本文主要是介绍NLP领域的突破催生大模型范式的形成与发展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当前的大模型领域的发展,只是范式转变的开始,基础大模型才刚刚开始改变人工智能系统在世界上的构建和部署方式。
1、大模型范式
1.1 传统思路(2019年以前)
NLP领域历来专注于为具有挑战性的语言任务定义和设计系统,其愿景是擅长这些任务的模型将为下游应用程序带来胜任的语言系统。NLP任务包括针对整个句子或文档的分类任务(例如,情感分类,如预测电影评论是正面的还是负面的),序列标记任务,其中我们对句子或文档中的每个单词或短语进行分类(例如,预测每个词是动词还是名词,或者哪个词的跨度指的是人还是组织),跨度关系分类,(例如,关系提取或解析,如人和位置是否通过“当前居住地”关系链接,或动词和名词是否通过“主语-动词”关系链接)和生成任务,产生条件化的新文本强烈地依赖于输入(例如,生成文本的翻译或摘要,识别或生成语音,或在对话中做出响应)。在过去,NLP任务有不同的研究社区,开发特定于任务的架构,通常基于不同模型的管道,每个模型执行语言子任务,如标记分割,句法分析或共指消解。
1.2 2019年的突破
基础模型来自于NLP领域的发展,并迅速抢占了其他诸多领域的注意力。分水岭是2019年,一石激起千层浪!在2019年之前,使用语言模型的自监督学习基本上是NLP的一个子领域,它与NLP的其他发展并行。在2019年之后,使用语言模型的自监督学习越来越成为NLP的基础,因为使用BERT已经成为常态。接受单一模型可以用于如此广泛的任务,标志着基础模型时代的开始。具体来说,自我监督学习的一波发展- BERT 、 GPT-2 ,RoBERTA ,T5,BART -迅速跟进,采用Transformer架构,结合更强大的句子深度双向编码器,并扩展到更大的模型和数据集。
基础大模型范式的兴起已经开始在口语和书面语中发挥类似的作用。现代自动语音识别(ASR)模型,如wav2vec 2.0,仅在语音音频的大型数据集上进行训练,然后在音频上进行调整,并与ASR任务相关联[Baevski et al. 2020]。由于基础模型范式带来的变化,NLP研究和实践的重点已经从为不同任务定制架构转移到探索如何最好地利用基础模型。对适应方法的研究已经蓬勃发展,基础模型的惊人成功也导致研究兴趣转向分析和理解基础模型。基础模型所展示的成功生成也导致了对语言生成任务(如摘要和对话生成)的研究的蓬勃发展。
1.3 大模型范式的形成(2019年以后)
大模型+微调 :
执行每个任务的主要现代方法是使用单个基础大模型,并使用相对少量的特定于每个任务的注释数据(情感分类,命名实体标记,翻译,摘要)对其进行稍微调整,以创建适应模型。事实证明,这是一种非常成功的方法:对于上面描述的绝大多数任务,稍微适应任务的基础模型大大优于以前的模型或专门为执行该任务而构建的模型管道。
标注的力量:
万物数字化、语言标注万物(人类智能综合的缩影,表现形式,语言文字,形态:论文、书籍、网络资料、文章、话语、视频等等一切形态)
2、 大模型范式在研究界的发展
1)研究界的同质化。例如,类似的基于变换器的序列建模方法(核心共性挑战)现在应用于文本[Devlin et al. 2019;拉德福et al. 2019; Raffel et al. 2019],图像[Dosovitskiy et al. 2020; Chen et al. 2020 d]、语音[Liu et al. 2020 d]、表格数据[Yin et al. 2020]、蛋白质序列[Rives et al. 2021]、有机分子[Rothchild et al. 2021]、和强化学习[Chen et al. 2021 b; Janner et al. 2021]。这些例子指出了一个可能的未来,我们有一套统一的工具来开发各种模式的基础模型[Tamkin et al. 2021 b]。
2)研究社区之间的实际模型以多模态模型的形式同质化-例如,基于语言和视觉数据训练的基础模型[Luo et al. 2020; Kim et al. 2021 a; Cho et al. 2021; Ramesh et al. 2021;拉德福et al. 2021]。数据在某些领域自然是多模态的,例如,医疗图像、结构化数据、医疗保健中的临床文本(医疗保健)。因此,多模态基础模型是融合关于一个领域的所有相关信息的自然方式,并适应也跨越多个模式的任务。基金会的模式也导致了规模的惊人的出现。例如,GPT-3 [Brown et al. 2020],与GPT-2的15亿个参数相比,有1750亿个参数,允许上下文学习,其中语言模型可以通过简单地向下游任务提供提示(任务的自然语言描述)来适应下游任务,这是一种既没有专门训练也没有预期出现的新兴属性。
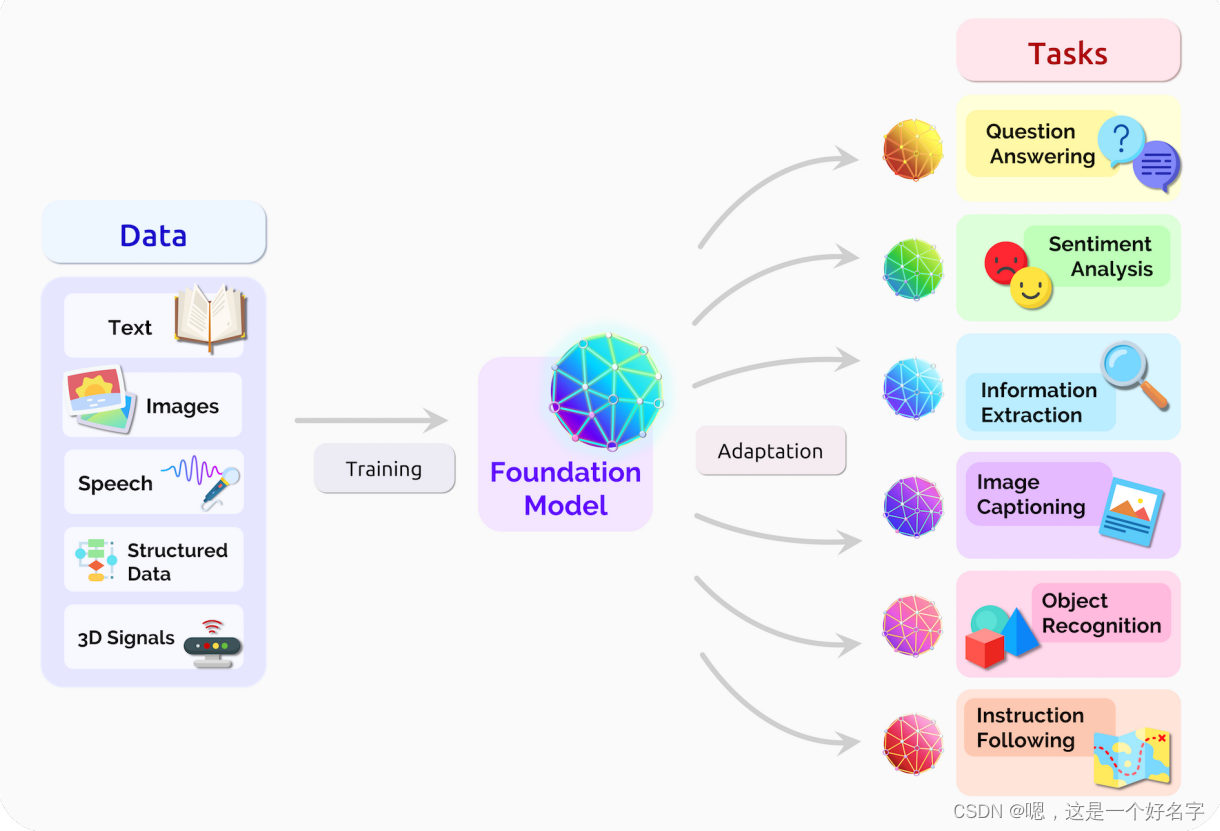
3、大模型范式的未来
有巨大的经济激励来推动基础大模型的能力和规模,因此我们预计未来几年将取得稳步的技术进步。但是,一项主要依赖于紧急行为的技术是否适合广泛部署到人们身上还不清楚。很明显,我们需要谨慎,现在是建立专业规范的时候了,这将使负责任的研究和部署基础模型成为可能。学术界和工业界需要在这方面进行合作:工业界最终会就如何部署基础模型做出具体决定,但我们也应该依靠学术界,因为学术界的学科多样性和围绕知识生产和社会效益的非商业激励措施,为技术和道德基础的基础模型的开发和部署提供独特的指导。

这篇关于NLP领域的突破催生大模型范式的形成与发展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









