本文主要是介绍RabbitMQ Deep Dive (by quqi99),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:张华 发表于:2015-06-03
版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明
( http://blog.csdn.net/quqi99 )
AMQP概念
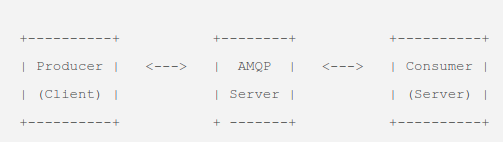
AMPQ在RPC的基础上引入了中间件机制来解偶client与server来支持同步与异步调用。
通过消息机制,可以实现数据传输,非阻塞型操作,推送通知,发布/订阅,异步处理,work队列。
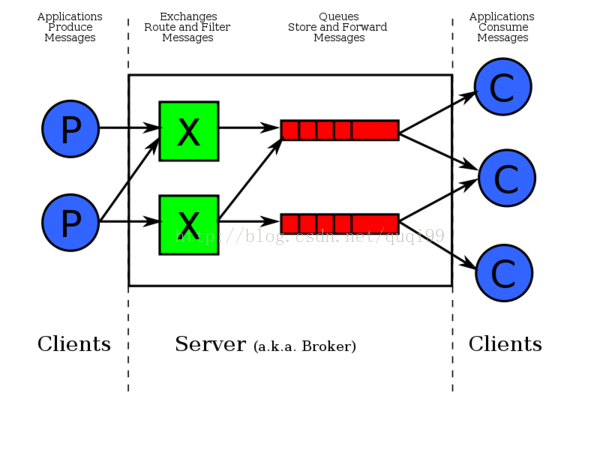
AMQP当中有四个概念非常重要:虚拟主机(virtual host),交换机(exchange),队列(queue)和绑定(binding)。
- virutal host相当于namespace,用于不同tenant之间的exchange, queue, binding的隔离。
- Queue队列, 每个消息都会被投入到一个或多个队列。消息就一直在里面,直到有客户端(也就是消费者,Consumer)连接到这个队列并且将其取走为止。队列是由消费者(Consumer)通过程序建立的,不是通过配置文件或者命令行工具。
- Binding绑定, 它的作用就是把exchange和queue按照路由规则绑定起来。
- Routing_Key路由关键字:exchange根据这个关键字进行消息投递。
- Channele消息通道:在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
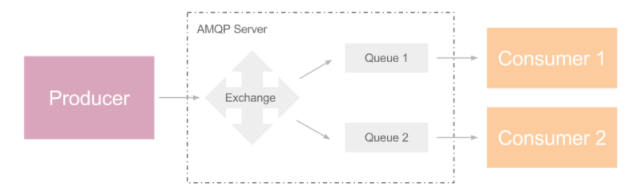
- Exchange交换机,对消息进行路由,当收到Publisher传递给它的消息后,Excahnge会根据路由键routing_key决定将消息加入到哪些消息队列中。
消息的类型:
- Direct Exchange – 处理路由键。需要将一个队列绑定到交换机上,要求该消息与一个特定的路由键完全匹配。一对一交换类型。
- Topic Exchange – 将路由键和某模式进行匹配。此时队列需要绑定要一个模式上。符号“#”匹配一个或多个词,符号“*”匹配不多不少一个词。一对多主题多播交换类型。
- Fanout Exchange – 不处理路由键。你只需要简单的将队列绑定到交换机上。一个发送到交换机的消息都会被转发到与该交换机绑定的所有队列上。一对多广播交换类型。
AMQP 支持三种调用:
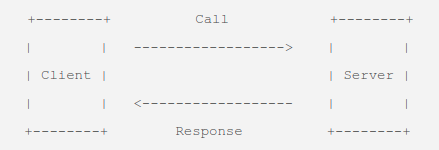
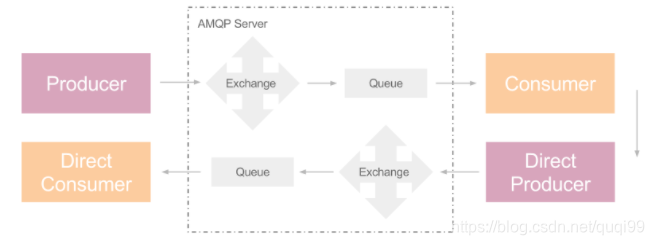
Call: 同步调用,但过程稍微复杂,producer 发送消息后立刻创建一个 direct consumer, 该 direct consumer 阻塞于接收返回值。对端的 consumer 接收并处理 producer 的消息后,创建一个 direct producer,它负责把处理结果发送给 direct consumer,如下图:
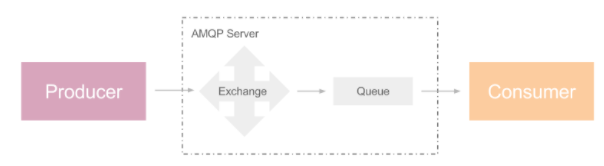
Cast: 异步调用,producer 发送消息后继续执行后续步骤,consumer 接收处理消息,如下图:
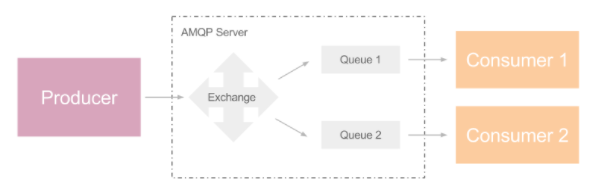
Fanout: 相当于广播,producer 可把消息发送给多个 consumer,属于异步调用范畴,如下图:
RabbitMQ简介与特点
RabbitMQ是一个开源的AMQP协议的实现,它具有如下特点:可靠性(Reliability), RabbitMQ使用一些机制来保证程序的可靠性,如持久化、传输确认机制、发布确认、高可用性。灵活的路由机制(Flexible Routing), 在消息进入队列之前,通过Exchange来路由消息的。对于典型的路由功能,RabbitMQ已经提供了一些内置的Exchange来实现。针对更复杂的路由功能,可以将多个Exchange绑定在一起,也通过插件机制实现自己的Exchange。消息集群(Clustering)多个RabbitMQ服务器可以组成一个集群,形成单个逻辑Broker。Federation, For servers that need to be more loosely and unreliably connected than clustering allows, RabbitMQ offers a federation model.队列高可用(Highly Available Queues), 队列可以在集群中的机器上进行镜像,以确保在硬件问题下还保证消息安全。多种协议的支持(Multi-protocol), RabbitMQ支持多种消息队列协议。
一个rabbitmq python例子
#coding:utf-8
import sys
from amqplib import client_0_8 as amqp
if __name__ == '__main__':if (len(sys.argv) <= 1):ispublisher = '0'print "Then pls run 'rabbittest 1' to sent message."else:ispublisher = sys.argv[1]conn = amqp.Connection(host="localhost:5672 ", userid="guest", password="password", virtual_host="/", insist=False)# 每个channel都被分配了一个整数标识chan = conn.channel()# 创建一个队列,它是durable的(重启后会重新建立)a# 消费者断开时不会自动删除(auto_delte=False)chan.queue_declare(queue="queue1", durable=True, exclusive=False, auto_delete=False)# 创建交换机,参数意思和上面的队列是一样的,还有一个type类型:fanout, direct, topicchan.exchange_declare(exchange="switch1", type="direct",durable=True, auto_delete=False,)# 绑定交换机和队列chan.queue_bind(queue="queue1", exchange="switch1", routing_key="key1")if (ispublisher == '1'):# 生产者msg = amqp.Message("Test message!")msg.properties["delivery_mode"] = 2chan.basic_publish(msg, exchange="switch1", routing_key="key1")else:# 主动从队列拉消息msg = chan.basic_get("queue1")print msg.bodychan.basic_ack(msg.delivery_tag)# 消息来了通知回调# 如果no_ack=True可以使用chan.basic_ack()人工确认,使用delivery_tag参数def recv_callback(msg):print 'Received: ' + msg.bodychan.basic_consume(queue='queue1', no_ack=False,callback=recv_callback, consumer_tag="testtag")# chan.basic_cancel("testtag") # 取消回调函数while True:chan.wait() # 等待在队列上,直到下一个消息到达队列。chan.close()conn.close()RabbitMQ CLI
安装,sudo apt-get install rabbitmq-server
重启,sudo service rabbitmq-server restart
sudo rabbitmqctl list_vhostssudo rabbitmqctl add_vhost demo
sudo rabbitmqctl list_users
sudo rabbitmqctl add_user test password
sudo rabbitmqctl change_password test password
sudo rabbitmqctl clear_password test
sudo rabbitmqctl list_user_permissions test
sudo rabbitmqctl set_permissions -p demo test ".*" ".*" ".*"
sudo rabbitmqctl clear_permissions -p demo test
sudo rabbitmqctl list_queues -p demo name durable auto_delete slave_pids synchronised_slave_pids
sudo rabbitmqadmin delete queue name='queuename'
sudo rabbitmqctl list_exchanges -p demosudo rabbitmqctl list_bindings -p demo
sudo rabbitmqctl list_consumers -p demosudo rabbitmqctl statussudo rabbitmqctl report# fileds can be: [name, durable, auto_delete, arguments, policy, pid, owner_pid, exclusive, exclusive_consumer_pid, exclusive_consumer_tag, messages_ready, messages_unacknowledged, messages, messages_ready_ram, messages_unacknowledged_ram, messages_ram, messages_persistent, message_bytes, message_bytes_ready, message_bytes_unacknowledged, message_bytes_ram, message_bytes_persistent, head_message_timestamp, disk_reads, disk_writes, consumers, consumer_utilisation, memory, slave_pids, synchronised_slave_pids, state]
sudo rabbitmqctl list_queues name slave_pids synchronised_slave_pids durable -p openstackRabbitMQ GUI
Enable it, sudo rabbitmq-plugins enable rabbitmq_management
http://localhost:15672 (guest/guest)RabbitMQ配置文件
http://www.rabbitmq.com/configure.html#configuration-file
sudo find / -name rabbitmq.config*
sudo mv /usr/share/doc/rabbitmq-server/rabbitmq.config.example.gz /etc/rabbitmq/cd /etc/rabbitmq/ && sudo gunzip rabbitmq.config.example.gz
sudo mv rabbitmq.config.example rabbitmq.configRabbitMQ调优
1, 流控(Flow Control)机制,默认RabbitMQ在使用机器的40%以上的内存时流控机制会起作用block掉所有连接。故确保使用64位操作系统与64位Erlang VM。当RabbitMQ是集群情况下,当其中有一台机器硬盘不足的时候,所有节点的producer链接也会被阻止。
rabbitmqctl set_vm_memory_high_watermark 0.4
rabbitmqctl set_vm_memory_high_watermark_paging_ratio 0.75
rabbitmqctl status
http://www.rabbitmq.com/memory.html
Max open files,/etc/default/rabbitmq-server
ulimit -n 65535
cat /proc/$RABBITMQ_BEAM_PROCESS_PID/limits2, Erlang的Hipe优化, 可以设置hipe_compiles设置。可以看到有20-50%的性能优化。而你只需要付出1分钟左右的延迟启动。 HiPE需要你检查是否编译进入你的Erlang安装环境。Ubuntu,需要安装erlang-base-hipe.默认有些平台不支持。如果Erlang VM segfaults,请关闭这个选项。
[{rabbit, [{hipe_compile, true}]}].RabbitMQ集群
跨三个节点部署 RabbitMQ 集群和镜像消息队列。可以使用 HAProxy 提供负载均衡,或者将 RabbitMQ host list 配置给 OpenStack 组件(使用 rabbit_hosts 和 rabbit_ha_queues 配置项)。
先看第一种方式(采用HAproxy):
# 每个节点上执行下列命令配置RabbitMQ集群
# 根据需要设置当前节点的工作模式(ram/disk),ROOT_NODE_HOSTNAME为集群根节点的主机名,注意在此必须使用主机名
apt-get install rabbitmq-server
rabbitmq-server -detached #detached为后台运行别占据终端
echo 'MYRABBITMQCLUSTERABC' > /var/lib/rabbitmq/.erlang.cookie
chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie
chmod 400 /var/lib/rabbitmq/.erlang.cookie
/usr/lib/rabbitmq/bin/rabbitmq-plugins enable rabbitmq_management
/usr/sbin/rabbitmqctl stop_app
/usr/sbin/rabbitmqctl reset
/usr/sbin/rabbitmqctl join_cluster --ram rabbit@${ROOT_NODE_HOSTNAME}
/usr/sbin/rabbitmqctl start_app
service rabbitmq-server restart
# 在主节点上添加用户
/usr/sbin/rabbitmqctl add_user web_admin password
/usr/sbin/rabbitmqctl add_user mgmt_admin password
/usr/sbin/rabbitmqctl set_user_tags username monitoring
/usr/sbin/rabbitmqctl set_user_tags mgmt_admin administrator
/usr/sbin/rabbitmqctl rabbitmqctl list_users
/usr/sbin/rabbitmqctl set_permissions -p / mgmt_admin ".*" ".*" ".*"
# 设置HAProxy, 需要设置成镜像队列,可以访问http://192.168.64.87:8888,用户名web_admin/password进行访问
/usr/sbin/rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
修改文件:/etc/haproxy/haproxy.cfg
listen rabbitmq_cluster 0.0.0.0:5672
mode tcp
balance roundrobin
server node1 192.168.1.1:5672 check inter 2000 rise 2 fall 3
/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -D第二种使用 rabbit_hosts 和 rabbit_ha_queues 配置项:
rabbit_hosts = rabbit1:5672,rabbit2:5672
rabbit_host = rabbit1
rabbit_ha_queues = true
如果配置了rabbit_hosts,那么nova将会按照顺序连接一个RabbitMQ服务,如果正在使用的MQ服务断开则依次尝试连接下一个,由于所有MQ的消息都是同步的,所以消息不会丢失。
如果配置了rabbit_host,那么需要在集群前架设haproxy,保证集群VIP服务正常。confirm that actual queue is connected and can consume that queue. sudo rabbitmq-plugins enable rabbitmq_management
wget http://127.0.0.1:15672/cli/rabbitmqadmin && chmod 777 rabbitmqadmi
sudo rabbitmqctl add_user test password
sudo rabbitmqctl set_user_tags test administrator
sudo rabbitmqctl set_permissions -p openstack test ".*" ".*" ".*"
http://10.5.0.6:15672/#/queues/openstack/compute.juju-a09725-xenial-mitaka-7
./rabbitmqadmin publish -V openstack -u test -p password exchange=nova routing_key=compute.juju-a09725-xenial-mitaka-7 payload="test"
tail -f /var/log/nova/nova-compute.log具体地见:http://m.blog.csdn.net/blog/gtt116/21083533Debug Hacks
$ tshark -r xxx.pcap |awk '{arr[$5]++}END{for (a in arr) print a, arr[a]}' |sort -n -k 2 -r | head -n 3
10.55.74.103 62756
10.55.74.142 12976
10.55.74.139 12228
juju run -u rabbitmq-server/0 'sudo rabbitmqctl list_queues -p openstack|grep -wv 0'watch -c "sudo rabbitmqctl list_queues -p openstack | grep -E 'log|neutron|agent'" Reset rabbitmq slave
1) On juju-3182a3-69-lxd-2, back mnesia, stop the service
$ sudo mv /var/lib/rabbitmq/mnesia /var/lib/rabbitmq/mnesia-back
$ sudo service rabbitmq-server stop
2) Forget the cluster nodes from the rabbit master node
$ sudo rabbitmqctl stop_app
$ sudo rabbitmqctl forget_cluster_node rabbit@juju-3182a3-69-lxd-2
$ sudo rabbitmqctl start_app如何恢复systemd管理的native mirror rabbitmq cluster
如何恢复systemd管理的native mirror rabbitmq cluster
1, 确保在3个节点上,rabbitmq-server先由systemd启动(随后会由pacemaker接管),这样能可能运行rabbitmqctl cluster_status命令.假设此时3个节点各自为政.
juju run --application=rabbitmq-server 'sudo rabbitmqctl cluster_status'2, juju status看有没有error状态,例如现在看到rabbitmq-server/1因为下列日志为error状态, rabbitmq-server/1上运行:
https://www.jianshu.com/p/498c63e4ace1
https://ywnz.com/linuxyffq/3899.html
2020-02-21 09:24:09 DEBUG config-changed subprocess.CalledProcessError: Command '['timeout', '180', '/usr/sbin/rabbitmqctl', 'wait', '/var/lib/rabbitmq/mnesia/rabbit@juju-cbd760-octavia-10.pid']' returned non-zero exit status 70.
systemctl restart rabbitmq-server
rabbitmqctl status |grep pid #write pid to /var/lib/rabbitmq/mnesia/rabbit@juju-cbd760-octavia-10.pid
rabbitmqctl wait /var/lib/rabbitmq/mnesia/rabbit@juju-cbd760-octavia-10.pid
juju resolved rabbitmq-server/1 --no-retry
[可选]确保juju status没有rabbitmq untis相关错误之后,触发hooks
juju run --application ha hooks/config-changed
juju run --application rabbitmq-server hooks/ha-relation-joined
juju show-status-log neutron-openvswitch/23, 没有ceph的情况下,代码显示必须有ha-vip-only=true
juju deploy -n 3 rabbitmq-server
juju deploy hacluster ha
juju add-relation rabbitmq-server ha
juju config rabbitmq-server vip=10.5.100.20
juju config rabbitmq-server vip_iface=ens3
juju config ha corosync_bindiface=ens3
juju config rabbitmq-server ha-vip-only=true
juju config ha cluster_count=3
juju config rabbitmq-server min-cluster-size=34, 找到leader,假如leader是rabbitmq-server/1,并在其上找到cluster_name
juju run --application rabbitmq-server "is-leader" #assue rabbitmq-server/1 is the leader
root@juju-cbd760-octavia-10:~# rabbitmqctl cluster_status |grep cluster{cluster_name,<<"rabbitmq-server@juju-cbd760-octavia-10">>},5, rabbitmq-server/1, 把RABBITMQ_NODENAME由localhost改成juju-cbd760-octavia-10
root@juju-cbd760-octavia-10:~# grep -r 'RABBITMQ_NODENAME' /etc/rabbitmq/rabbitmq-env.conf
RABBITMQ_NODENAME=rabbitmq-server@juju-cbd760-octavia-10
root@juju-cbd760-octavia-10:~# cat /var/lib/rabbitmq/.erlang.cookie
CZIFVOYCELFFGUFWJBZY
systemctl restart rabbitmq-server
rabbitmqctl cluster_status但代码中有这一句会在ha-vip-only=false时将RABBITMQ_NODENAME设为localhost, 所以ha-vip-only应为ha-vip-only,
同时,这里也说对于rabbitmq的hacluster方式的ha已经废弃了
https://github.com/openstack/charm-rabbitmq-server/blob/master/hooks/rabbitmq_context.py#L250# TODO: this is legacy HA and should be removed since it is now# deprecated.if relation_ids('ha'):if not config('ha-vip-only'):# TODO: do we need to remove this setting if it already exists# and the above is false?context['settings']['RABBITMQ_NODENAME'] = \'{}@localhost'.format(service_name())6, 登录到rabbitmq-server/0, 修改hostname并加入集群
root@juju-cbd760-octavia-9:~# grep -r 'RABBITMQ_NODENAME' /etc/rabbitmq/rabbitmq-env.conf
RABBITMQ_NODENAME=rabbitmq-server@juju-cbd760-octavia-9
systemctl restart rabbitmq-server
rabbitmqctl cluster_status
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbitmq-server@juju-cbd760-octavia-10
rabbitmqctl cluster_status7, 登录到rabbitmq-server/2重复上一步,只是hostname不同, 这里为juju-cbd760-octavia-118, 此时.
root@juju-cbd760-octavia-10:~# rabbitmqctl cluster_status
Cluster status of node 'rabbitmq-server@juju-cbd760-octavia-10'
[{nodes,[{disc,['rabbitmq-server@juju-cbd760-octavia-10','rabbitmq-server@juju-cbd760-octavia-11','rabbitmq-server@juju-cbd760-octavia-9']}]},{running_nodes,['rabbitmq-server@juju-cbd760-octavia-10']},{cluster_name,<<"rabbitmq-server@juju-cbd760-octavia-10">>},{partitions,[]},{alarms,[{'rabbitmq-server@juju-cbd760-octavia-10',[]}]}]9, 但上面修复只是systemd管理的native集群.如何被pacemaker管理呢? 在rabbmitmq-server/1上(juju-cbd760-octavia-10)停掉systemd,启动corosync与packemaker,但前提是hacluster charm已经成功为corosync配置了res_rabbitmq_vip resources (当ha-vip-only=true时只有这一个)此时看到crm status没有res_rabbitmq_vip这个resource,
#juju run --application rabbitmq-server hooks/ha-relation-joined
juju run --application ha hooks/config-changed
juju run --unit ha/0 "sudo corosync-quorumtool -s"
juju run --unit ha/0 "sudo crm status"
juju run --unit ha/0 "sudo crm resource restart res_rabbitmq_vip"
juju run --unit ha/0 "sudo crm resource clean res_rabbitmq_vip"
#https://github.com/ClusterLabs/resource-agents/blob/master/heartbeat/rabbitmq-cluster
ls /usr/lib/ocf/resource.d/rabbitmq/rabbitmq-server-ha若运行上面hook无法加入res_rabbitmq_vip的话,检查代码是应该设置ha-vip-only=true,然后使用下面方法添加:
juju remove-relation rabbitmq-server ha
juju add-relation rabbitmq-server ha然后可以看到:
root@juju-cbd760-octavia-11:~# crm status |grep vipres_rabbitmq_vip (ocf::heartbeat:IPaddr2): Started juju-cbd760-octavia-10但是仍然看到这种错误:
ubuntu@zhhuabj-bastion:~$ juju status |grep waiting
rabbitmq-server 3.6.10 waiting 3 rabbitmq-server jujucharms 358 ubuntu
rabbitmq-server/0 waiting idle 9 10.5.0.35 5672/tcp Unit has peers, but RabbitMQ not clustered
rabbitmq-server/1* waiting idle 10 10.5.0.32 5672/tcp Unit has peers, but RabbitMQ not clustered
rabbitmq-server/2 waiting idle 11 10.5.0.28 5672/tcp Unit has peers, but RabbitMQ not clustered10, 继续调试, ha relation的数目不对,所以停在' Unit has peers, but RabbitMQ not clustered'
ubuntu@zhhuabj-bastion:~$ juju run --unit rabbitmq-server/0 "relation-ids ha"
ha:41
ubuntu@zhhuabj-bastion:~$ juju run --unit rabbitmq-server/0 "relation-list -r ha:41"
ha/3 #because hacluster was named to ha so name is ha/3 now
ubuntu@zhhuabj-bastion:~$ juju run --unit rabbitmq-server/0 "relation-get -r ha:41 - ha/3"
clustered: "yes"
egress-subnets: 10.5.0.35/32
ingress-address: 10.5.0.35
private-address: 10.5.0.35它在找rabbitmqctl cluster_status中为running_nodes的个数828 @cached 829 def clustered(): 830 ''' Determine whether local rabbitmq-server is clustered '''831 # NOTE: A rabbitmq node can only join a cluster once.832 # Simply checking for more than one running node tells us833 # if this unit is in a cluster.834 if len(running_nodes()) > 1:835 return True836 else: 837 return False787 @cached 788 def running_nodes():789 ''' Determine the current set of running nodes in the RabbitMQ cluster '''790 return nodes(get_running=True)770 @cached 771 def nodes(get_running=False):772 ''' Get list of nodes registered in the RabbitMQ cluster '''773 out = rabbitmqctl_normalized_output('cluster_status')774 cluster_status = {}775 for m in re.finditer("{([^,]+),(?!\[{)\[([^\]]*)", out):776 state = m.group(1)777 items = m.group(2).split(',')778 items = [x.replace("'", '').strip() for x in items]779 cluster_status.update({state: items})780 781 if get_running:782 return cluster_status.get('running_nodes', []) 783 784 return cluster_status.get('disc', []) + cluster_status.get('ram', [])Olso messaging
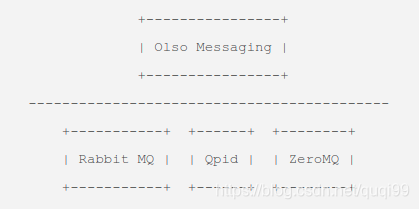
OpenStack 有三大常用消息中间件,RabbitMQ,QPID 和 ZeroMQ,它们参数和接口各异,不利于直接使用,所以 oslo.messaging 对这三种消息中间件做了抽象和封装,为上层提供统一的接口。
Oslo.messaging 抽象出了两类数据:
- Transport: 消息中间件的基本参数,如 host, port 等信息。
- RabbitMQ:host, port, userid, password, virtual_host, durable_queues, ha_queues 等。
- Qpid: hostname, port, username, password, protocol (tcp or ssl) 等。
- ZeroMQ: bind_address, host, port, ipc_dir 等。
- Target: 主要包括 exchange, topic, server (optional), fanout (defaults to False) 等消息通信时用到的参数。
示例如下:
rabbitmqctl add_user hua hua
rabbitmqctl set_user_tags hua administrator
rabbitmqctl set_permissions -p / hua '.*' '.*' '.*'
rabbitmqctl list_users
rabbitmqctl list_user_permissions huaapt install rabbitmq-server python3-oslo.config python3-oslo.messaging -y# python3 consumer.py myserver
# cat consumer.py
#!/usr/bin/python
from oslo_config import cfg
import oslo_messaging
import sys
import timeclass TestEndpoint(object):def test(self, ctx, a,b):print("receive client access")return a+btransport_url = 'rabbit://hua:hua@127.0.0.1:5672/'
server = sys.argv[1]
transport = oslo_messaging.get_transport(cfg.CONF,transport_url)
target = oslo_messaging.Target(topic='test', server=server)
endpoints = [TestEndpoint(),
]
server = oslo_messaging.get_rpc_server(transport, target, endpoints)
try:server.start()while True:time.sleep(1)
except KeyboardInterrupt:print("Stopping server")server.stop()
server.wait()#cat producer.py
#!/usr/bin/pythonfrom oslo_config import cfg
import oslo_messagingtransport_url = 'rabbit://hua:hua@127.0.0.1:5672/'
transport = oslo_messaging.get_transport(cfg.CONF,transport_url)
target = oslo_messaging.Target(topic='test')
client = oslo_messaging.RPCClient(transport, target)
r = client.call({}, 'test',a=2,b=3)
print(r)
print('success')或
#cat consumer.py
#-*- coding:utf-8 -*-
from oslo_config import cfg
import oslo_messaging as messaging
import timeclass ServerControlEndpoint(object):target = messaging.Target(namespace='control', version='2.0')def __init__(self, server):self.server = serverdef stop(self, ctx):print("Call ServerControlEndpoint.stop()") if self.server is not None:self.server.stop()class TestEndpoint(object):def test(self, ctx, arg):print("Call TestEndpoint.test()")return argmessaging.set_transport_defaults('myexchange')
transport = messaging.get_transport(cfg.CONF,url='rabbit://hua:hua@127.0.0.1:5672/')
target = messaging.Target(topic='testtopic', server='server1')
endpoints = [ServerControlEndpoint(None),TestEndpoint(),
]
server = messaging.get_rpc_server(transport, target, endpoints)
try:server.start()while True:time.sleep(1)
except KeyboardInterrupt:print("Stopping server")
server.stop()
server.wait()
transport.cleanup()#cat producer.py
#-*- coding:utf-8 -*-from oslo_config import cfg
from oslo_log import log as logging
import oslo_messaging as messaging
import sys# log initialization
CONF = cfg.CONF
logging.register_options(CONF)
CONF(sys.argv[1:])
logging.setup(CONF, "producer")
#module log init
LOG = logging.getLogger(__name__)
messaging.set_transport_defaults('myexchange')
LOG.info("Create a transport...")
transport= messaging.get_transport(cfg.CONF,url='rabbit://hua:hua@127.0.0.1:5672')
#construct target, topic parameter is essential
LOG.info("Creating target")
target= messaging.Target(topic='testtopic',server='server1')运行它之后,会看到:
- 用“rabbitmqctl list_exchanges”看到两个exchanges(testtopic_fanout fanout 与 myexchange topic)
- 用“rabbitmqctl list_queues”看到3个, 其中fanout这个在stop 之后会消失,其他两个topic queue不会, 见:https://review.opendev.org/c/openstack/oslo.messaging/+/243845/5/oslo_messaging/_drivers/impl_rabbit.py#170
# rabbitmqctl list_queues
Timeout: 60.0 seconds ...
Listing queues for vhost / ...
name messages
testtopic 0
testtopic.server1 0
testtopic_fanout_04f2ffd679034508891dc52f20864d37 0
这样,在heat中,重启一次会生成下列4个topic queues,同时加4个fanout queues, fanout queues在一段TTL时间后会消失,但下列4个topic queues不会,所以heat的exchange与queue数目会一直增加,最后提升CPU利用率恶性循环
root@juju-c1fca3-heat-12:~# rabbitmqctl list_queues -p openstack | grep -E 'engine_worker|heat-engine-listener' |grep -E '42cee820-4f0c-4aef-b8b6-705e7db3253a|8c12d70c-b00c-4e9b-b33e-7cbf0cb8c510'
engine_worker.42cee820-4f0c-4aef-b8b6-705e7db3253a 0
engine_worker.8c12d70c-b00c-4e9b-b33e-7cbf0cb8c510 0
heat-engine-listener.42cee820-4f0c-4aef-b8b6-705e7db3253a 0
heat-engine-listener.8c12d70c-b00c-4e9b-b33e-7cbf0cb8c510 0在service.py#start中传进去的engine_id是每次重启随机的:
self.worker_service = worker.WorkerService( host=self.host, topic=rpc_worker_api.TOPIC, engine_id=self.engine_id, thread_group_mgr=self.thread_group_mgr ) self.worker_service.start() WorerService的将用engine_id作为server, 所以将产生众多 engine_worker.<engine_id>的topic queue.
def start(self): target = oslo_messaging.Target( version=self.RPC_API_VERSION, server=self.engine_id, topic=self.topic) self.target = target LOG.info("Starting %(topic)s (%(version)s) in engine %(engine)s.", {'topic': self.topic, 'version': self.RPC_API_VERSION, 'engine': self.engine_id}) self._rpc_server = rpc_messaging.get_rpc_server(target, self) self._rpc_server.start() 数据库记录类似:
mysql> select * from service;
...+--------------------------------------+--------------------------------------+------+--------------------+-------------+--------+-----------------+---------------------+---------------------+---------------------+
| id | engine_id | host | hostname | binary | topic | report_interval | created_at | updated_at | deleted_at |
+--------------------------------------+--------------------------------------+------+--------------------+-------------+--------+-----------------+---------------------+---------------------+---------------------+
| 21d903ba-205b-45db-a2bf-2399f07f34a0 | 054c180e-88cd-41f3-8c1a-d66f8dba9696 | heat | juju-c1fca3-heat-2 | heat-engine | engine | 60 | 2021-04-15 04:24:58 | 2021-04-15 06:43:58 | NULL按道理说,是不应该产生这么topic queue (engine_worker.<engine_id>)的名字的,所有heat service共用一个topic queue (engine_worker), 但后每个heat service用engine_id作为routing_id, 但是在oslo_messaging中的routing_key是变量topic
def declare_topic_consumer(self, exchange_name, topic, callback=None, queue_name=None): """Create a 'topic' consumer.""" consumer = Consumer( exchange_name=exchange_name, queue_name=queue_name or topic, routing_key=topic, type='topic', durable=self.amqp_durable_queues, exchange_auto_delete=self.amqp_auto_delete, queue_auto_delete=self.amqp_auto_delete, callback=callback, rabbit_ha_queues=self.rabbit_ha_queues, enable_cancel_on_failover=self.enable_cancel_on_failover) heat#worker.py是这样设置topic的, topic是固定义的:
def start(self): target = oslo_messaging.Target( version=self.RPC_API_VERSION, server=self.engine_id, topic=self.topic) self.target = target LOG.info("Starting %(topic)s (%(version)s) in engine %(engine)s.", {'topic': self.topic, 'version': self.RPC_API_VERSION, 'engine': self.engine_id}) self._rpc_server = rpc_messaging.get_rpc_server(target, self) self._rpc_server.start() 同时heat#work.py传进去的server参数最后用在olso_messaging中的_send方法中:
if notify: exchange = self._get_exchange(target) LOG.debug(log_msg + "NOTIFY exchange '%(exchange)s'" " topic '%(topic)s'", {'exchange': exchange, 'topic': target.topic}) conn.notify_send(exchange, target.topic, msg, retry=retry) elif target.fanout: log_msg += "FANOUT topic '%(topic)s'" % { 'topic': target.topic} LOG.debug(log_msg) conn.fanout_send(target.topic, msg, retry=retry) else: topic = target.topic exchange = self._get_exchange(target) if target.server: topic = '%s.%s' % (target.topic, target.server) LOG.debug(log_msg + "exchange '%(exchange)s'" " topic '%(topic)s'", {'exchange': exchange, 'topic': topic}) conn.topic_send(exchange_name=exchange, topic=topic, msg=msg, timeout=timeout, retry=retry, transport_options=transport_options)def _get_exchange(self, target): return target.exchange or self._default_exchange 难道是要这种写法?
$ git diff
diff --git a/heat/engine/service.py b/heat/engine/service.py
index bd3631df7..dccd90836 100644
--- a/heat/engine/service.py
+++ b/heat/engine/service.py
@@ -309,8 +309,8 @@ class EngineListener(object):def start(self):self.target = messaging.Target(
- server=self.engine_id,
- topic=rpc_api.LISTENER_TOPIC)
+ topic=self.engine_id,
+ exchange=rpc_api.LISTENER_TOPIC)self._server = rpc_messaging.get_rpc_server(self.target, self)self._server.start()diff --git a/heat/engine/worker.py b/heat/engine/worker.py
index ea8553d75..9a2b771af 100644
--- a/heat/engine/worker.py
+++ b/heat/engine/worker.py
@@ -80,8 +80,8 @@ class WorkerService(object):def start(self):target = oslo_messaging.Target(version=self.RPC_API_VERSION,
- server=self.engine_id,
- topic=self.topic)
+ topic=self.engine_id,
+ exchange=self.topic)self.target = targetLOG.info("Starting %(topic)s (%(version)s) in engine %(engine)s.",{'topic': self.topic,
另外一种方式是在charm里去设置TTL:
sudo rabbitmqctl set_policy heat_expiry "heat-engine-listener|engine_worker" "{'expires':3600000}" -p openstack --apply-to queues --priority 1其余listener的用法可以继续查看: https://blog.csdn.net/jxxiaohou/article/details/78386879
20210906更新 - 一些rabbitmq基本操作
https://bugs.launchpad.net/oslo.messaging/+bug/1789177
Fix a rabbitmq issue
https://zhhuabj.blog.csdn.net/article/details/105847301
Reference
[1] https://gist.github.com/niedbalski/69a72103adad4f0f9609a0857c9810a4
[2] https://pastebin.ubuntu.com/p/sJ94RmmS5x/
这篇关于RabbitMQ Deep Dive (by quqi99)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






