本文主要是介绍EfficientNet 系列网络学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
EfficientNet V1
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- 增加网络参数的方式有三种:深度、宽度和输入图像的分辨率。探究这三种方式对网络性能的影响,以及如何同时缩放这三种因素是
EifficentNet的主要贡献。

- 单独增加某一指标,性能上升有上限

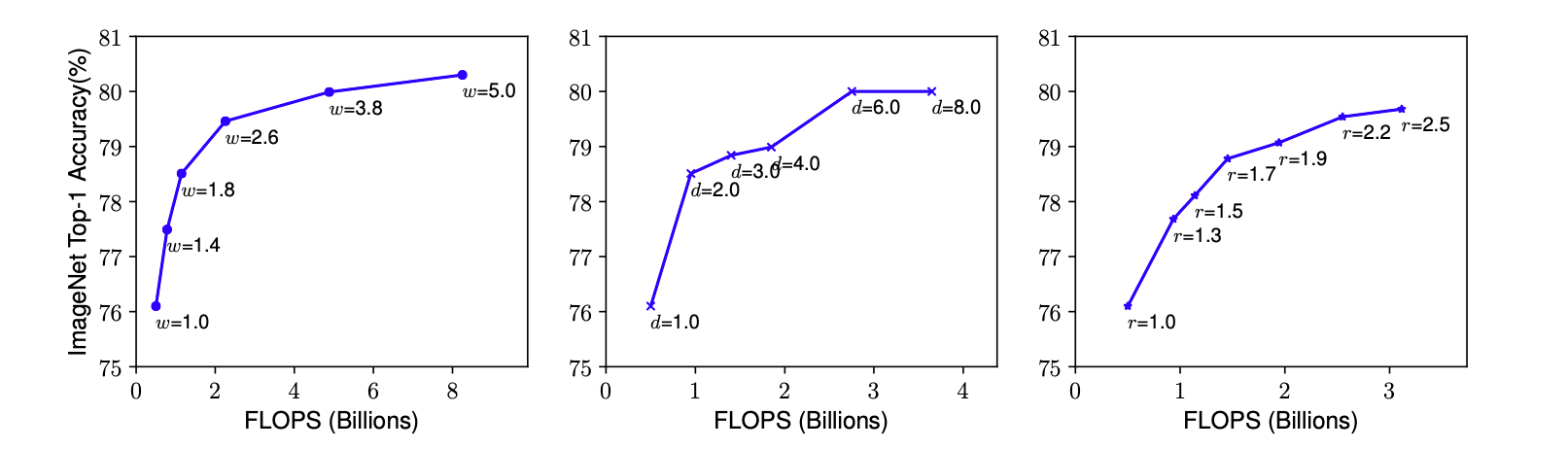

- 网络结构
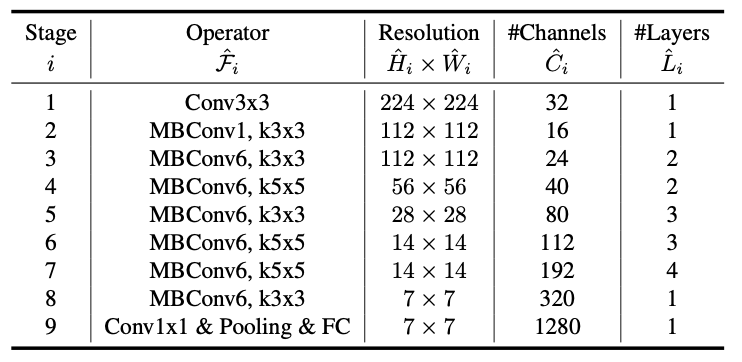
- 结果

EfficientNet V2
EfficientNetV2: Smaller Models and Faster Training
-
V1 问题
- 大图像尺寸会占用内存
- 逐层卷积不能完全利用加速器
- 整个模型缩放比例固定,导致缩放策略不是最优
-
引入改进的渐进式学习的策略:在训练过程中,随训练时间动态的调整输入图片的尺寸,来尽可能充分的使用训练数据集。但是现有的渐进式学习研究,只改了输入,并没有修改模型的正则化参数,作者认为,这是导致模型Accuracy 下降的一个原因。更大的模型应该需要更严格的正则化来避免过拟合,例如EficientNet-B7就需要设置更大的dropout值以及更强的数据增强方式。所以这篇论文认为随着训练轮数的迭代,输入模型的图像尺寸应该逐渐变大,同时实验配置的正则化参数也随之增大,包括三个参数,dropout的概率、随机擦除样本的行数、两种图片混合的比例(后两个是图像增强的手段),也就是数据增强的幅度在逐渐增大,来提升模型正则的要求。
-
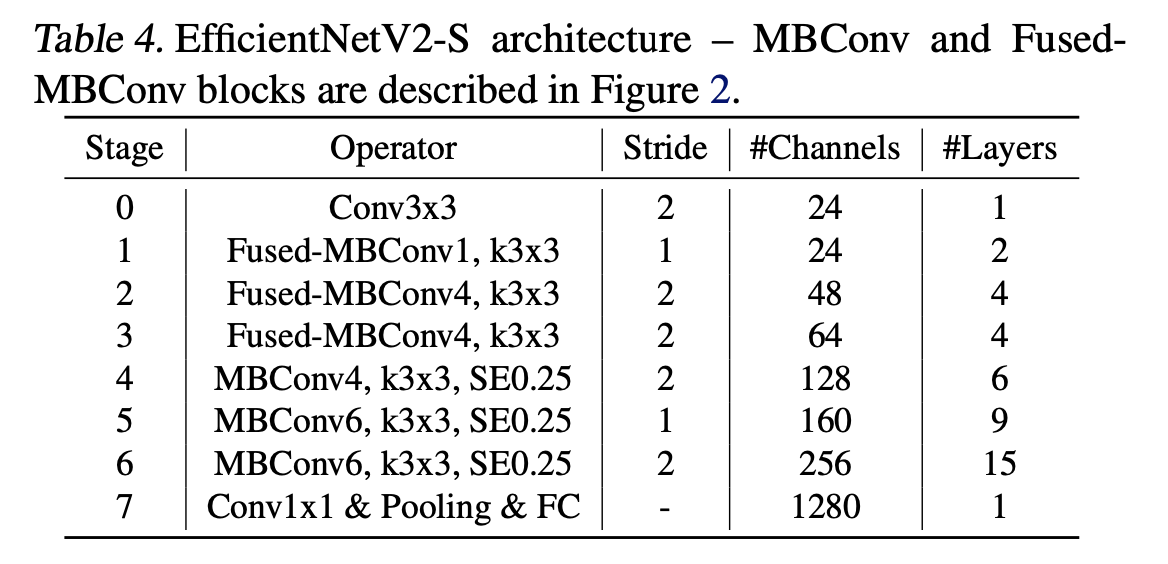
优化的 NAS 神经网络结构搜索

这篇关于EfficientNet 系列网络学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







