言处理、语音识别等任务中达到了人类水平甚至超越了人类。然而,大型预训练模型的应用并不仅仅局限于这些特定任务,它们还可以通过适配下游任务,实现更广泛的应用。
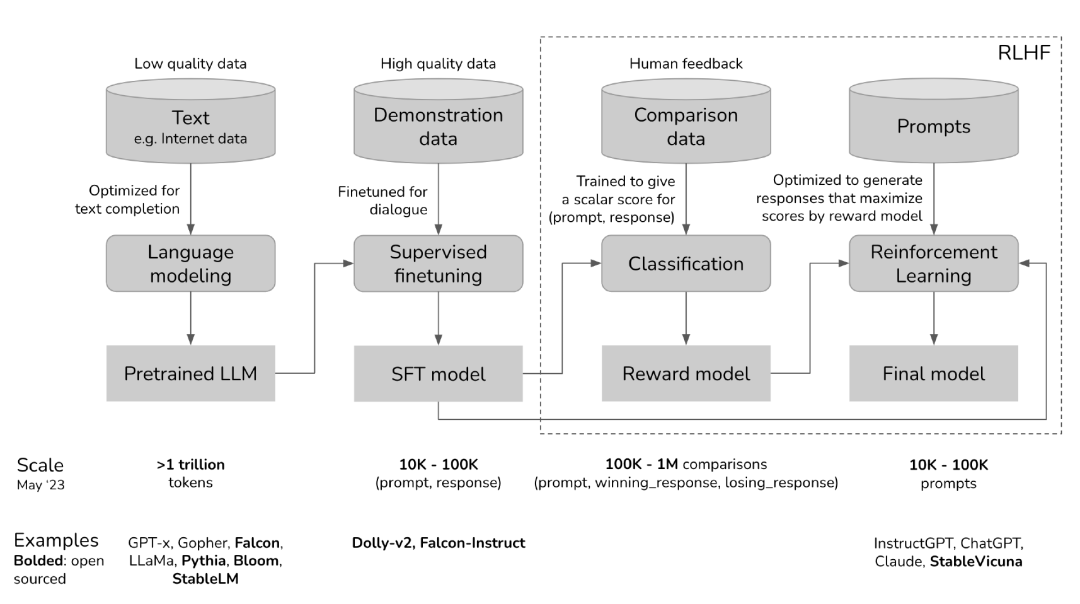
在大模型开发过程中,一些独特的方法和技术也被提出和应用,如预训练(pre-train)、有监督精调(SFT, Supervised Fine Turning)、基于人类反馈的强化学习(RLHF, Reinforcement Learning from Human Feedback)等。这些方法各有特点,有的能够提高模型的泛化能力,有的能够利用大量的无监督数据进行学习,有的则能够将人类的反馈信息融入到模型的训练过程中。
亚马逊云科技推出生成式AI新工具 —— aws toolkit
亚马逊云科技去年宣布推出了 Amazon CodeWhisperer 预览版,这是一款 AI 编程助手,通过内嵌的基础模型,可以根据开发者用自然语言描述的注释和集成开发环境(IDE)中的既有代码实时生成代码建议,从而提升开发者的生产效率。

目前,亚马逊云科技宣布 Amazon CodeWhisperer正式可用,数据显示,与未使用 CodeWhisperer 的参与者相比,使用 CodeWhisperer 的参与者完成任务的速度平均快57%。
aws toolkit
使用教程
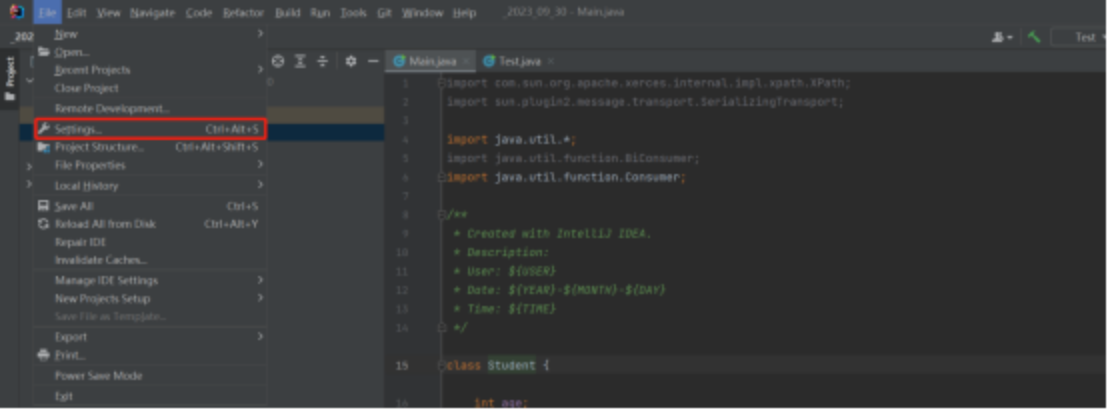
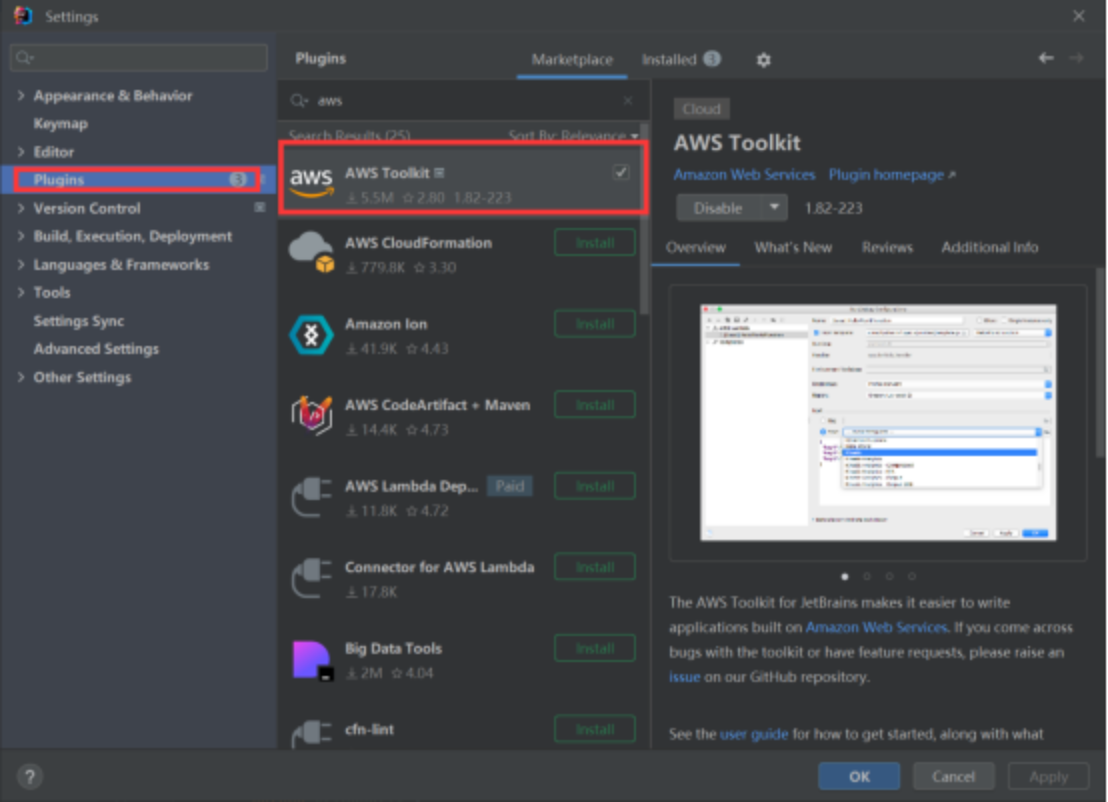
aws toolkit我们这里以IDEA为例,给大家示范一遍
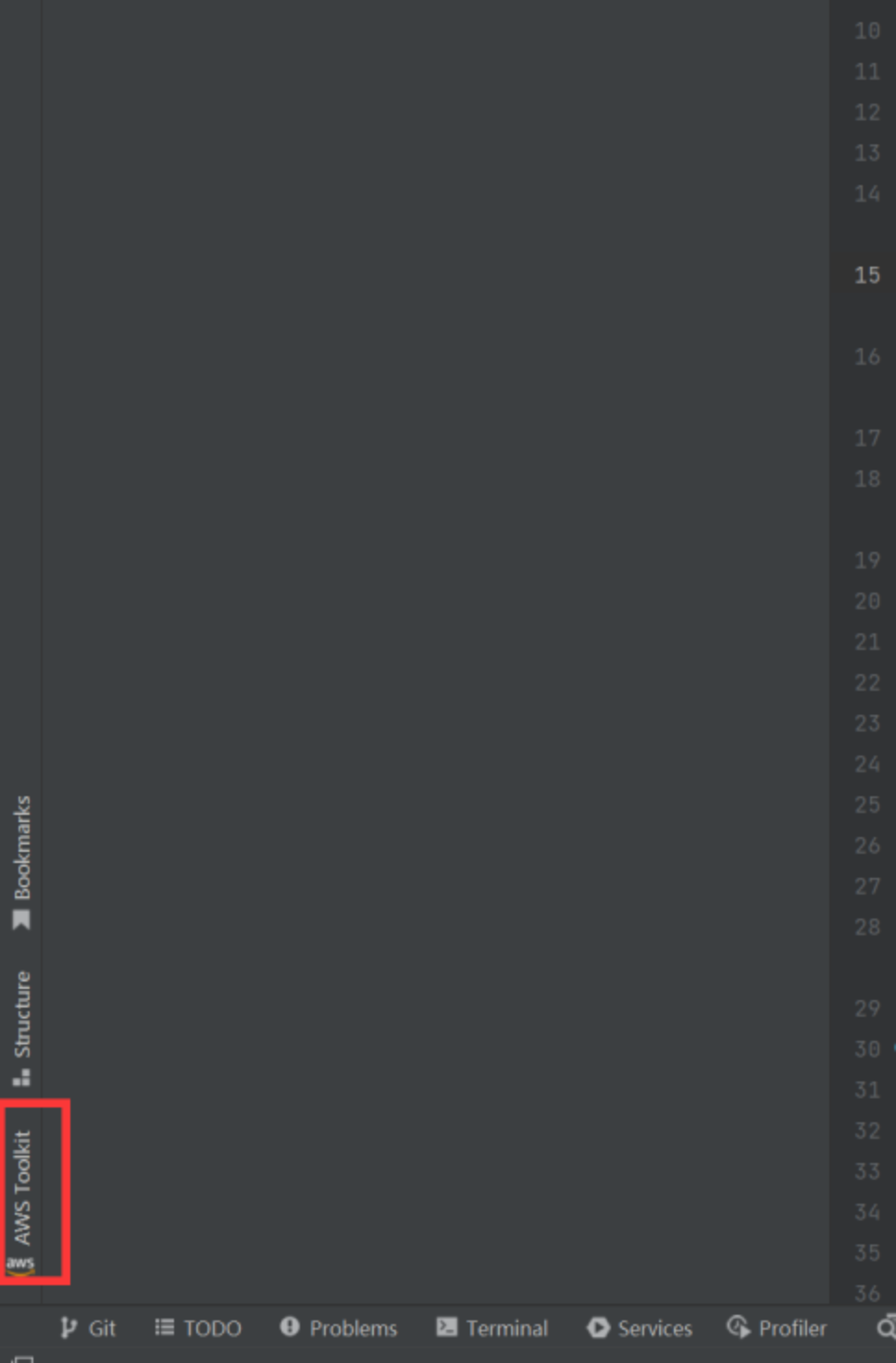
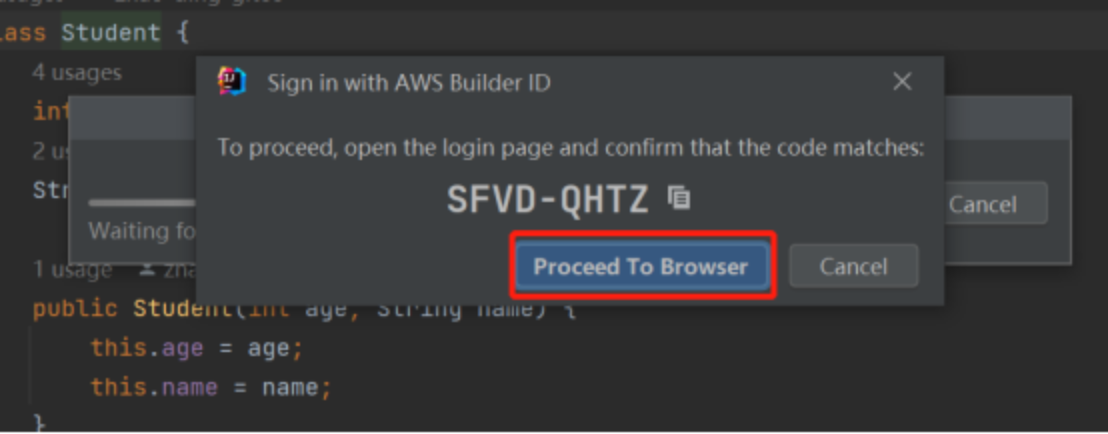
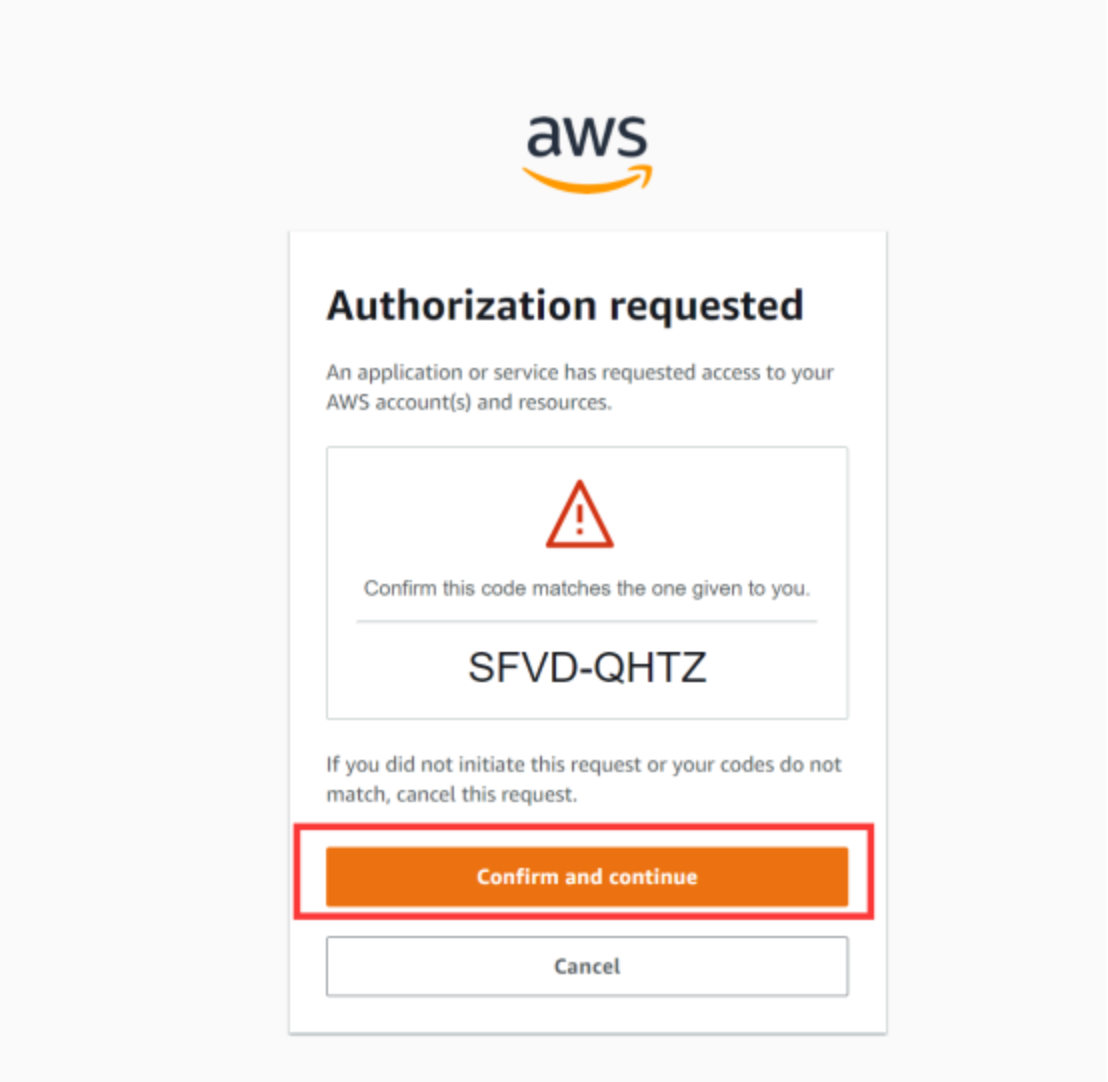
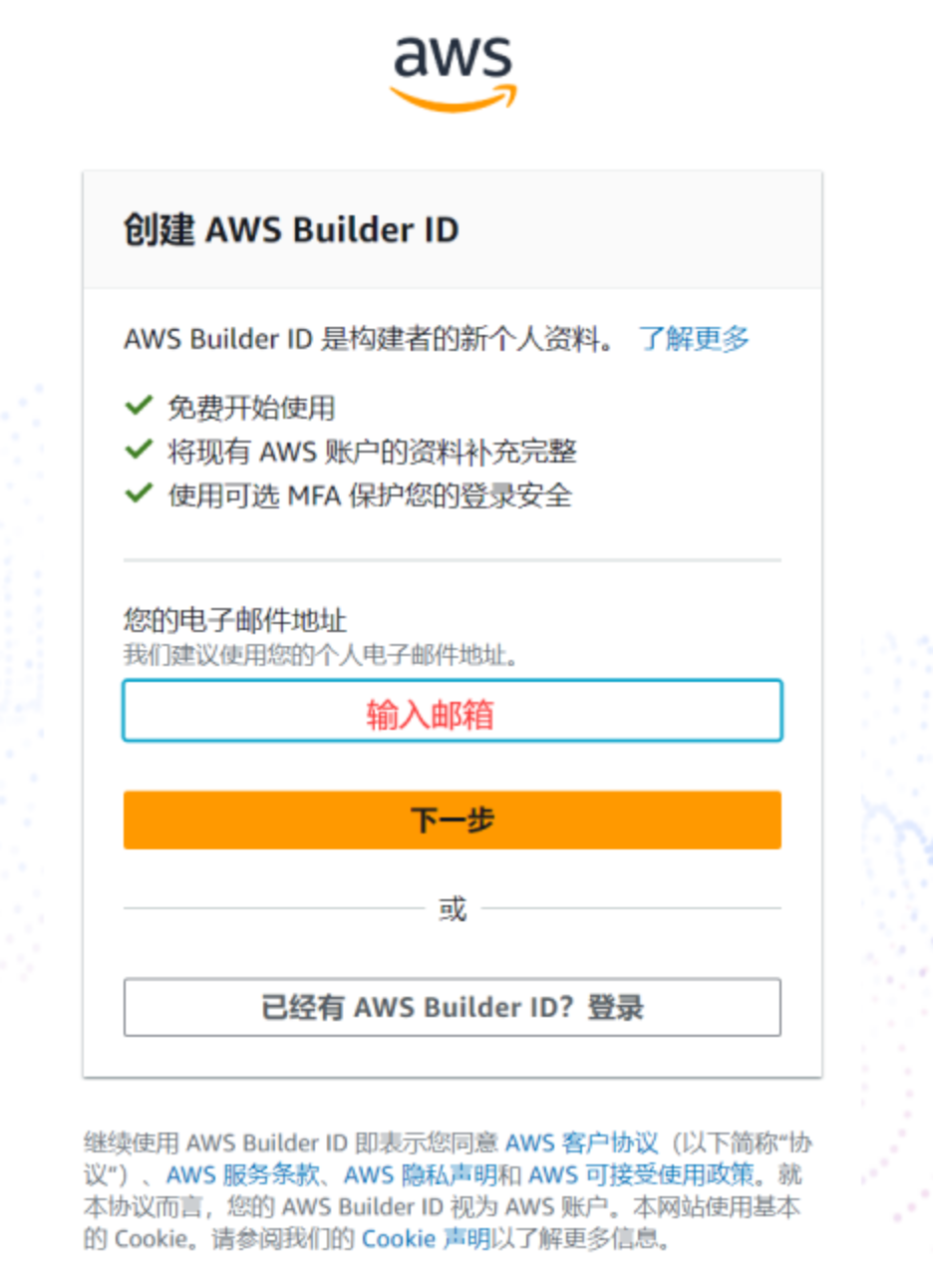
输入验证码后,设置密码
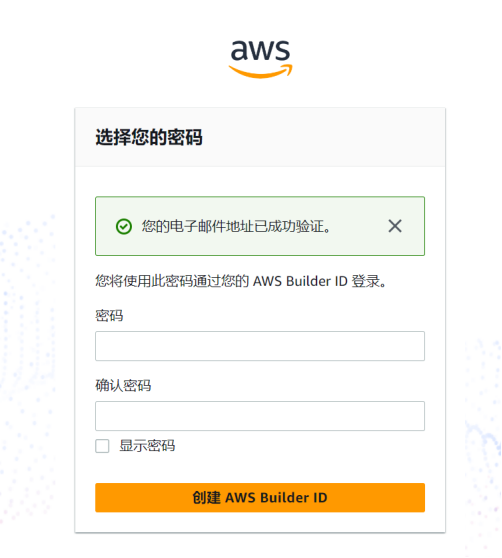
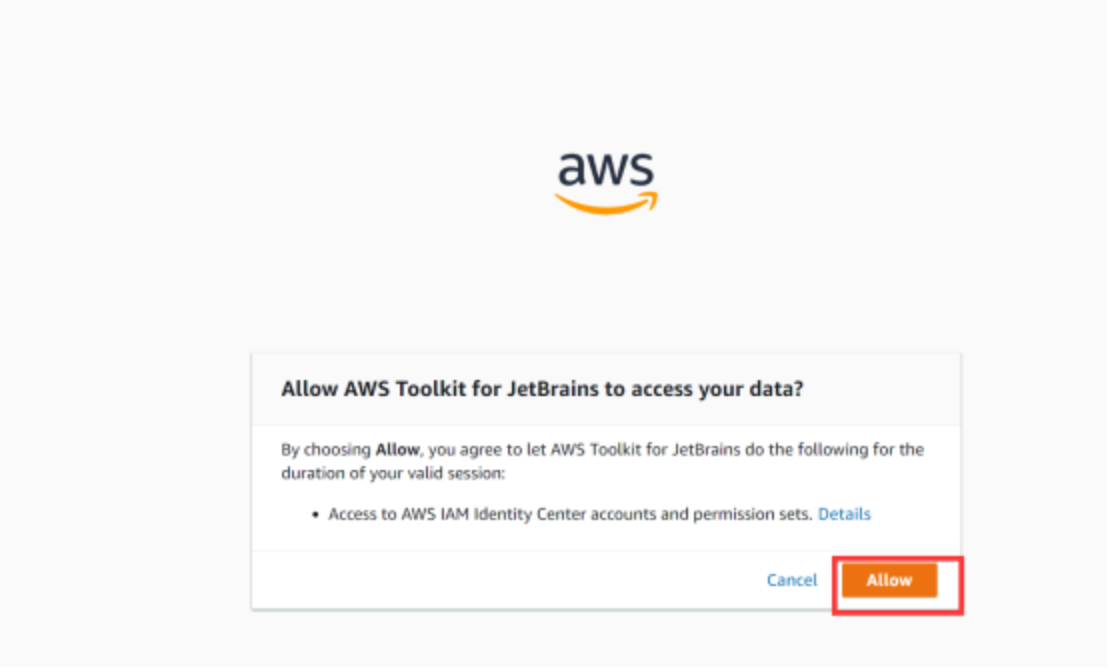
然后就可以正常使用了,大家快去试试吧,体验一下。
总结
从目前亚马逊云科技搭建的“AI 小生态”来看,这些生成式 AI 能力和工具,不再是那些冰冷的性能提升数字,而是卓越性价比,为企业解决问题提供了切实可行的企业技术解决方案。回溯本身,亚马逊云科技之所以能够实现这些突破,源于将每一个客户的难题都视为一个新的探索方向,将“探索精神”和“创新精神”贯彻始终,输出接地气的技术能力和解决方案。不积跬步无以至千里,亚马逊云科技凭借其多年来积累的企业服务经验,深刻理解企业需求,并在实际业务中持续获取洞察,这必定能帮助亚马逊云科技在市场竞争中脱颖而出。
这篇关于探索未来,开启无限可能:打造智慧应用,亚马逊云科技大语言模型助您一臂之力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







