本文主要是介绍中科大计算机与华科,数据对比华中科技大学和中国科技大学,毫无争议,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
华中科技大学和中国科技大学都是我国的著名高校,都有985、211、双一流A类大学的光环,华中科技大学感觉是“大而全” ,中国科技大学是“小而精” ,至于综合实力哪个强,我们还是来对比一下。
一、地理位置。
华中科技大学位于湖北武汉,武汉是新一线城市,发展潜力巨大。

中国科技大学位于安徽合肥,合肥还不是新一线城市。

二、2020年QS世界大学排名比较。
华中科技大学QS排名全国第15名,世界排名第400名。
中国科技大学QS排名全国第6名,世界排名第89名。
三、第四轮学科评估结果比较。
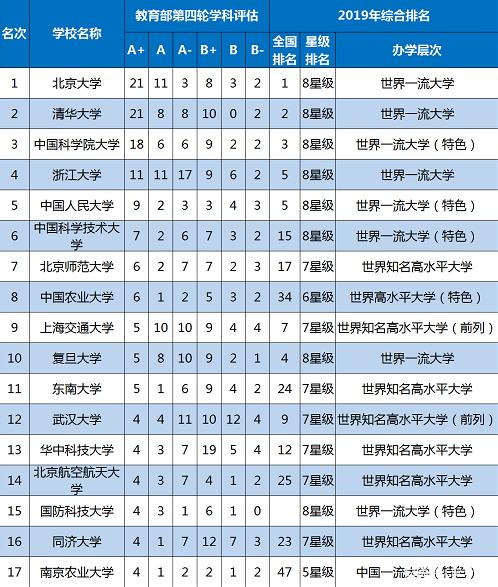
华中科技大学A类学科总数14个。其中A+档4个;A档3个;A-档7个。
中国科技大学A类学科总数15个。其中其中A+档7个;A档2个,A-档6个。
四、双一流学科比较。
华中科技大学的双一流学科有8个:机械工程、光学工程、材料科学与工程、动力工程及工程热物理、电气工程、计算机科学与技术、基础医学、公共卫生与预防医学。
中国科技大学的双一流学科有11个:数学、物理学、 化学、 天文学、地球物理学、生物学、科学技术史、材料科学与工程、计算机科学与技术、核科学与技术、安全科学与工程。
五、国家级特色专业比较。
华中科技大学国家级特色专业:新闻学、信息安全、电子科学与技术、软件工程、临床医学、机械设计制造及其自动化、热能与动力工程、电气工程及其自动化、计算机科学与技术、工程力学、预防医学、生物技术、材料成型及控制工程、自动化、通信工程、广播电视新闻学、光信息科学与技术、药学、物流管理、新能源科学与工程、光电子材料与器件、经济学、材料科学与工程、城市规划、公共事业管理。
中国科技大学国家级特色专业:数学类、物理学类、电子信息工程、化学、计算机科学与技术、生物科学、地球物理学、信息安全、软件系统设计、嵌入式系统设计。
六、保研率比较。
2020届华中科技大学的保研率为25.47%,中国科技大学保研率为38.62%。
七、录取分数线比较。
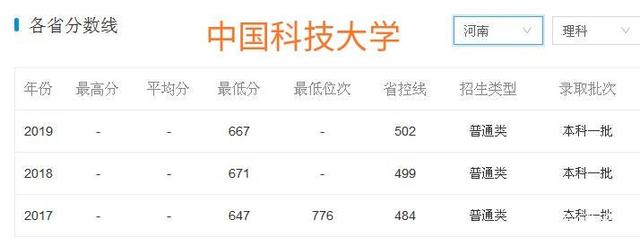
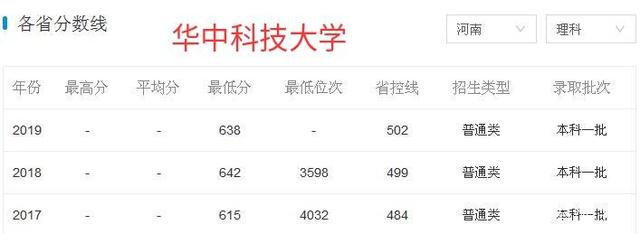
以河南为例,中国科技大学近三年录取分数线都大大高于华中科技大学。
综上所述,我认为两所大学都是我国的顶层学校,论综合实力必然是中国中国科技大学更胜一筹,不过对于我们考生个体,还是要根据自己情况来填报志愿。
举报/反馈
这篇关于中科大计算机与华科,数据对比华中科技大学和中国科技大学,毫无争议的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









