本文主要是介绍上市公司高管断裂带数据-ASWFLS-附计算代码和文献,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、数据来源:附在文件中
2、时间跨度:2012-2019年
3、区域范围:全国
4、指标说明:
详细指标说明、计算文献以及代码附在分享文件中
计算参考文献:
[1]Meyer, B., Glenz, & A. (2013). Team faultline measures: a computational comparison and a new approach to multiple subgroups. ORGANIZATIONAL RESEARCH METHODS.
[2]Shaw JB. The Development and Analysis of a Measure of Group Faultlines. Organizational Research Methods. 2004;7(1):66-100. doi:10.1177/1094428103259562
1) 参照Meyer等(2013)计算ASW指标: 该方法采用聚类的方式对群体分类,并从组内相似性和组间差异性角度出发进行分类该算法取值范围介于-1~1之间。2) 参照Shaw等(2004)计算FLS指标:; IA 为分类属性的组内相似度,1 - GGAI 为组间差异性。
部分数据如下:
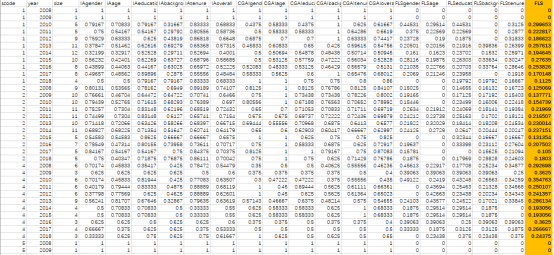
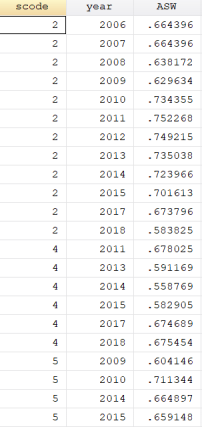
相关研究:
[1]吴文锋, 吴冲锋, 芮萌. 中国上市公司高管的政府背景与税收优惠[J]. 管理世界, 2009, 000(003):134-142.
[2]郝颖, 刘星, 林朝南. 我国上市公司高管人员过度自信与投资决策的实证研究[J]. 中国管理科学, 2005, V(5):142-148.
[3]吴文锋, 吴冲锋, 刘晓薇. 中国民营上市公司高管的政府背景与公司价值[J]. 经济研究, 2008(07):130-141.
[4]朱红军. 我国上市公司高管人员更换的现状分析[J]. 管理世界, 2002(5):126-131.
download链接:上市公司高管断裂带数据集.zip-数据集文档类资源-CSDN下载
这篇关于上市公司高管断裂带数据-ASWFLS-附计算代码和文献的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








