本文主要是介绍杠精的机器学习(四):偏差与方差(橙鹰面试),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 参考资料:周志华的西瓜书《机器学习》、台大李宏毅《机器学习》视频
- 之所以写这篇博客,是因为橙鹰面试官问了我一个关于偏差与方差的问题,感觉自己答的不是很好,所以详细的梳理一下偏差与方差。
- 本文所有的内容都以回归任务为例。
1.关于偏差-方差的面试场景
2018-11-29 9:30开始面试。面试地点,上海虹桥阿里中心。橙鹰面试官的问题大致是这样的:“我看你的比赛经历中,用了很多方案都是集成模型,比如随机森林,XGBoost等等,那么请解释一下为什么集成模型的效果会比较好?”
这个问题真的问得我一脸懵逼,一般来说,大家都是因为集成模型效果很好才用集成模型,这基本算是一种常识了。但是我真的没有想过,为什么它会好。我支支吾吾的拿了随机森林举了个例子,说“随机森林的结果是通过多棵树的表决得到的,可以过滤了一些异常情况”。面试官见我答的不行,又说,“不是有一套偏差-方差理论吗,哪个降低的是方差,哪个降低的偏差”。可能是太紧张了,一时间记不起来了,我磨叽了一会,面试官又说,“方差与偏差不是对应了两条随着训练时间变化的曲线吗?”。于是我又详细解释了方差-偏差分解理论,虽然自己感觉答的牛头不对马嘴,但是面试官好像还挺满意的,一个劲的点头。可能是我自己把问题想的过于复杂了吧,也许,他就是想让我解释一下方差-偏差分解理论。
根据面试的内容,把问题大致拆解为三个部分。1.解释什么是偏差,什么是方差?2.从方差与偏差的角度解释过拟合与欠拟合?3.从方差与偏差解释为什么集成模型效果比较好?
2.什么是偏差(Bias),什么是方差(Variance)
本文所有的内容都以回归任务为例。
首先说一个被很多机器学习资料忽略的小东西,但是如果不说清楚,又会对理解偏差与方差造成障碍。不说废话,通俗地介绍一下Bias和Variance的计算方式,什么都清楚了。假如我有一个很大很大很大很大的数据集 D D D,我将 D D D随机分为N个大小相同的子集:
d 1 , d 2 , … … d n d_1,d_2,……d_n d1,d2,……dn
每个子集数据量是足够多的。然后我分别用这N个子集,训练某个机器学习模型,比如决策树,这样,我就得到了N个决策树模型:
f 1 , f 2 , … … , f n f_1,f_2,……,f_n f1,f2,……,fn
每个子集都对应一个决策树模型。当前,有一个测试样本 x x x,注意只有一个,将 x x x代入利用N个决策树模型便得到了N个预测值:
f 1 ( x ) , f 2 ( x ) , … … , f n ( x ) f_1(x),f_2(x),……,f_n(x) f1(x),f2(x),……,fn(x)
有了这N个预测值之后,就可以算偏差和方差了。计算Bias:先计算平均预测值 f ˉ ( x ) \bar{f}(x) fˉ(x):
f ˉ ( x ) = 1 n ∑ i = 1 n f i ( x ) \bar{f}(x)=\frac{1}{n}\sum_{i=1}^{n}f_i(x) fˉ(x)=n1i=1∑nfi(x)
于是,偏差bias为:
b i a s = f ˉ ( x ) − y bias=\bar{f}(x)-y bias=fˉ(x)−y
其中 y y y表示 x x x的真实标签。其实偏差从字面意思就很容易理解,就是距离真实值偏了多少,差了多少。再计算完偏差之后,我们还想知道这个N个偏差之间波动情况是怎么样的,换句话说,决策树模型是否稳定。又或者说,N个决策树模型对同一个变量 x x x的预测值是不是基本一致的。我们就需要另外一个统计特征,方差(Variance)。方差的计算方法早在小学六年级就学过了: V a r i a n c e = 1 n ∑ i = 1 n ( f i ( x ) − f ˉ ( x ) ) 2 Variance=\frac{1}{n}\sum_{i=1}^{n}(f_i(x)-\bar{f}(x))^2 Variance=n1i=1∑n(fi(x)−fˉ(x))2
也许你会问:仅仅通过一个测试样本 x x x计算得来的Bias和Variance能有说服力吗。确实没有,我仅仅为了更方便、直观地解释Bias和Variance,才只选择一个测试样本。在实做中,为了让数据更有说服力,肯定是需要用到大量测试样本的,在这个时候,只需要计算平均偏差和平均方差就可以了。
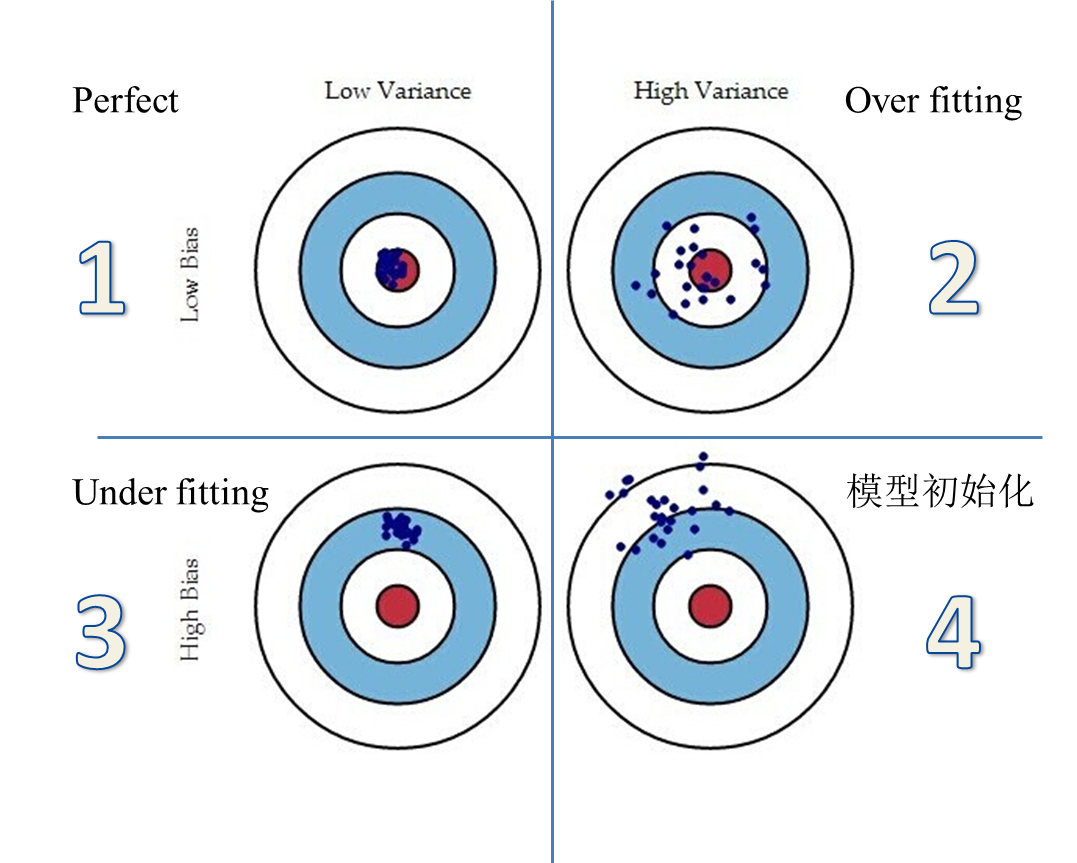
讲完了偏差与方差的概念和计算方式,再来看看图1,就很清楚了,图中,每个点,都是不同模型对同一个测试样本的预测值,红色的靶心是正确值,离靶心越近,说明预测得越准。一个模型最理想的学习结果应该是左上角的第1种情况:Low Bias + Low Variance(即预测得准,又很稳定),最差的是第4种情况,High Bias + High Variance(模型在瞎猜,啥都没学)。但是这种情况也不需要担心,毕竟模型才刚刚开始训练,耐心一点,让它慢慢跑就好了。比较麻烦的是2、3两种情况,2:Little Low Bias+High Variance(过拟合)、3:Little High Bias+Low Variance(欠拟合)。如何合理的解释2、3两种情况,需要用到偏差-方差分解与偏差-方差窘境,这就是本文第3、4部分的内容了。
 |
|---|
| 图1 |
3.偏差-方差分解理论
再介绍完偏差-方差的概念和计算方式之后,就可以讲解偏差-方差分解理论了(主要参考周志华的西瓜书)。抛开模型的可解释性,模型的计算代价,模型的泛化能力是检验模型能否投入实际生产应用的唯一标准。那么,机器学习模型的泛化能力跟什么东西有关,怎么做能够提升泛化能力?大牛们就提出了方差-偏差分解理论。为了让理论推导更加简洁,同时也为了理论更加严谨。在下文中,用期望代替均值,即:
E d [ f d ( x ) ] = f ˉ ( x ) = 1 n ∑ i = 1 n f i ( x ) E_d[f_d(x)]=\bar{f}(x)=\frac{1}{n}\sum_{i=1}^{n}f_i(x) Ed[fd(x)]=fˉ(x)=n1i=1∑nfi(x)
模型的期望泛化误差 E r r o r Error Error可以定义为:
E r r o r = E d [ ( f d ( x ) − y d ) 2 ] Error=E_d[(f_d(x)-y_d)^2] Error=Ed[(fd(x)−yd)2]
其中, y d y_d yd表示样本 x x x在数据集中的标签。此外,在上文中还提到, y y y是样本 x x x的真实标签,因此样本 x x x存在标签标错的可能。所以,定义噪声为: ε 2 = E d [ ( y d − y ) 2 ] \varepsilon^2=E_d[(y_d-y)^2] ε2=Ed[(yd−y)2]
分解步骤如下:
E d [ ( f d ( x ) − y d ) 2 ] = E d [ ( f d ( x ) − f ˉ ( x ) + f ˉ ( x ) − y d ) 2 ] E_d[(f_d(x)-y_d)^2]=E_d[(f_d(x)-\bar f(x)+\bar f(x)-y_d)^2] Ed[(fd(x)−yd)2]=Ed[(fd(x)−fˉ(x)+fˉ(x)−yd)2]
= E d [ ( f d ( x ) − f ˉ ( x ) ) 2 ] + E d [ ( f ˉ ( x ) − y d ) 2 ] + E d [ 2 f d ( x ) − f ˉ ( x ) ) ∗ ( f ˉ ( x ) − y d ) ] =E_d[(f_d(x)-\bar f(x))^2]+E_d[(\bar f(x)-y_d)^2]+E_d[2f_d(x)-\bar f(x))*(\bar f(x)-y_d)] =Ed[(fd(x)−fˉ(x))2]+Ed[(fˉ(x)−yd)2]+Ed[2fd(x)−fˉ(x))∗(fˉ(x)−yd)]
∵ E d [ 2 ( f d ( x ) − f ˉ ( x ) ) ∗ ( f ˉ ( x ) − y d ) ] = 0 , 文 末 附 录 有 推 导 \because E_d[2(f_d(x)-\bar f(x))*(\bar f(x)-y_d)]=0,文末附录有推导 ∵Ed[2(fd(x)−fˉ(x))∗(fˉ(x)−yd)]=0,文末附录有推导
∴ = E d [ ( f d ( x ) − f ˉ ( x ) ) 2 ] + E d [ ( f ˉ ( x ) − y d ) 2 ] \therefore =E_d[(f_d(x)-\bar f(x))^2]+E_d[(\bar f(x)-y_d)^2] ∴=Ed[(fd(x)−fˉ(x))2]+Ed[(fˉ(x)−yd)2]
= E d [ ( f d ( x ) − f ˉ ( x ) ) 2 ] + E d [ ( f ˉ ( x ) − y + y − y d ) 2 ] =E_d[(f_d(x)-\bar f(x))^2]+E_d[(\bar f(x)-y+y-y_d)^2] =Ed[(fd(x)−fˉ(x))2]+Ed[(fˉ(x)−y+y−yd)2]
= E d [ ( f d ( x ) − f ˉ ( x ) ) 2 ] + E d [ ( f ˉ ( x ) − y ) 2 ] + E d [ ( y − y d ) 2 ] + 2 E d [ ( f ˉ ( x ) − y ) ( y − y d ) ] =E_d[(f_d(x)-\bar f(x))^2]+E_d[(\bar f(x)-y)^2]+E_d[(y-y_d)^2]+2E_d[(\bar f(x)-y)(y-y_d)] =Ed[(fd(x)−fˉ(x))2]+Ed[(fˉ(x)−y)2]+Ed[(y−yd)2]+2Ed[(fˉ(x)−y)(y−yd)]
在该理论中,假定噪声期望为 0 0 0,即 E d [ ( y d − y ) ] = 0 E_d[(y_d-y)]=0 Ed[(yd−y)]=0(对于这个假设,我依然有点疑问,文末附录讨论)。最终可得:
E r r o r = v a r ( x ) + b i a s 2 ( x ) + ε 2 Error=var(x)+bias^2(x)+\varepsilon^2 Error=var(x)+bias2(x)+ε2
也就是,泛化误差可以分解为偏差、方差与噪声之和。偏差度量了学习算法的期望预期与真实结果的偏离程度,即刻画了算法本省的拟合能力;方差度量了同样大小训练集的变动所导致学习性能的变化,即刻画了数据扰动所造成的影响。噪声刻画了学习任务本身的难度,如果噪声很大,即便 b i a s 2 ( x ) , v a r ( x ) bias^2(x),var(x) bias2(x),var(x)非常小,泛化误差 E r r o r Error Error依然会很大。偏差-方差分解理论说明,泛化性能是由模型的学习能力,数据的充分性以及学习任务本身的难度所共同决定的。给定学习任务,为了取得更好的泛化性能,则需使偏差较小(能够充分拟合数据),并使方差较小(数据扰动产生的影响小)。再解释一下,数据的充分性指的是什么?数据的充分性指数据量足够大,而且多样性足够丰富,能够刻画出任务本身的各种情况甚至极端情况,如果数据的充分性不够,那么模型只能片面地学习到数据集的特性,而不是数据集的共性,会造成较大的方差。举一个最简单的例子,性别分类任务,有两个数据集,一个包含大量的男性数据,一个包含大量的女性特征,显然,数据是不够充分的,那么训练出的模型必然只能片面地学习到男性的特征或者女性的特征,在实际预测的时候,会有很大的方差。
4.偏差-方差之间的关系
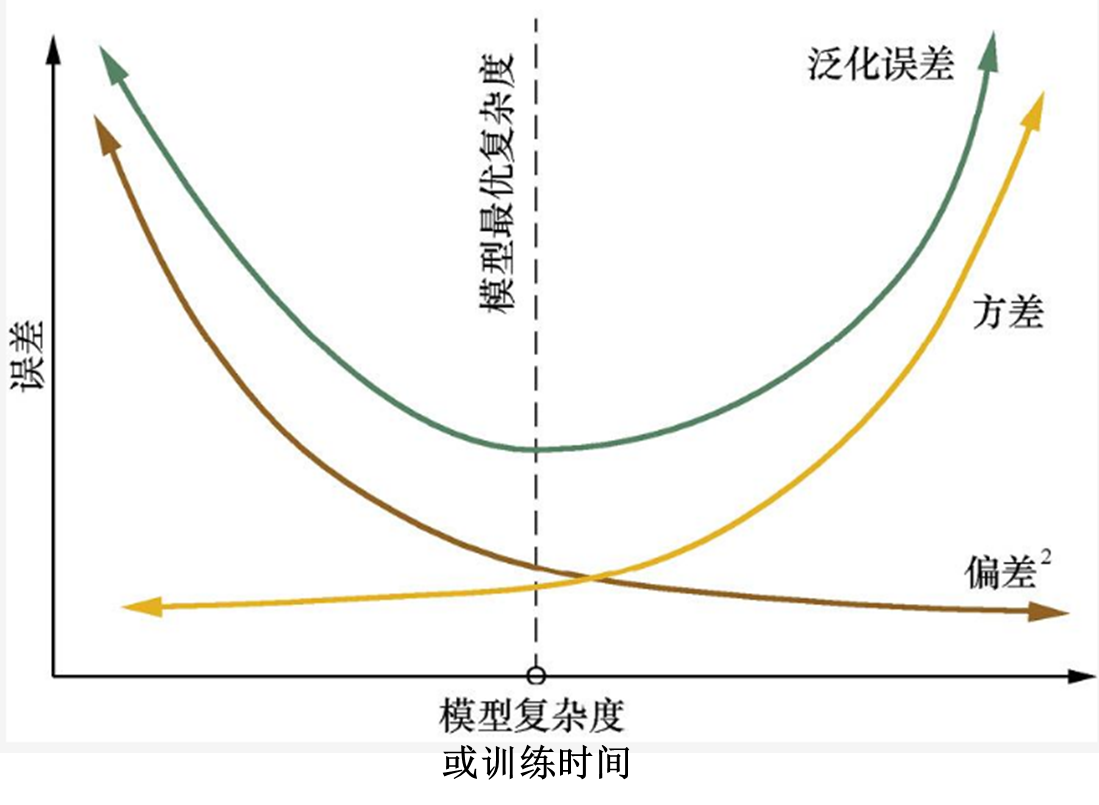
一般而言,偏差与方差是冲突的。这被称为偏差-方差窘境。如图2所示:
 |
|---|
| 图2. |
对于图2,相信大家在很多地方都看到过,图2主要有两个版本,一个版本X轴表示训练程度(训练时间),另一个版本X轴表示模型复杂度。其实这两者是等价的,因为模型复杂度会随着训练的进行而变高。举几个例子说明,比如GBDT,训练时间越长,树的数量越多,对应复杂度变的越高。比如决策树,训练时间越长,树会越深,对应复杂度变得越高。再比如线性回归,训练时间越长,曲线会变得非常扭曲,对应复杂度变得越高。
既然横坐标有两种意思,那么这幅图的含义自然有两种解释。第一种,从训练时间的角度解释:给定学习任务,假定我们能控制学习算法的训练程度(训练时间),则在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著的变化,若训练数据自身的,非全局特性被学习器学到了,则将发生过拟合。
第二种,从模型复杂度的角度解释:对于给定的学习任务和训练数据集,我们需要对模型的复杂度做合理的假设。如果模型复杂度过低,虽然方差很小,但是偏差会很高(如图1(3),under fitting);如果模型复杂度过高,虽然偏差降低了,但是方差会很高(如图1(2),over fitting)。所以需要综合考虑偏差和方差选择合适复杂度的模型进行训练。
5.用方差-偏差解释为什么集成模型效果比较好
终于写到最后一部分内容了,面试中被经常问到的两个集成学习模型就是Boosting和Bagging。为什么它俩的泛化性能会比其他模型要好呢,简单来说,Boosting能够提高弱分类器性能的原因是降低了偏差,Bagging能够提高弱分类器性能的原因是降低了方差。
首先Boosting,根据Boosting的训练过程,在训练好一个弱分类器之后,需要计算弱分类器的错误或者残差,作为下一个分类器的拟合目标。这个过程本身就是在不断减小的损失函数,来使模型不断逼近“靶心”,使模型偏差不断降低。但Boosting的过程并不会显著降低方差,这是因为Boosting的训练过程使得各弱分类器之间是强相关的,缺乏独立性,所以并不会对降低方差有作用。
再看Bagging,Bagging是Bootstrap Aggregating的简称,就是通过再抽样获得N个样本集,然后在每个样本集训练出来的模型取平均。理论上,这个N个样本集是独立不相关的(实做中,不太可能,子集都是从有限的父集中抽样出来的,肯定有一定的相关性),那么N个模型也是独立不相关的,再对它们的预测结果取平均,方差是原来单个模型的1/N。这个描述不严谨,但原来已经讲的很清楚了。为了使模型尽可能独立,诸多Bagging的方法也做了不同的改进。比如在随机森林中,引入了特征随机性。另外要注意的是,既然Bagging降的是方差,所以只有对样本分布敏感的基学习器,Bagging才能发挥它的作用,别什么模型都去Bagging一下,费时还不讨好。
最后,说下自己的感想,我觉得用方差与偏差来就是集成学习的效果不是太严谨,只能说,非常粗略的解释了一下。大牛们也发表在这方面发表了很多论文专门去解释为什么Boosting不容易过拟合,这个我也没怎么了解过,所以就不写了,想了解更多的话,可以看看周志华的讲座Boosting 25周年。方差与偏差在面试的时候还是很重要的,经常会被问到,看官姥爷一定要注意一下。
6.附录
1.公式推导
E d [ 2 ( f d ( x ) − f ˉ ( x ) ) ∗ ( f ˉ ( x ) − y d ) ] E_d[2(f_d(x)-\bar f(x))*(\bar f(x)-y_d)] Ed[2(fd(x)−fˉ(x))∗(fˉ(x)−yd)]
= 2 E d [ f d ( x ) ∗ f ˉ ( x ) − f d ( x ) ∗ y d − f ˉ ( x ) 2 + f ˉ ( x ) ∗ y d ] =2E_d[f_d(x)*\bar f(x)-f_d(x)*y_d-\bar f(x)^2+\bar f(x)*y_d] =2Ed[fd(x)∗fˉ(x)−fd(x)∗yd−fˉ(x)2+fˉ(x)∗yd]
∵ f ˉ ( x ) 是 期 望 , 是 一 个 常 数 , y d 是 标 签 , 也 是 一 个 常 数 。 \because \bar f(x)是期望,是一个常数,y_d是标签,也是一个常数。 ∵fˉ(x)是期望,是一个常数,yd是标签,也是一个常数。
= 2 f ˉ ( x ) E d [ f d ( x ) ] − 2 E d [ f d ( x ) ∗ y d ] − 2 E d [ f ˉ ( x ) 2 ] + 2 E d [ f ˉ ( x ) ∗ y d ] =2\bar f(x)E_d[f_d(x)]-2E_d[f_d(x)*y_d]-2E_d[\bar f(x)^2]+2E_d[\bar f(x)*y_d] =2fˉ(x)Ed[fd(x)]−2Ed[fd(x)∗yd]−2Ed[fˉ(x)2]+2Ed[fˉ(x)∗yd]
= 2 f ˉ ( x ) 2 − 2 y d ∗ f ˉ ( x ) − 2 f ˉ ( x ) 2 + 2 y d ∗ f ˉ ( x ) = 0 =2\bar f(x)^2-2y_d*\bar f(x)-2\bar f(x)^2+2y_d*\bar f(x)=0 =2fˉ(x)2−2yd∗fˉ(x)−2fˉ(x)2+2yd∗fˉ(x)=0
2.疑问点讨论
在3.偏差-方差分解理论中写到 y d y_d yd表示样本 x x x在数据集中的标签,我对这句话不是太理解, x x x是给定的测试样本,那么的 y d y_d yd应该是一个定值, y y y是真实标签,只是我们不知道,但也是个定值。既然 y d , y y_d,y yd,y都是定值,那 E d [ ( y d − y ) ] = y d − y E_d[(y_d-y)]=y_d-y Ed[(yd−y)]=yd−y。如果假定噪声期望为 0 0 0,即 E d [ ( y d − y ) ] = 0 E_d[(y_d-y)]=0 Ed[(yd−y)]=0,可以得出结论 y d − y = 0 y_d-y=0 yd−y=0,说明标签没有标错。那么噪声 ε 2 = E d [ ( y d − y ) 2 ] = 0 \varepsilon^2=E_d[(y_d-y)^2]=0 ε2=Ed[(yd−y)2]=0。所以,最后 E r r o r Error Error应该为:
E r r o r = v a r ( x ) + b i a s 2 ( x ) Error=var(x)+bias^2(x) Error=var(x)+bias2(x)
而不是
E r r o r = v a r ( x ) + b i a s 2 ( x ) + ε 2 Error=var(x)+bias^2(x)+\varepsilon^2 Error=var(x)+bias2(x)+ε2
我认为,合理的解释是, y d y_d yd不是一个定值,是随着数据集在变的,假如猫狗分类任务中,在子集 d 1 d_1 d1中 y d y_d yd是狗,但是在子集 d 2 d_2 d2中 y d y_d yd是猫。但说, y d y_d yd就是 y d y_d yd,怎么可能会随着数据集的改变而改变呢?怎么想都想不明白,烦!
这篇关于杠精的机器学习(四):偏差与方差(橙鹰面试)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







