本文主要是介绍大语言模型比武,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今年随着 ChatGPT 的流行,并在各个领域有一定程度生产级别的应用。国内外也掀起了一股大语言模型浪潮,各大厂商都推出了自己的大语言模型,阿里推出了 通义千问,腾讯推出了 Hunyuan,亚马逊云推出了 Titan,大语言模型的战场由此开启,争当大语言模型浪潮的弄潮儿。光说不练假把式,咱们今天开启一场大语言模型的比武,各家大语言模型拉出来溜溜。
既然是比武,总得有一些规则,同台竞技,那就是各个维度的比拼,各方要把自己多年压箱底的活都掏出来,才能分个高下。大语言模型比较,各家发布时,都有一些主要关注的指标。不仅是对于用户选用,还是内部评估产品质量,开发周期都是不可或缺的。下面几个主要指标我们需要重点考虑一下。
性能和准确性
性能和准确性是用户最关心的指标,没有之一。牛头不对马嘴的回答会让用户失去继续使用的信心,通常会采用一些基准测试,包括更复杂场景和任务中的表现来评估模型理解能力。
训练数据的量级和多样性
就目前来看,训练模型的数据量级和多样性,和模型的性能成正相关。一般包含更多样化的场景文本,语义语法内容结构,模型的准确性表现会更加优异。
通用性和泛化的能力
如果一个机器人只会炒菜,这当然没有问题,它会成为我们厨房的优秀小帮手。但是,如果它处理更加多元的工作,这会让用户印象深刻。正如大语言模型一样,如果它只能聚焦于客服领域,虽然它很好,但是不够好。
稳健性和健壮性
当大语言模型已经达到可接受的性能和准确性后,我们会很在意服务的稳定性。OpenAI 前几个月就发生过服务崩掉的情况,影响数百万的用户。
资源利用率和收费标准
我们知道很多科技产品已经实现从 0 到 1,但是苦苦挣扎与 1 到 100 的过程,核心问题就是成本问题,而成本又集中体现在资源的利用率上,然后决定了对外收费标准设置到用户能接受的程度上,来能实现真正的商业化。
可观测性和透明度
正如编程一样,我门需要知道大模型整个生成和输出的过程,这样才能不断改进模型,改进产品,形成良性循环。
公正性和伦理考量
这一点往往会被很多人忽视了,但是这是相当重要的一点。如果用户在进行一些危害社会,违反伦理道德的事情,我们应该需要通过某种方式去劝解用户的行为。例如青少年如果在大模型中查询自杀相关的话题,应该要进行及时的引导和善意的劝诫,技术是用来造福和改善人类生活的。
在我相继体验了阿里,腾讯还有亚马逊的产品后,有如下的分析,可以给大家一定程度的参考。
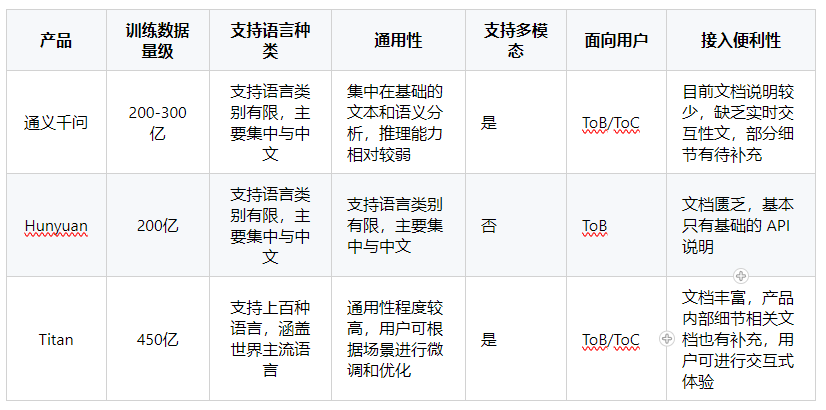
截止到目前,我们可以看到,整体上来说亚马逊的 Titan 是上述几个大语言模型中整体表现最优异的。亚马逊的数据量级与其他两家厂商有明显的优势;如果是需要国际化的产品,语言支持达上百种,对于国际市场有相当大的优势;多模态的支持,哪怕是面向个人用户,也有很不错的支持;交互式文档 Bedrock 的采用,产品接入上也能减少开发者的心智负担。当然了,得益于亚马逊这些年积累下来强大的 AI 实力,CodeWhisperer,Rekognition 等产品一路以来的改进和优化,才能让目前 Titan 这款产品表现优异。
这篇关于大语言模型比武的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







