本文主要是介绍u2net实现视频图像分割(从原理到实践),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、U2net简单介绍
1、U2net网络结构:

整个网络成对称U型结构,使用的是经典的编解码结构,在每一个Sup内部又是U形结构,采用的是深监督的方式,有效结合浅层和深层的语义信息。进行了5次下采样和5次上采样,上采样的方式通过torch.nn.functional.interpolate()函数实现,下采样通过torch.nn.MaxPool2d() 步长为2的最大平均池化实现。在每一个En_x中使用RSU模块,RSU模块的结构如下:
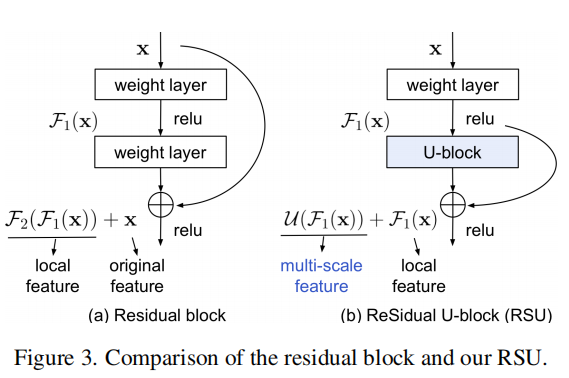
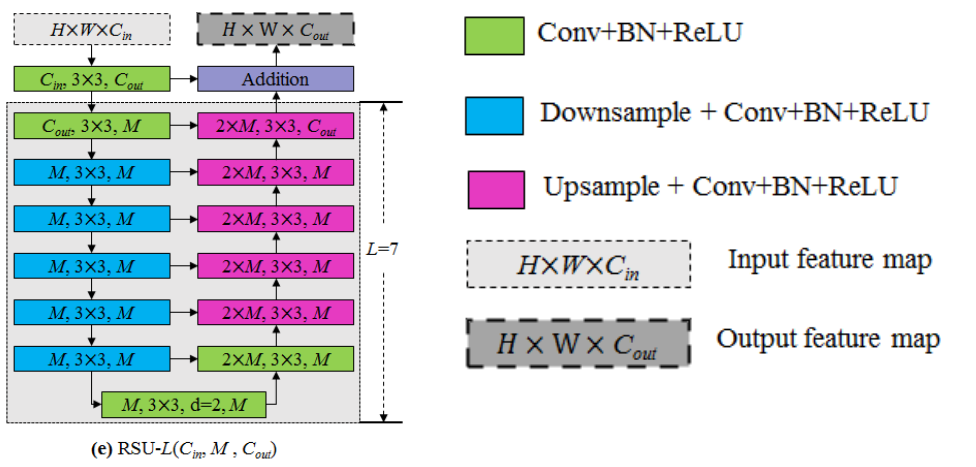
RSU模块的作用是获得在不同阶段的多尺度特征(L指的是在编码器中的层数,Cin和Cout分别代表输入通道核输出通道,M表示RSU内部层中的通道数),该结构主要由3部分构成:
(1)输入的卷积层,将输入的特征图转为和输出相同的通道数的中间映射用于局部特征提取
(2)一种高度为L的对称式编解码结构,将中间映射作为输入,提取和学习多尺度的语义信息
(3)用于融合局部特征和所尺度特征的残差结构
在U2Net中同时使用了add和Concate
2、损失函数:

因为有6个Sup,所以有6个损失函数,每一个Sup的损失使用的是标准交叉熵损失函数

二、代码部分:
网络部分对照着图看还是比较清晰的,其余大部分文件添加了注释,方便自己二次回顾
1、U2net.py
import torch
import torch.nn as nn
from torchvision import models
import torch.nn.functional as Fclass REBNCONV(nn.Module): #CBLdef __init__(self,in_ch=3,out_ch=3,dirate=1):super(REBNCONV,self).__init__()self.conv_s1 = nn.Conv2d(in_ch,out_ch,3,padding=1*dirate,dilation=1*dirate)self.bn_s1 = nn.BatchNorm2d(out_ch)self.relu_s1 = nn.ReLU(inplace=True)def forward(self,x):hx = xxout = self.relu_s1(self.bn_s1(self.conv_s1(hx)))return xoutdef _upsample_like(src,tar):# src = F.upsample(src,size=tar.shape[2:],mode='bilinear')src = F.interpolate(src,size=tar.shape[2:],mode='bilinear',align_corners=True) # https://www.cnblogs.com/wanghui-garcia/p/11399034.html# nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)return src### RSU-7 ###
class RSU7(nn.Module):#UNet07DRES(nn.Module): #En_1 def __init__(self, in_ch=3, mid_ch=12, out_ch=3):super(RSU7,self).__init__()self.rebnconvin = REBNCONV(in_ch,out_ch,dirate=1) #CBR1self.rebnconv1 = REBNCONV(out_ch,mid_ch,dirate=1) #CBR2self.pool1 = nn.MaxPool2d(2,stride=2,ceil_mode=True) self.rebnconv2 = REBNCONV(mid_ch,mid_ch,dirate=1)self.pool2 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv3 = REBNCONV(mid_ch,mid_ch,dirate=1) self.pool3 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv4 = REBNCONV(mid_ch,mid_ch,dirate=1)self.pool4 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv5 = REBNCONV(mid_ch,mid_ch,dirate=1)self.pool5 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv6 = REBNCONV(mid_ch,mid_ch,dirate=1)self.rebnconv7 = REBNCONV(mid_ch,mid_ch,dirate=2)self.rebnconv6d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv5d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv4d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv3d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv2d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv1d = REBNCONV(mid_ch*2,out_ch,dirate=1)def forward(self,x):hx = xhxin = self.rebnconvin(hx)hx1 = self.rebnconv1(hxin)hx = self.pool1(hx1)hx2 = self.rebnconv2(hx)hx = self.pool2(hx2)hx3 = self.rebnconv3(hx)hx = self.pool3(hx3)hx4 = self.rebnconv4(hx)hx = self.pool4(hx4)hx5 = self.rebnconv5(hx)hx = self.pool5(hx5)hx6 = self.rebnconv6(hx)hx7 = self.rebnconv7(hx6) #dialation=2hx6d = self.rebnconv6d(torch.cat((hx7,hx6),1))hx6dup = _upsample_like(hx6d,hx5)hx5d = self.rebnconv5d(torch.cat((hx6dup,hx5),1))hx5dup = _upsample_like(hx5d,hx4)hx4d = self.rebnconv4d(torch.cat((hx5dup,hx4),1))hx4dup = _upsample_like(hx4d,hx3)hx3d = self.rebnconv3d(torch.cat((hx4dup,hx3),1))hx3dup = _upsample_like(hx3d,hx2)hx2d = self.rebnconv2d(torch.cat((hx3dup,hx2),1))hx2dup = _upsample_like(hx2d,hx1)hx1d = self.rebnconv1d(torch.cat((hx2dup,hx1),1))return hx1d + hxin### RSU-6 ###
class RSU6(nn.Module):#UNet06DRES(nn.Module):def __init__(self, in_ch=3, mid_ch=12, out_ch=3):super(RSU6,self).__init__()self.rebnconvin = REBNCONV(in_ch,out_ch,dirate=1)self.rebnconv1 = REBNCONV(out_ch,mid_ch,dirate=1)self.pool1 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv2 = REBNCONV(mid_ch,mid_ch,dirate=1)self.pool2 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv3 = REBNCONV(mid_ch,mid_ch,dirate=1)self.pool3 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv4 = REBNCONV(mid_ch,mid_ch,dirate=1)self.pool4 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv5 = REBNCONV(mid_ch,mid_ch,dirate=1)self.rebnconv6 = REBNCONV(mid_ch,mid_ch,dirate=2)self.rebnconv5d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv4d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv3d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv2d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv1d = REBNCONV(mid_ch*2,out_ch,dirate=1)def forward(self,x):hx = xhxin = self.rebnconvin(hx)hx1 = self.rebnconv1(hxin)hx = self.pool1(hx1)hx2 = self.rebnconv2(hx)hx = self.pool2(hx2)hx3 = self.rebnconv3(hx)hx = self.pool3(hx3)hx4 = self.rebnconv4(hx)hx = self.pool4(hx4)hx5 = self.rebnconv5(hx)hx6 = self.rebnconv6(hx5)hx5d = self.rebnconv5d(torch.cat((hx6,hx5),1))hx5dup = _upsample_like(hx5d,hx4)hx4d = self.rebnconv4d(torch.cat((hx5dup,hx4),1))hx4dup = _upsample_like(hx4d,hx3)hx3d = self.rebnconv3d(torch.cat((hx4dup,hx3),1))hx3dup = _upsample_like(hx3d,hx2)hx2d = self.rebnconv2d(torch.cat((hx3dup,hx2),1))hx2dup = _upsample_like(hx2d,hx1)hx1d = self.rebnconv1d(torch.cat((hx2dup,hx1),1))return hx1d + hxin### RSU-5 ###
class RSU5(nn.Module):#UNet05DRES(nn.Module):def __init__(self, in_ch=3, mid_ch=12, out_ch=3):super(RSU5,self).__init__()self.rebnconvin = REBNCONV(in_ch,out_ch,dirate=1)self.rebnconv1 = REBNCONV(out_ch,mid_ch,dirate=1)self.pool1 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv2 = REBNCONV(mid_ch,mid_ch,dirate=1)self.pool2 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv3 = REBNCONV(mid_ch,mid_ch,dirate=1)self.pool3 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv4 = REBNCONV(mid_ch,mid_ch,dirate=1)self.rebnconv5 = REBNCONV(mid_ch,mid_ch,dirate=2)self.rebnconv4d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv3d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv2d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv1d = REBNCONV(mid_ch*2,out_ch,dirate=1)def forward(self,x):hx = xhxin = self.rebnconvin(hx)hx1 = self.rebnconv1(hxin)hx = self.pool1(hx1)hx2 = self.rebnconv2(hx)hx = self.pool2(hx2)hx3 = self.rebnconv3(hx)hx = self.pool3(hx3)hx4 = self.rebnconv4(hx)hx5 = self.rebnconv5(hx4)hx4d = self.rebnconv4d(torch.cat((hx5,hx4),1))hx4dup = _upsample_like(hx4d,hx3)hx3d = self.rebnconv3d(torch.cat((hx4dup,hx3),1))hx3dup = _upsample_like(hx3d,hx2)hx2d = self.rebnconv2d(torch.cat((hx3dup,hx2),1))hx2dup = _upsample_like(hx2d,hx1)hx1d = self.rebnconv1d(torch.cat((hx2dup,hx1),1))return hx1d + hxin### RSU-4 ###
class RSU4(nn.Module):#UNet04DRES(nn.Module):def __init__(self, in_ch=3, mid_ch=12, out_ch=3):super(RSU4,self).__init__()self.rebnconvin = REBNCONV(in_ch,out_ch,dirate=1)self.rebnconv1 = REBNCONV(out_ch,mid_ch,dirate=1)self.pool1 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv2 = REBNCONV(mid_ch,mid_ch,dirate=1)self.pool2 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.rebnconv3 = REBNCONV(mid_ch,mid_ch,dirate=1)self.rebnconv4 = REBNCONV(mid_ch,mid_ch,dirate=2)self.rebnconv3d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv2d = REBNCONV(mid_ch*2,mid_ch,dirate=1)self.rebnconv1d = REBNCONV(mid_ch*2,out_ch,dirate=1)def forward(self,x):hx = xhxin = self.rebnconvin(hx)hx1 = self.rebnconv1(hxin)hx = self.pool1(hx1)hx2 = self.rebnconv2(hx)hx = self.pool2(hx2)hx3 = self.rebnconv3(hx)hx4 = self.rebnconv4(hx3)hx3d = self.rebnconv3d(torch.cat((hx4,hx3),1))hx3dup = _upsample_like(hx3d,hx2)hx2d = self.rebnconv2d(torch.cat((hx3dup,hx2),1))hx2dup = _upsample_like(hx2d,hx1)hx1d = self.rebnconv1d(torch.cat((hx2dup,hx1),1))return hx1d + hxin### RSU-4F ###
class RSU4F(nn.Module):#UNet04FRES(nn.Module):def __init__(self, in_ch=3, mid_ch=12, out_ch=3):super(RSU4F,self).__init__()self.rebnconvin = REBNCONV(in_ch,out_ch,dirate=1)self.rebnconv1 = REBNCONV(out_ch,mid_ch,dirate=1)self.rebnconv2 = REBNCONV(mid_ch,mid_ch,dirate=2)self.rebnconv3 = REBNCONV(mid_ch,mid_ch,dirate=4)self.rebnconv4 = REBNCONV(mid_ch,mid_ch,dirate=8)self.rebnconv3d = REBNCONV(mid_ch*2,mid_ch,dirate=4)self.rebnconv2d = REBNCONV(mid_ch*2,mid_ch,dirate=2)self.rebnconv1d = REBNCONV(mid_ch*2,out_ch,dirate=1)def forward(self,x):hx = xhxin = self.rebnconvin(hx)hx1 = self.rebnconv1(hxin)hx2 = self.rebnconv2(hx1)hx3 = self.rebnconv3(hx2)hx4 = self.rebnconv4(hx3)hx3d = self.rebnconv3d(torch.cat((hx4,hx3),1))hx2d = self.rebnconv2d(torch.cat((hx3d,hx2),1))hx1d = self.rebnconv1d(torch.cat((hx2d,hx1),1))return hx1d + hxin##### U^2-Net ####
class U2NET(nn.Module):def __init__(self,in_ch=3,out_ch=1):super(U2NET,self).__init__()self.stage1 = RSU7(in_ch,32,64)self.pool12 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.stage2 = RSU6(64,32,128)self.pool23 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.stage3 = RSU5(128,64,256)self.pool34 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.stage4 = RSU4(256,128,512)self.pool45 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.stage5 = RSU4F(512,256,512)self.pool56 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.stage6 = RSU4F(512,256,512)# decoderself.stage5d = RSU4F(1024,256,512)self.stage4d = RSU4(1024,128,256)self.stage3d = RSU5(512,64,128)self.stage2d = RSU6(256,32,64)self.stage1d = RSU7(128,16,64)self.side1 = nn.Conv2d(64,out_ch,3,padding=1)self.side2 = nn.Conv2d(64,out_ch,3,padding=1)self.side3 = nn.Conv2d(128,out_ch,3,padding=1)self.side4 = nn.Conv2d(256,out_ch,3,padding=1)self.side5 = nn.Conv2d(512,out_ch,3,padding=1)self.side6 = nn.Conv2d(512,out_ch,3,padding=1)self.outconv = nn.Conv2d(6,out_ch,1)def forward(self,x):hx = x#stage 1hx1 = self.stage1(hx)hx = self.pool12(hx1)#stage 2hx2 = self.stage2(hx)hx = self.pool23(hx2)#stage 3hx3 = self.stage3(hx)hx = self.pool34(hx3)#stage 4hx4 = self.stage4(hx)hx = self.pool45(hx4)#stage 5hx5 = self.stage5(hx)hx = self.pool56(hx5)#stage 6hx6 = self.stage6(hx)hx6up = _upsample_like(hx6,hx5)#-------------------- decoder --------------------hx5d = self.stage5d(torch.cat((hx6up,hx5),1))hx5dup = _upsample_like(hx5d,hx4)hx4d = self.stage4d(torch.cat((hx5dup,hx4),1))hx4dup = _upsample_like(hx4d,hx3)hx3d = self.stage3d(torch.cat((hx4dup,hx3),1))hx3dup = _upsample_like(hx3d,hx2)hx2d = self.stage2d(torch.cat((hx3dup,hx2),1))hx2dup = _upsample_like(hx2d,hx1)hx1d = self.stage1d(torch.cat((hx2dup,hx1),1))#side outputd1 = self.side1(hx1d)d2 = self.side2(hx2d)d2 = _upsample_like(d2,d1)d3 = self.side3(hx3d)d3 = _upsample_like(d3,d1)d4 = self.side4(hx4d)d4 = _upsample_like(d4,d1)d5 = self.side5(hx5d)d5 = _upsample_like(d5,d1)d6 = self.side6(hx6)d6 = _upsample_like(d6,d1)d0 = self.outconv(torch.cat((d1,d2,d3,d4,d5,d6),1))return torch.sigmoid(d0), torch.sigmoid(d1), torch.sigmoid(d2), torch.sigmoid(d3), torch.sigmoid(d4), torch.sigmoid(d5), torch.sigmoid(d6)### U^2-Net small ###
class U2NETP(nn.Module):def __init__(self,in_ch=3,out_ch=1):super(U2NETP,self).__init__()self.stage1 = RSU7(in_ch,16,64)self.pool12 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.stage2 = RSU6(64,16,64)self.pool23 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.stage3 = RSU5(64,16,64)self.pool34 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.stage4 = RSU4(64,16,64)self.pool45 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.stage5 = RSU4F(64,16,64)self.pool56 = nn.MaxPool2d(2,stride=2,ceil_mode=True)self.stage6 = RSU4F(64,16,64)# decoderself.stage5d = RSU4F(128,16,64)self.stage4d = RSU4(128,16,64)self.stage3d = RSU5(128,16,64)self.stage2d = RSU6(128,16,64)self.stage1d = RSU7(128,16,64)self.side1 = nn.Conv2d(64,out_ch,3,padding=1)self.side2 = nn.Conv2d(64,out_ch,3,padding=1)self.side3 = nn.Conv2d(64,out_ch,3,padding=1)self.side4 = nn.Conv2d(64,out_ch,3,padding=1)self.side5 = nn.Conv2d(64,out_ch,3,padding=1)self.side6 = nn.Conv2d(64,out_ch,3,padding=1)self.outconv = nn.Conv2d(6,out_ch,1)def forward(self,x):hx = x#stage 1hx1 = self.stage1(hx)hx = self.pool12(hx1)#stage 2hx2 = self.stage2(hx)hx = self.pool23(hx2)#stage 3hx3 = self.stage3(hx)hx = self.pool34(hx3)#stage 4hx4 = self.stage4(hx)hx = self.pool45(hx4)#stage 5hx5 = self.stage5(hx)hx = self.pool56(hx5)#stage 6hx6 = self.stage6(hx)hx6up = _upsample_like(hx6,hx5)#decoderhx5d = self.stage5d(torch.cat((hx6up,hx5),1))hx5dup = _upsample_like(hx5d,hx4)hx4d = self.stage4d(torch.cat((hx5dup,hx4),1))hx4dup = _upsample_like(hx4d,hx3)hx3d = self.stage3d(torch.cat((hx4dup,hx3),1))hx3dup = _upsample_like(hx3d,hx2)hx2d = self.stage2d(torch.cat((hx3dup,hx2),1))hx2dup = _upsample_like(hx2d,hx1)hx1d = self.stage1d(torch.cat((hx2dup,hx1),1))#side outputd1 = self.side1(hx1d)d2 = self.side2(hx2d)d2 = _upsample_like(d2,d1)d3 = self.side3(hx3d)d3 = _upsample_like(d3,d1)d4 = self.side4(hx4d)d4 = _upsample_like(d4,d1)d5 = self.side5(hx5d)d5 = _upsample_like(d5,d1)d6 = self.side6(hx6)d6 = _upsample_like(d6,d1)d0 = self.outconv(torch.cat((d1,d2,d3,d4,d5,d6),1))return torch.sigmoid(d0), torch.sigmoid(d1), torch.sigmoid(d2), torch.sigmoid(d3), torch.sigmoid(d4), torch.sigmoid(d5), torch.sigmoid(d6)2、data_loader.py
# data loader
from __future__ import print_function, division
import glob
import torch
from skimage import io, transform, color #scikit-image是基于scipy的一款图像处理包,它将图片作为numpy数组进行处理
import numpy as np
import random
import math
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
from PIL import Image#==========================dataset load==========================
class RescaleT(object): #此处等比缩放原始图像位指定的输出大def __init__(self,output_size):assert isinstance(output_size,(int,tuple))self.output_size = output_size #获得输出的图片的大小def __call__(self,sample):imidx, image, label = sample['imidx'], sample['image'],sample['label'] #获取到图片的索引、图片名和标签h, w = image.shape[:2] #获取图片的形状if isinstance(self.output_size,int):if h > w:new_h, new_w = self.output_size*h/w,self.output_size #根据输出图片的大小重新分配宽和高else:new_h, new_w = self.output_size,self.output_size*w/helse:new_h, new_w = self.output_sizenew_h, new_w = int(new_h), int(new_w)# #resize the image to new_h x new_w and convert image from range [0,255] to [0,1]# img = transform.resize(image,(new_h,new_w),mode='constant')# lbl = transform.resize(label,(new_h,new_w),mode='constant', order=0, preserve_range=True)img = transform.resize(image,(self.output_size,self.output_size),mode='constant') #此处等比缩放原始图像位指定的输出大小lbl = transform.resize(label,(self.output_size,self.output_size),mode='constant', order=0, preserve_range=True) #等比缩放标签图像 #skimage.transform import resizereturn {'imidx':imidx, 'image':img,'label':lbl}class Rescale(object): #重新缩放至指定大小def __init__(self,output_size):assert isinstance(output_size,(int,tuple))self.output_size = output_sizedef __call__(self,sample): #使得类实例对象可以像调用普通函数那样,以“对象名()”的形式使用。imidx, image, label = sample['imidx'], sample['image'],sample['label']if random.random() >= 0.5:image = image[::-1]label = label[::-1]h, w = image.shape[:2]if isinstance(self.output_size,int):if h > w:new_h, new_w = self.output_size*h/w,self.output_sizeelse:new_h, new_w = self.output_size,self.output_size*w/helse:new_h, new_w = self.output_sizenew_h, new_w = int(new_h), int(new_w)# #resize the image to new_h x new_w and convert image from range [0,255] to [0,1]img = transform.resize(image,(new_h,new_w),mode='constant')lbl = transform.resize(label,(new_h,new_w),mode='constant', order=0, preserve_range=True)return {'imidx':imidx, 'image':img,'label':lbl}class RandomCrop(object): #返回经过随机裁剪后的图像和标签,指定输出大小def __init__(self,output_size):assert isinstance(output_size, (int, tuple))if isinstance(output_size, int):self.output_size = (output_size, output_size)else:assert len(output_size) == 2self.output_size = output_sizedef __call__(self,sample):imidx, image, label = sample['imidx'], sample['image'], sample['label']if random.random() >= 0.5:image = image[::-1]label = label[::-1]h, w = image.shape[:2]new_h, new_w = self.output_sizetop = np.random.randint(0, h - new_h)left = np.random.randint(0, w - new_w)image = image[top: top + new_h, left: left + new_w] #对原始的图片进行随机裁label = label[top: top + new_h, left: left + new_w] #对原始标签随机裁剪return {'imidx':imidx,'image':image, 'label':label} #返回经过随机裁剪后的图像和标签class ToTensor(object): #对图像和标签归一化"""Convert ndarrays in sample to Tensors."""def __call__(self, sample):imidx, image, label = sample['imidx'], sample['image'], sample['label']tmpImg = np.zeros((image.shape[0],image.shape[1],3))tmpLbl = np.zeros(label.shape)image = image/np.max(image) #归一化图片if(np.max(label)<1e-6):label = labelelse:label = label/np.max(label)if image.shape[2]==1:tmpImg[:,:,0] = (image[:,:,0]-0.485)/0.229tmpImg[:,:,1] = (image[:,:,0]-0.485)/0.229tmpImg[:,:,2] = (image[:,:,0]-0.485)/0.229else:tmpImg[:,:,0] = (image[:,:,0]-0.485)/0.229tmpImg[:,:,1] = (image[:,:,1]-0.456)/0.224tmpImg[:,:,2] = (image[:,:,2]-0.406)/0.225tmpLbl[:,:,0] = label[:,:,0]# change the r,g,b to b,r,g from [0,255] to [0,1]#transforms.Normalize(mean = (0.485, 0.456, 0.406), std = (0.229, 0.224, 0.225))tmpImg = tmpImg.transpose((2, 0, 1))tmpLbl = label.transpose((2, 0, 1))return {'imidx':torch.from_numpy(imidx), 'image': torch.from_numpy(tmpImg), 'label': torch.from_numpy(tmpLbl)}class ToTensorLab(object):"""Convert ndarrays in sample to Tensors."""def __init__(self,flag=0):self.flag = flagdef __call__(self, sample):imidx, image, label =sample['imidx'], sample['image'], sample['label']tmpLbl = np.zeros(label.shape)if(np.max(label)<1e-6):label = labelelse:label = label/np.max(label)# change the color spaceif self.flag == 2: # with rgb and Lab colorstmpImg = np.zeros((image.shape[0],image.shape[1],6))tmpImgt = np.zeros((image.shape[0],image.shape[1],3))if image.shape[2]==1:tmpImgt[:,:,0] = image[:,:,0]tmpImgt[:,:,1] = image[:,:,0]tmpImgt[:,:,2] = image[:,:,0]else:tmpImgt = imagetmpImgtl = color.rgb2lab(tmpImgt)# nomalize image to range [0,1]tmpImg[:,:,0] = (tmpImgt[:,:,0]-np.min(tmpImgt[:,:,0]))/(np.max(tmpImgt[:,:,0])-np.min(tmpImgt[:,:,0]))tmpImg[:,:,1] = (tmpImgt[:,:,1]-np.min(tmpImgt[:,:,1]))/(np.max(tmpImgt[:,:,1])-np.min(tmpImgt[:,:,1]))tmpImg[:,:,2] = (tmpImgt[:,:,2]-np.min(tmpImgt[:,:,2]))/(np.max(tmpImgt[:,:,2])-np.min(tmpImgt[:,:,2]))tmpImg[:,:,3] = (tmpImgtl[:,:,0]-np.min(tmpImgtl[:,:,0]))/(np.max(tmpImgtl[:,:,0])-np.min(tmpImgtl[:,:,0]))tmpImg[:,:,4] = (tmpImgtl[:,:,1]-np.min(tmpImgtl[:,:,1]))/(np.max(tmpImgtl[:,:,1])-np.min(tmpImgtl[:,:,1]))tmpImg[:,:,5] = (tmpImgtl[:,:,2]-np.min(tmpImgtl[:,:,2]))/(np.max(tmpImgtl[:,:,2])-np.min(tmpImgtl[:,:,2]))# tmpImg = tmpImg/(np.max(tmpImg)-np.min(tmpImg))tmpImg[:,:,0] = (tmpImg[:,:,0]-np.mean(tmpImg[:,:,0]))/np.std(tmpImg[:,:,0])tmpImg[:,:,1] = (tmpImg[:,:,1]-np.mean(tmpImg[:,:,1]))/np.std(tmpImg[:,:,1])tmpImg[:,:,2] = (tmpImg[:,:,2]-np.mean(tmpImg[:,:,2]))/np.std(tmpImg[:,:,2])tmpImg[:,:,3] = (tmpImg[:,:,3]-np.mean(tmpImg[:,:,3]))/np.std(tmpImg[:,:,3])tmpImg[:,:,4] = (tmpImg[:,:,4]-np.mean(tmpImg[:,:,4]))/np.std(tmpImg[:,:,4])tmpImg[:,:,5] = (tmpImg[:,:,5]-np.mean(tmpImg[:,:,5]))/np.std(tmpImg[:,:,5])elif self.flag == 1: #with Lab colortmpImg = np.zeros((image.shape[0],image.shape[1],3))if image.shape[2]==1:tmpImg[:,:,0] = image[:,:,0]tmpImg[:,:,1] = image[:,:,0]tmpImg[:,:,2] = image[:,:,0]else:tmpImg = imagetmpImg = color.rgb2lab(tmpImg)# tmpImg = tmpImg/(np.max(tmpImg)-np.min(tmpImg))tmpImg[:,:,0] = (tmpImg[:,:,0]-np.min(tmpImg[:,:,0]))/(np.max(tmpImg[:,:,0])-np.min(tmpImg[:,:,0]))tmpImg[:,:,1] = (tmpImg[:,:,1]-np.min(tmpImg[:,:,1]))/(np.max(tmpImg[:,:,1])-np.min(tmpImg[:,:,1]))tmpImg[:,:,2] = (tmpImg[:,:,2]-np.min(tmpImg[:,:,2]))/(np.max(tmpImg[:,:,2])-np.min(tmpImg[:,:,2]))tmpImg[:,:,0] = (tmpImg[:,:,0]-np.mean(tmpImg[:,:,0]))/np.std(tmpImg[:,:,0])tmpImg[:,:,1] = (tmpImg[:,:,1]-np.mean(tmpImg[:,:,1]))/np.std(tmpImg[:,:,1])tmpImg[:,:,2] = (tmpImg[:,:,2]-np.mean(tmpImg[:,:,2]))/np.std(tmpImg[:,:,2])else: # with rgb colortmpImg = np.zeros((image.shape[0],image.shape[1],3))image = image/np.max(image)if image.shape[2]==1:tmpImg[:,:,0] = (image[:,:,0]-0.485)/0.229tmpImg[:,:,1] = (image[:,:,0]-0.485)/0.229tmpImg[:,:,2] = (image[:,:,0]-0.485)/0.229else:tmpImg[:,:,0] = (image[:,:,0]-0.485)/0.229tmpImg[:,:,1] = (image[:,:,1]-0.456)/0.224tmpImg[:,:,2] = (image[:,:,2]-0.406)/0.225tmpLbl[:,:,0] = label[:,:,0]# change the r,g,b to b,r,g from [0,255] to [0,1]#transforms.Normalize(mean = (0.485, 0.456, 0.406), std = (0.229, 0.224, 0.225))tmpImg = tmpImg.transpose((2, 0, 1))tmpLbl = label.transpose((2, 0, 1))return {'imidx':torch.from_numpy(imidx), 'image': torch.from_numpy(tmpImg), 'label': torch.from_numpy(tmpLbl)}class SalObjDataset(Dataset): #返回归一化后的图片索引,图片,标签图片def __init__(self,img_name_list,lbl_name_list,transform=None):# self.root_dir = root_dir# self.image_name_list = glob.glob(image_dir+'*.png')# self.label_name_list = glob.glob(label_dir+'*.png')self.image_name_list = img_name_list #获取到所有的图片名绝对路径self.label_name_list = lbl_name_list #获取到所有的标签绝对路径self.transform = transform #transform包括裁剪缩放转tensordef __len__(self):return len(self.image_name_list)def __getitem__(self,idx):# image = Image.open(self.image_name_list[idx])#io.imread(self.image_name_list[idx])# label = Image.open(self.label_name_list[idx])#io.imread(self.label_name_list[idx])image = io.imread(self.image_name_list[idx]) #通过每张的绝对路径读取到每一张图片# print(type(image)) #<class 'numpy.ndarray'> BGR格式的图片# import cv2# cv2.imshow("",cv2.cvtColor(np.uint8(image),cv2.COLOR_BGR2RGB))# cv2.waitKey(0)# cv2.destroyAllWindows()# print(image.shape) #(375, 500, 3)大小不固定,单都是3通道# print("=======================================================")imname = self.image_name_list[idx]imidx = np.array([idx]) #图片的索引转化numpy的数组if(0==len(self.label_name_list)): #如果没有标签则创建一个0标签label_3 = np.zeros(image.shape)else: #如果有标签则获取对应的标签label_3 = io.imread(self.label_name_list[idx])label = np.zeros(label_3.shape[0:2]) #将标签数据用不同维度的0表示if(3==len(label_3.shape)):label = label_3[:,:,0]elif(2==len(label_3.shape)):label = label_3if(3==len(image.shape) and 2==len(label.shape)):label = label[:,:,np.newaxis] #np.newaxis的作用就是在这一位置增加一个一维,这一位置指的是np.newaxis所在的位置elif(2==len(image.shape) and 2==len(label.shape)):image = image[:,:,np.newaxis]label = label[:,:,np.newaxis]sample = {'imidx':imidx, 'image':image, 'label':label}if self.transform:sample = self.transform(sample) #对图像transformreturn sample3、u2net_train.py
import torch
import torchvision
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as Ffrom torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
import torch.optim as optim
import torchvision.transforms as standard_transformsimport numpy as np
import glob
import osfrom my_U2_Net.data_loader import RescaleT,RandomCrop,ToTensorLab,SalObjDataset,ToTensor,Rescale
from my_U2_Net.model import U2NET,U2NETP# ------- 1. define loss function --------bce_loss = nn.BCELoss(reduction='mean')def muti_bce_loss_fusion(d0, d1, d2, d3, d4, d5, d6, labels_v):loss0 = bce_loss(d0,labels_v)loss1 = bce_loss(d1,labels_v)loss2 = bce_loss(d2,labels_v)loss3 = bce_loss(d3,labels_v)loss4 = bce_loss(d4,labels_v)loss5 = bce_loss(d5,labels_v)loss6 = bce_loss(d6,labels_v)loss = loss0 + loss1 + loss2 + loss3 + loss4 + loss5 + loss6 #在网路结构中共有6个sup所以有6个损失函数print("l0: %3f, l1: %3f, l2: %3f, l3: %3f, l4: %3f, l5: %3f, l6: %3f\n"%(loss0.item(),loss1.item(),loss2.item(),loss3.item(),loss4.item(),loss5.item(),loss6.item()))return loss0, lossdef main():# ------- 2. set the directory of training dataset --------model_name = 'u2net' #'u2netp' #选取的网络模型的种类# params_path = os.path.join("../saved_models", model_name,model_name.pth)data_dir = r'F:\PASCAL_VOC\VOCdevkit\VOC2007\my_segmentations' #包含训练图片和分割标签的上一级目录tra_image_dir = 'JPEGImages' #图片所在的目录名tra_label_dir = 'SegmentationClass' #标签所在的目录名image_ext = '.jpg'label_ext = '.png' #标签的后缀名model_dir = './saved_models/' + model_name +'/' #保存的参数模型所在的文件夹名params_path = model_dir +model_name +".pth" #保存的参数参数的相对路径epoch_num = 100000 #训练的总轮次batch_size_train = 2 #训练的批次batch_size_val = 1 #验证的批次train_num = 0val_num = 0# tra_img_name_list = glob.glob(data_dir + "\\" + tra_image_dir + '*')tra_img_name_list = glob.glob(os.path.join(data_dir, tra_image_dir,'*')) #训练的图片所在的路径,glob.glob()将图片的绝对路径保存到一个列表print("hahah")# print(tra_img_name_list) #包含所有训练图片绝对路径的列表# print("-------------------------------------------------------------------------------------------------")tra_lbl_name_list = []for img_path in tra_img_name_list: #遍历每一个图片的绝对路径img_name = img_path.split("\\")[-1] #取出图片的名字,如:003000.jpgaaa = img_name.split(".")bbb = aaa[0:-1] #['000032']# print(bbb)#去除后缀的图片名imidx = bbb[0] #000032# print(imidx) #000032# print(len(bbb)) #1for i in range(1,len(bbb)):print(i)imidx = imidx + "." + bbb[i]print(imidx,"**********")tra_lbl_name_list.append(data_dir+ "\\" + tra_label_dir+ "\\" + imidx + label_ext)print(tra_lbl_name_list) #标签的绝对路径的列表,和训练图片的绝对路径一一对应print("---")print("train images: ", len(tra_img_name_list)) #422print("train labels: ", len(tra_lbl_name_list))print("---")train_num = len(tra_img_name_list) #训练的图片的总数salobj_dataset = SalObjDataset(img_name_list=tra_img_name_list,lbl_name_list=tra_lbl_name_list,transform=transforms.Compose([RescaleT(320),RandomCrop(288),ToTensorLab(flag=0)])) #RescaleT(320)等比缩放为指定的大小,RandomCrop(288)随机裁剪为指定的大小salobj_dataloader = DataLoader(salobj_dataset, batch_size=batch_size_train, shuffle=True, num_workers=1)# ------- 3. define model --------# define the netif(model_name=='u2net'):net = U2NET(3, 1) #指定输入通道核输出通道的大小elif(model_name=='u2netp'): #网络实例化net = U2NETP(3,1)if torch.cuda.is_available():net.cuda() #网络转移至GPUif os.path.exists(params_path): #加载训练好的模型参数net.load_state_dict(torch.load(params_path))else:print("No parameters!")# ------- 4. define optimizer --------print("---define optimizer...")optimizer = optim.Adam(net.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)# ------- 5. training process --------print("---start training...")ite_num = 0running_loss = 0.0running_tar_loss = 0.0ite_num4val = 0save_frq = 2000 #save the model every 2000 iterationsfor epoch in range(0, epoch_num):net.train() #训练模式for i, data in enumerate(salobj_dataloader):ite_num = ite_num + 1ite_num4val = ite_num4val + 1inputs, labels = data['image'], data['label'] #获取图片和标签inputs = inputs.type(torch.FloatTensor) #转为tensor类型labels = labels.type(torch.FloatTensor)# wrap them in Variableif torch.cuda.is_available(): #转移到cudainputs_v, labels_v = Variable(inputs.cuda(), requires_grad=False), Variable(labels.cuda(),requires_grad=False)else:inputs_v, labels_v = Variable(inputs, requires_grad=False), Variable(labels, requires_grad=False)# y zero the parameter gradientsoptimizer.zero_grad() #优化器清空梯度# forward + backward + optimized0, d1, d2, d3, d4, d5, d6 = net(inputs_v) #网络输出loss2, loss = muti_bce_loss_fusion(d0, d1, d2, d3, d4, d5, d6, labels_v) #6个sup作损失loss.backward() #反向求导更新梯度optimizer.step() #下一步# # print statisticsrunning_loss += loss.item() #总损失running_tar_loss += loss2.item()# delete temporary outputs and lossdel d0, d1, d2, d3, d4, d5, d6, loss2, lossprint("[epoch: %3d/%3d, batch: %5d/%5d, ite: %d] train loss: %3f, tar: %3f " % (epoch + 1, epoch_num, (i + 1) * batch_size_train, train_num, ite_num, running_loss / ite_num4val, running_tar_loss / ite_num4val))if ite_num % save_frq == 0:# torch.save(net.state_dict(), model_dir + model_name+"_bce_itr_%d_train_%3f_tar_%3f.pth" % (ite_num, running_loss / ite_num4val, running_tar_loss / ite_num4val))running_loss = 0.0running_tar_loss = 0.0net.train() # resume trainite_num4val = 0# torch.save(net.state_dict(), model_dir + model_name+"_bce_itr_%d_train_%3f_tar_%3f.pth" % (ite_num, running_loss / ite_num4val, running_tar_loss / ite_num4val))torch.save(net.state_dict(),params_path)
if __name__ == "__main__":main()4、u2net_test.py
import os
from skimage import io, transform
import torch
import torchvision
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms#, utils
# import torch.optim as optimimport numpy as np
from PIL import Image
import globfrom my_U2_Net.data_loader import RescaleT
from my_U2_Net.data_loader import ToTensor
from my_U2_Net.data_loader import ToTensorLab
from my_U2_Net.data_loader import SalObjDataset #加载数据用(返回图片的索引,归一化后的图片,标签)from my_U2_Net.model import U2NET # full size version 173.6 MB #导入两个网络
from my_U2_Net.model import U2NETP # small version u2net 4.7 MB# normalize the predicted SOD probability map
def normPRED(d): #归一化ma = torch.max(d)mi = torch.min(d)dn = (d-mi)/(ma-mi)return dndef save_output(image_name,pred,d_dir):predict = pred.squeeze() #删除单维度predict_np = predict.cpu().data.numpy() #转移到CPU上im = Image.fromarray(predict_np*255).convert('RGB') #转为PIL,从归一化的图片恢复到正常0到255之间img_name = image_name.split("\\")[-1] #取出后缀类型# print(image_name)# print(img_name)image = io.imread(image_name) #io.imread读出图片格式是uint8(unsigned int);value是numpy array;图像数据是以RGB的格式进行存储的,通道值默认范围0-255imo = im.resize((image.shape[1],image.shape[0]),resample=Image.BILINEAR)# pb_np = np.array(imo) #多余的aaa = img_name.split(".") #图片名字被切分为一个列表bbb = aaa[0:-1] #取出图片名称的前缀# print(aaa) #['5', 'jpg']# print(bbb) #['5']# print("---------------------------------------------")imidx = bbb[0]for i in range(1,len(bbb)):imidx = imidx + "." + bbb[i]imo.save(d_dir+imidx+'.png') #保存图片到指定路径def main():# --------- 1. get image path and name ---------model_name='u2net'#u2netp #保存的模型的名称image_dir = './test_data/test_images/' #将要预测的图片所在的文件夹路径prediction_dir = './test_data/' + model_name + '_results/'#预测结果的保存的文件夹路径# model_dir = '../saved_models/'+ model_name + '/' + model_name + '.pth'# model_dir = r"../saved_models/u2net/u2net_bce_itr_422_train_3.743319_tar_0.546805.pth"model_dir = "\my_U2_Net\saved_models\u2net\u2net.pth" #模型参数的路径img_name_list = glob.glob(image_dir + '*') #图片文件夹下的所有数据(携带路径)print(img_name_list)# --------- 2. dataloader ---------#1. dataloadertest_salobj_dataset = SalObjDataset(img_name_list=img_name_list,lbl_name_list=[],transform=transforms.Compose([RescaleT(320),ToTensorLab(flag=0)]))test_salobj_dataloader = DataLoader(test_salobj_dataset,batch_size=1,shuffle=False,num_workers=1) #加载数据# --------- 3. model define ---------if(model_name=='u2net'): #分辨使用的是哪一个模型参数print("...load U2NET---173.6 MB")net = U2NET(3,1)elif(model_name=='u2netp'):print("...load U2NEP---4.7 MB")net = U2NETP(3,1)net.load_state_dict(torch.load(model_dir)) #加载训练好的模型if torch.cuda.is_available():net.cuda() #网络转移至GPUnet.eval() #测评模式# --------- 4. inference for each image ---------for i_test, data_test in enumerate(test_salobj_dataloader):print("inferencing:",img_name_list[i_test].split("/")[-1]) #test_images\5.jpg# print(data_test) #'imidx': tensor([[0]], dtype=torch.int32), 'image': tensor([[[[ 1.4051, ...'label': tensor([[[[0., 0., 0., ...,inputs_test = data_test['image'] #测试的是图片inputs_test = inputs_test.type(torch.FloatTensor) #转为浮点型if torch.cuda.is_available():inputs_test = Variable(inputs_test.cuda())#Variable是对Tensor的一个封装,操作和Tensor是一样的,但是每个Variable都有三个属性,# tensor不能反向传播,variable可以反向传播。它会逐渐地生成计算图。# 这个图就是将所有的计算节点都连接起来,最后进行误差反向传递的时候,# 一次性将所有Variable里面的梯度都计算出来,而tensor就没有这个能力else:inputs_test = Variable(inputs_test)d1,d2,d3,d4,d5,d6,d7 = net(inputs_test) #将图片传入网络# normalizationpred = d1[:,0,:,:]pred = normPRED(pred) #对预测的结果做归一化# save results to test_results foldersave_output(img_name_list[i_test],pred,prediction_dir) #原始图片名、预测结果,预测图片的保存目录 #save_output保存预测的输出值del d1,d2,d3,d4,d5,d6,d7 #del 用于删除对象。在 Python,一切都是对象,因此 del 关键字可用于删除变量、列表或列表片段等。if __name__ == "__main__":main()注:本次训练使用的是VOC2007的数据进行训练的,加载了预训练模型
输出结果为:
原图

得到掩码图:

提取目标:
crop.py
# -*- coding: utf-8 -*-import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import osdef crop(img_file, mask_file):name, *_ = img_file.split(".") #将后缀划分开img_array = np.array(Image.open(img_file)) #真实图片的PIL转到numpy类型mask = np.array(Image.open(mask_file)) #打开掩码图片res = np.concatenate((img_array, mask[:, :, [0]]), -1) #将原图和掩码进行数组拼接img = Image.fromarray(res.astype('uint8'), mode='RGBA') #数组转为PIL格式img.show()return imgif __name__ == "__main__":model = "u2net"# model = "u2netp"img_root = "test_data/test_images" #真实图片的保存路径mask_root = "test_data/{}_results".format(model) #掩码的根目录crop_root = "test_data/{}_crops".format(model) #裁剪图片的保存的目录os.makedirs(crop_root, mode=0o775, exist_ok=True) #创建保存图片的路径# name:想要创建的目录名,modemode:要为目录设置的权限数字模式,# 默认的模式为 0o777 (八进制)。exist_ok:是否在目录存在时触发异常。# 如果exist_ok为False(默认值),则在目标目录已存在的情况下触发FileExistsError异常;# 如果exist_ok为True,则在目标目录已存在的情况下不会触发FileExistsError异常。for img_file in os.listdir(img_root): #遍历所有的源图片print("crop image {}".format(img_file))name, *_ = img_file.split(".") #划分出图片的名字和后缀res = crop(img_file=os.path.join(img_root, img_file),mask_file=os.path.join(mask_root, name + ".png")) #调用自定义的crop()函数res.save(os.path.join(crop_root, name + "_crop.png")) #保存图片的到指定的保存路径得到图片如下:

5、video_for_video.py
为了实现视频分割,整合了上边的几个文件,由于本代码还未进行优化。。。但勉强测试下视频分割还是可以的,后续必要是再进行优化。
# data loader
from __future__ import print_function, division
import glob
import torch
from skimage import io, transform, color #scikit-image是基于scipy的一款图像处理包,它将图片作为numpy数组进行处理
import numpy as np
import random
import math
import matplotlib.pyplot as pltfrom torchvision import transforms, utils
from PIL import Image
import os
from skimage import io, transform
import torch
import torchvision
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms#, utils
# import torch.optim as optim
import glob
from my_U2_Net.model import U2NET,U2NETP #导入两个网络
import cv2capture = cv2.VideoCapture(0)
class RescaleT(object): #此处等比缩放原始图像位指定的输出大def __init__(self,output_size):assert isinstance(output_size,(int,tuple))self.output_size = output_size #获得输出的图片的大小def __call__(self,sample):imidx, image, label,frame = sample['imidx'], sample['image'],sample['label'],sample['frame'] #获取到图片的索引、图片名和标签h, w = image.shape[:2] #获取图片的形状if isinstance(self.output_size,int):if h > w:new_h, new_w = self.output_size*h/w,self.output_size #根据输出图片的大小重新分配宽和高else:new_h, new_w = self.output_size,self.output_size*w/helse:new_h, new_w = self.output_sizenew_h, new_w = int(new_h), int(new_w)# #resize the image to new_h x new_w and convert image from range [0,255] to [0,1]# img = transform.resize(image,(new_h,new_w),mode='constant')# lbl = transform.resize(label,(new_h,new_w),mode='constant', order=0, preserve_range=True)img = transform.resize(image,(self.output_size,self.output_size),mode='constant') #此处等比缩放原始图像位指定的输出大小lbl = transform.resize(label,(self.output_size,self.output_size),mode='constant', order=0, preserve_range=True) #等比缩放标签图像 #skimage.transform import resizereturn {'imidx':imidx, 'image':img,'label':lbl,"frame":frame}class Rescale(object): #重新缩放至指定大小def __init__(self,output_size):assert isinstance(output_size,(int,tuple))self.output_size = output_sizedef __call__(self,sample): #使得类实例对象可以像调用普通函数那样,以“对象名()”的形式使用。imidx, image, label,frame = sample['imidx'], sample['image'],sample['label'],sample['frame']if random.random() >= 0.5:image = image[::-1]label = label[::-1]h, w = image.shape[:2]if isinstance(self.output_size,int):if h > w:new_h, new_w = self.output_size*h/w,self.output_sizeelse:new_h, new_w = self.output_size,self.output_size*w/helse:new_h, new_w = self.output_sizenew_h, new_w = int(new_h), int(new_w)# #resize the image to new_h x new_w and convert image from range [0,255] to [0,1]img = transform.resize(image,(new_h,new_w),mode='constant')lbl = transform.resize(label,(new_h,new_w),mode='constant', order=0, preserve_range=True)return {'imidx':imidx, 'image':img,'label':lbl,"frame":frame}class RandomCrop(object): #返回经过随机裁剪后的图像和标签,指定输出大小def __init__(self,output_size):assert isinstance(output_size, (int, tuple))if isinstance(output_size, int):self.output_size = (output_size, output_size)else:assert len(output_size) == 2self.output_size = output_sizedef __call__(self,sample):imidx, image, label = sample['imidx'], sample['image'], sample['label']if random.random() >= 0.5:image = image[::-1]label = label[::-1]h, w = image.shape[:2]new_h, new_w = self.output_sizetop = np.random.randint(0, h - new_h)left = np.random.randint(0, w - new_w)image = image[top: top + new_h, left: left + new_w] #对原始的图片进行随机裁label = label[top: top + new_h, left: left + new_w] #对原始标签随机裁剪return {'imidx':imidx,'image':image, 'label':label} #返回经过随机裁剪后的图像和标签class ToTensor(object): #对图像和标签归一化"""Convert ndarrays in sample to Tensors."""def __call__(self, sample):imidx, image, label = sample['imidx'], sample['image'], sample['label']tmpImg = np.zeros((image.shape[0],image.shape[1],3))tmpLbl = np.zeros(label.shape)image = image/np.max(image) #归一化图片if(np.max(label)<1e-6):label = labelelse:label = label/np.max(label)if image.shape[2]==1:tmpImg[:,:,0] = (image[:,:,0]-0.485)/0.229tmpImg[:,:,1] = (image[:,:,0]-0.485)/0.229tmpImg[:,:,2] = (image[:,:,0]-0.485)/0.229else:tmpImg[:,:,0] = (image[:,:,0]-0.485)/0.229tmpImg[:,:,1] = (image[:,:,1]-0.456)/0.224tmpImg[:,:,2] = (image[:,:,2]-0.406)/0.225tmpLbl[:,:,0] = label[:,:,0]# change the r,g,b to b,r,g from [0,255] to [0,1]#transforms.Normalize(mean = (0.485, 0.456, 0.406), std = (0.229, 0.224, 0.225))tmpImg = tmpImg.transpose((2, 0, 1))tmpLbl = label.transpose((2, 0, 1))return {'imidx':torch.from_numpy(imidx), 'image': torch.from_numpy(tmpImg), 'label': torch.from_numpy(tmpLbl)}class ToTensorLab(object):"""Convert ndarrays in sample to Tensors."""def __init__(self,flag=0):self.flag = flagdef __call__(self, sample):imidx, image, label,frame =sample['imidx'], sample['image'], sample['label'], sample['frame']tmpLbl = np.zeros(label.shape)if(np.max(label)<1e-6):label = labelelse:label = label/np.max(label)# change the color spaceif self.flag == 2: # with rgb and Lab colorstmpImg = np.zeros((image.shape[0],image.shape[1],6))tmpImgt = np.zeros((image.shape[0],image.shape[1],3))if image.shape[2]==1:tmpImgt[:,:,0] = image[:,:,0]tmpImgt[:,:,1] = image[:,:,0]tmpImgt[:,:,2] = image[:,:,0]else:tmpImgt = imagetmpImgtl = color.rgb2lab(tmpImgt)# nomalize image to range [0,1]tmpImg[:,:,0] = (tmpImgt[:,:,0]-np.min(tmpImgt[:,:,0]))/(np.max(tmpImgt[:,:,0])-np.min(tmpImgt[:,:,0]))tmpImg[:,:,1] = (tmpImgt[:,:,1]-np.min(tmpImgt[:,:,1]))/(np.max(tmpImgt[:,:,1])-np.min(tmpImgt[:,:,1]))tmpImg[:,:,2] = (tmpImgt[:,:,2]-np.min(tmpImgt[:,:,2]))/(np.max(tmpImgt[:,:,2])-np.min(tmpImgt[:,:,2]))tmpImg[:,:,3] = (tmpImgtl[:,:,0]-np.min(tmpImgtl[:,:,0]))/(np.max(tmpImgtl[:,:,0])-np.min(tmpImgtl[:,:,0]))tmpImg[:,:,4] = (tmpImgtl[:,:,1]-np.min(tmpImgtl[:,:,1]))/(np.max(tmpImgtl[:,:,1])-np.min(tmpImgtl[:,:,1]))tmpImg[:,:,5] = (tmpImgtl[:,:,2]-np.min(tmpImgtl[:,:,2]))/(np.max(tmpImgtl[:,:,2])-np.min(tmpImgtl[:,:,2]))# tmpImg = tmpImg/(np.max(tmpImg)-np.min(tmpImg))tmpImg[:,:,0] = (tmpImg[:,:,0]-np.mean(tmpImg[:,:,0]))/np.std(tmpImg[:,:,0])tmpImg[:,:,1] = (tmpImg[:,:,1]-np.mean(tmpImg[:,:,1]))/np.std(tmpImg[:,:,1])tmpImg[:,:,2] = (tmpImg[:,:,2]-np.mean(tmpImg[:,:,2]))/np.std(tmpImg[:,:,2])tmpImg[:,:,3] = (tmpImg[:,:,3]-np.mean(tmpImg[:,:,3]))/np.std(tmpImg[:,:,3])tmpImg[:,:,4] = (tmpImg[:,:,4]-np.mean(tmpImg[:,:,4]))/np.std(tmpImg[:,:,4])tmpImg[:,:,5] = (tmpImg[:,:,5]-np.mean(tmpImg[:,:,5]))/np.std(tmpImg[:,:,5])elif self.flag == 1: #with Lab colortmpImg = np.zeros((image.shape[0],image.shape[1],3))if image.shape[2]==1:tmpImg[:,:,0] = image[:,:,0]tmpImg[:,:,1] = image[:,:,0]tmpImg[:,:,2] = image[:,:,0]else:tmpImg = imagetmpImg = color.rgb2lab(tmpImg)# tmpImg = tmpImg/(np.max(tmpImg)-np.min(tmpImg))tmpImg[:,:,0] = (tmpImg[:,:,0]-np.min(tmpImg[:,:,0]))/(np.max(tmpImg[:,:,0])-np.min(tmpImg[:,:,0]))tmpImg[:,:,1] = (tmpImg[:,:,1]-np.min(tmpImg[:,:,1]))/(np.max(tmpImg[:,:,1])-np.min(tmpImg[:,:,1]))tmpImg[:,:,2] = (tmpImg[:,:,2]-np.min(tmpImg[:,:,2]))/(np.max(tmpImg[:,:,2])-np.min(tmpImg[:,:,2]))tmpImg[:,:,0] = (tmpImg[:,:,0]-np.mean(tmpImg[:,:,0]))/np.std(tmpImg[:,:,0])tmpImg[:,:,1] = (tmpImg[:,:,1]-np.mean(tmpImg[:,:,1]))/np.std(tmpImg[:,:,1])tmpImg[:,:,2] = (tmpImg[:,:,2]-np.mean(tmpImg[:,:,2]))/np.std(tmpImg[:,:,2])else: # with rgb colortmpImg = np.zeros((image.shape[0],image.shape[1],3))image = image/np.max(image)if image.shape[2]==1:tmpImg[:,:,0] = (image[:,:,0]-0.485)/0.229tmpImg[:,:,1] = (image[:,:,0]-0.485)/0.229tmpImg[:,:,2] = (image[:,:,0]-0.485)/0.229else:tmpImg[:,:,0] = (image[:,:,0]-0.485)/0.229tmpImg[:,:,1] = (image[:,:,1]-0.456)/0.224tmpImg[:,:,2] = (image[:,:,2]-0.406)/0.225tmpLbl[:,:,0] = label[:,:,0]# change the r,g,b to b,r,g from [0,255] to [0,1]#transforms.Normalize(mean = (0.485, 0.456, 0.406), std = (0.229, 0.224, 0.225))tmpImg = tmpImg.transpose((2, 0, 1))tmpLbl = label.transpose((2, 0, 1))return {'imidx':torch.from_numpy(imidx), 'image': torch.from_numpy(tmpImg), 'label': torch.from_numpy(tmpLbl),"frame":frame}class SalObjDataset(Dataset): #返回归一化后的图片索引,图片,标签图片def __init__(self,img_name_list,lbl_name_list,transform=None):# self.root_dir = root_dir# self.image_name_list = glob.glob(image_dir+'*.png')# self.label_name_list = glob.glob(label_dir+'*.png')self.image_name_list = img_name_list #获取到所有的图片名绝对路径self.label_name_list = lbl_name_list #获取到所有的标签绝对路径self.transform = transform #transform包括裁剪缩放转tensordef __len__(self):return len(self.image_name_list)def __getitem__(self,idx):# image = Image.open(self.image_name_list[idx])#io.imread(self.image_name_list[idx])# label = Image.open(self.label_name_list[idx])#io.imread(self.label_name_list[idx])# image = io.imread(self.image_name_list[idx]) #通过每张的绝对路径读取到每一张图片# print(type(image)) #<class 'numpy.ndarray'>while True:ref, frame = capture.read() # 读取某一帧image = frame# image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 格式转变,BGRtoRGBprint(image.shape) #(480, 640, 3)print("=======================================================")# imname = self.image_name_list[idx]imidx = np.array([idx]) #图片的索引转化numpy的数组if(0==len(self.label_name_list)): #如果没有标签则创建一个0标签label_3 = np.zeros(image.shape)else: #如果有标签则获取对应的标签label_3 = io.imread(self.label_name_list[idx])label = np.zeros(label_3.shape[0:2]) #将标签数据用不同维度的0表示if(3==len(label_3.shape)):label = label_3[:,:,0]elif(2==len(label_3.shape)):label = label_3if(3==len(image.shape) and 2==len(label.shape)):label = label[:,:,np.newaxis] #np.newaxis的作用就是在这一位置增加一个一维,这一位置指的是np.newaxis所在的位置elif(2==len(image.shape) and 2==len(label.shape)):image = image[:,:,np.newaxis]label = label[:,:,np.newaxis]sample = {'imidx':imidx, 'image':image, 'label':label,"frame":frame}if self.transform:sample = self.transform(sample) #对图像transformreturn sampledef main():model_name = 'u2net'#u2netp #保存的模型的名称model_dir = r"\my_U2_Net\saved_models\u2net\u2net.pth" #模型参数的路径img_name_list = [i for i in range(10000)]test_salobj_dataset = SalObjDataset(img_name_list=img_name_list,lbl_name_list=[],transform=transforms.Compose([RescaleT(320),ToTensorLab(flag=0)]))test_salobj_dataloader = DataLoader(test_salobj_dataset,batch_size=1,shuffle=False,num_workers=1) #加载数据if(model_name=='u2net'): #分辨使用的是哪一个模型参数print("...load U2NET---173.6 MB")net = U2NET(3,1)elif(model_name=='u2netp'):print("...load U2NEP---4.7 MB")net = U2NETP(3,1)net.load_state_dict(torch.load(model_dir)) #加载训练好的模型if torch.cuda.is_available():net.cuda() #网络转移至GPUnet.eval() #测评模式for i_test, data_test in enumerate(test_salobj_dataloader):inputs_test = data_test['image'] #测试的是图片inputs_test = inputs_test.type(torch.FloatTensor) #转为浮点型if torch.cuda.is_available():inputs_test = Variable(inputs_test.cuda())#Variable是对Tensor的一个封装,操作和Tensor是一样的,但是每个Variable都有三个属性,# tensor不能反向传播,variable可以反向传播。它会逐渐地生成计算图。# 这个图就是将所有的计算节点都连接起来,最后进行误差反向传递的时候,# 一次性将所有Variable里面的梯度都计算出来,而tensor就没有这个能力else:inputs_test = Variable(inputs_test)d1,d2,d3,d4,d5,d6,d7 = net(inputs_test) #将图片传入网络pred = d1[:,0,:,:]pred = (pred-torch.min(pred))/(torch.max(pred)-torch.min(pred)) #对预测的结果做归一化predict = pred.squeeze() # 删除单维度predict_np = predict.cpu().data.numpy() # 转移到CPU上im = Image.fromarray(predict_np * 255).convert('RGB') # 转为PIL,从归一化的图片恢复到正常0到255之间imo = im.resize((640, 480), resample=Image.BILINEAR) # 得到的掩码!!!!!!!!# img_array = np.asarray(Image.fromarray(np.uint8(data_test['image'])))img_array = np.uint8(data_test["frame"][0])# print(data_test)# print(data_test["frame"][0])# print(data_test["frame"][0].shape)# cv2.imshow("", np.uint8(data_test["frame"][0]))# cv2.waitKey(0)# cv2.destroyAllWindows()mask = np.asarray(Image.fromarray(np.uint8(imo)))# cv2.imshow("", np.uint8(mask))# cv2.waitKey(0)# cv2.destroyAllWindows()# print(img_array.shape)# print("ccccccccccccccccccc")# res = np.concatenate((img_array, mask[:, :, [0]]), -1) # 将原图和掩码进行数组拼接# img = cv2.cvtColor(res, cv2.COLOR_RGB2BGRA)# img = Image.fromarray(img.astype('uint8'), mode='RGBA')# img.show()# b, g, r, a = cv2.split(img)# img = cv2.merge([a,r,b,g,])img = Image.fromarray(np.uint8(img_array * (mask / 255)))cv2.imshow("",np.uint8(img))if cv2.waitKey(1) & 0xFF == ord('q'): breakdel d1,d2,d3,d4,d5,d6,d7 #del 用于删除对象。在 Python,一切都是对象,因此 del 关键字可用于删除变量、列表或列表片段等。if __name__ == "__main__":main() #调用展示效果如下(原本是视频版此处只放效果张图):
如图为展示桌面键盘,背景已经被分离了

参考资料:
https://arxiv.org/pdf/2005.09007.pdf
https://github.com/NathanUA/U-2-Net
https://zhuanlan.zhihu.com/p/44958351
这篇关于u2net实现视频图像分割(从原理到实践)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







