本文主要是介绍THUCNews学习(CNN模型),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
THUCNews
文章目录
- THUCNews
- 0、概述
- 1、项目目标
- 2、数据说明
- 3、数据预处理
- 3.1 获得词汇表
- 3.2 句子向量化
- 4、建模过程
- 4.1 embedding
- 4.2 CNN
- 4.2.1 卷积层
- 4.2.2 池化层
- 4.2.3 全连接层
- 5、结论
- 5.1 结构显示
- 5.2 结果显示
- 6、自我改进
- 6.1 改进的内容
- 6.2 思维导图
- 6.3 结果展示
- 6.4 后续调整
0、概述
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。由于担心数据量太过庞大,故减少训练数目。本文利用CNN对文本数据进行分类。
1、项目目标
根据数据集对文本数据进行分类,学习整个文本分类流程,熟悉TensorFlow框架,利用深度学习做一些实际工程,与实际接轨。
2、数据说明
类别如下:
体育, 财经, 房产, 家居, 教育, 科技, 时尚, 时政, 游戏, 娱乐
数据集划分如下:
- 训练集: 5000*10
- 验证集: 500*10
- 测试集: 1000*10
由于数据存在有序排列在最后运行前需要将数据完全打乱。在放入模型中训练,优点在于提升泛化性并且节省时间(要不就先讲数据打乱再热编码,或者热编码后就不变直接打乱)
:~~==*高亮部分表示提升模型的猜想*==~~3、数据预处理
3.1 获得词汇表
此处构建词汇表是统计了包括训练集、验证集和测试集在内的所有文本数据当中出现频率最高的5000个词(不知道选择5000以上的词汇表结果是否更优),当然也包括了标点符号(不知道去除标点符号结果会不会提高)。在词汇表的表头第0个位置放着《pad》表示低频词汇(可以理解为补0)
from collections import Counter# 定义词汇表
def getVocabularyText(content_list, size):size = size - 1allContent = ''.join(content_list)#将内容列表中的所有文章合并起来变成字符串str形式counter = Counter(allContent)#将Counter对象实例化并传入字符串形式的内容vocabulary = []vocabulary.append('<PAD>')for i in counter.most_common(size):vocabulary.append(i[0])with open('vocabulary.txt', 'w', encoding='utf8') as file:for vocab in vocabulary:file.write(vocab + '\n')#读取数据
with open('E:/cnews/cnews.train.txt', encoding='utf8') as file:line_list = [k.strip() for k in file.readlines()]#读取每行train_label_list = [k.split()[0] for k in line_list]#将标签依次取出train_content_list = [k.split(maxsplit=1)[1] for k in line_list]#将内容依次取出,此处注意split()选择最大分割次数为1,否则句子被打断.
with open('E://cnews/cnews.test.txt', encoding='utf8') as file:line_list = [k.strip() for k in file.readlines()]test_label_list = [k.split()[0] for k in line_list]test_content_list = [k.split(maxsplit=1)[1] for k in line_list]
with open('E://cnews/cnews.val.txt', encoding='utf8') as file:line_list = [k.strip() for k in file.readlines()]val_label_list = [k.split()[0] for k in line_list]val_content_list = [k.split(maxsplit=1)[1] for k in line_list]
# 获得词汇表
content_list=train_content_list+test_content_list+val_content_list
getVocabularyText(content_list, 5000)
3.2 句子向量化
由于一个基于整篇文本单词的向量维度十分大,在构造句子向量的时候就不会选择单词的向量拼接,而是选择单词对应词汇表的id(行号)拼接,这样可以有效避开了句子向量所造成的空间开销巨大问题。
vocab_size = 5000 # 词汇表达小
seq_length = 600 # 句子序列长度
num_classes = 10 # 类别数
一个句子的向量长度就是词的总数词向量的维度了。这样一乘发现维度就特别大,而且每个句子的长度不一,对于CNN, 输入与输出都是固定的,所以句子有长有短就没法按训练样本来训练了。所以规定,就是每个句子长度为seq_length(这个序列长度越大训练越慢,但是可能准确率会更好一些?)。如果句子长度不够就补0(有池化层所有补0对于结果没有任何影响),如果句子长度太长的话就去掉多余的部分。
利用kera进行规范
import tensorflow.contrib.keras as kr
train_X = kr.preprocessing.sequence.pad_sequences(train_vector_list,600)
test_X = kr.preprocessing.sequence.pad_sequences(test_vector_list,600)
- kera中的pad_sequences是从右往左数,够600截断,不够的补0.
4、建模过程
本次项目暂时选用的模型为embedding+CNN的神经网络模型。
大致结构如下:
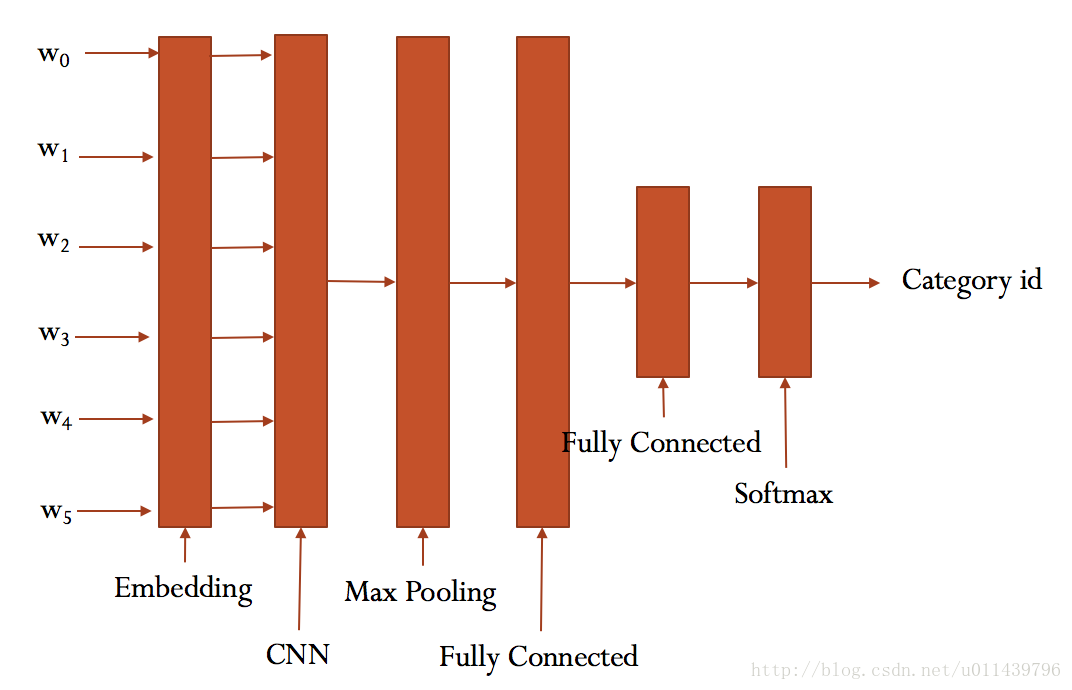
embedding_dim = 128 # 词向量维度
num_filters = 256 # 卷积核数目
kernel_size = 8 # 卷积核尺寸
hidden_dim = 128 # 全连接层神经元
dropout_keep_prob = 0.8 # dropout保留比例
learning_rate = 1e-3 # 学习率
batch_size = 64 # 每批训练大小
4.1 embedding
word embedding(词嵌入):由于one-hot 编码的向量会过于稀疏,这样的稀疏向量表达一个词效率并不高。为了解决这个问题,利用embeding层通过训练,将每个词都映射到一个较短的词向量上(这样就解决了每个词向量的维度过大问题),所有的词向量构成了词汇表的每个词。
词汇表有5000个,词向量维度设定为128(一般即为128或者300)
流程:
-
输入层:
为词汇表中某一个词,采用one-hot编码 长度为1X5000
-
隐藏层:
从输入层到隐藏层的权重矩阵W_v*n就是5000行128列的矩阵,其中每一行就代表一个词向量。这样词汇表中所有的词都会从5000维的one-hot code转变成为128维的词向量。
-
输出层:
经过神经网络隐层的计算,这个输入的词就会变为1X128的向量,再被输入到输出层。(
输出层就是一个sotfmax回归分类器。它的每个结点将会输出一个0-1的概率,所有结点的值之和为1,我们就会取最大概率位置检测是否为输入样本x对应的y。)
本次处理是直接将embedding的结果输出到CNN层中并没有像word2vec进行单独的词向量训练。(提前训练好词向量对结果是否有所提高?)
import tensorflow as tfX_holder = tf.placeholder(tf.int32,[None,seq_length])
#X的占位符由于句子是由id组成的向量,而id为int类型,
#所以定义x的传入数据为tf.int32类型,
#None表示可以传任意组X,seq_length表示词向量维度。
embedding = tf.get_variable('embedding', [5000, 128])
#embedding字典维度为5000*128,128为词向量维度
embedding_outputs = tf.nn.embedding_lookup(embedding, X_holder)
#embedding_outputs的维度为(batch_size)64*600*128
最终经过embedding输出的样本维度为64 x 600 x 128
4.2 CNN
本次建模使用了一层卷积层,一层池化层,一层全连接层。
4.2.1 卷积层
卷积层实际上就是利用内核(卷积核),通过扫描图片来进行重新计算,计算方法为矩阵相乘后并将各个元素相加,得到新的像素值。
演示:


标准卷积计算:
-
输入文本的尺寸统一为600 x 128 (高度 x 宽度 )
-
本层一共具有256个卷积核,
-
每个卷积核的尺寸都是 8 x 128
-
已知 stride = 1, padding = 0(stride为每次移动的步长,padding为填充的数值)
-
batch_size = 64(每次训练样本)
-
输出矩阵的高度和宽度(height, width)这两个维度的尺寸由输入矩阵、卷积核、扫描方式所共同决定。计算公式如下。

| batch | Height | Width | in Depth | out Depth | |
|---|---|---|---|---|---|
| input | 64 | 600 | 128 | ||
| hidden | 8 | 128 | 256 | ||
| output | 64 | 593 | 1 | 256 |
通过卷积层输出的是一个64 x 593 x 1 x 256的样本维度
4.2.2 池化层
pooling层(池化层)的输入一般来源于上一个卷积层,主要有以下几个作用:
- 保留主要的特征,同时减少下一层的参数和计算量,防止过拟合;
- 保持某种不变性,包括translation(平移),rotation(旋转),scale(尺度),常用的有mean-pooling和max-pooling。
mean-pooling:(2 x 2区域取均值)

max-pooling:(2 x 2取最大值)

本文选用的是max-pooling(由于有些文本进行了补0,用mean-pooling影响结果太多)。
在每个维度取最大值,最终取得的维度为64 x 256
4.2.3 全连接层
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。(简单来说就是提纯特征,对卷积的结果做一个加权求和)
对于非线性问题我们一般采用两层以上的全连接层
第一层全连接(rule的激励函数):
运用128个神经元(可以理解为:128个256*1的的卷积核),取得的维度为64 x 128
第二层全连接(softmax的激励函数):
运用和最终分类一样数目的神经元,得出每个样本最终分类的概率。(由于样本均衡,概率最大即为某个类),得出的维度为64 x 10
在上面全连阶层输出的基础上再加上一个dropout来增加模型的泛化能力,防止过拟合,此处选择0.8的保留率。(对dropout的调整对结果是否具有一定的影响)
conv1 = tf.layers.conv1d(inputs=embedding_inputs,
filters=num_filters,kernel_size=kernel_size)
max_pool = tf.reduce_max(conv1,reduction_indices=[1])
full_connect = tf.layers.dense(max_pool,hidden_dim)
full_connect_dropout = tf.contrib.layers.dropout(full_connect,keep_prob=0.8)
full_connect_activate = tf.nn.relu(full_connect_dropout)
full_connect_last = tf.layers.dense(full_connect_activate,num_classes)
predict_y = tf.nn.softmax(full_connect_last)
5、结论
5.1 结构显示
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 600, 128) 640000
_________________________________________________________________
conv1d_1 (Conv1D) (None, 593, 256) 262400
_________________________________________________________________
max_pooling1d_1 (MaxPooling1 (None, 1, 256) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 256) 0
_________________________________________________________________
dense_1 (Dense) (None, 128) 32896
_________________________________________________________________
dropout_1 (Dropout) (None, 128) 0
_________________________________________________________________
activation_1 (Activation) (None, 128) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 1290
_________________________________________________________________
activation_2 (Activation) (None, 10) 0
=================================================================
Total params: 936,586
Trainable params: 936,586
Non-trainable params: 0
_________________________________________________________________
5.2 结果显示
目标函数:多分类的对数损失函数,与softmax分类器相对应的损失函数(合理科学)
优化器: 选择Adam优化器(一般情况Adam优化器的结果都比较好并且迭代速度较快)
评价指标:多分类准确率(计算在所有预测值上的平均正确率)
cross_entry = tf.nn.softmax_cross_entropy_with_logits_v2(labels=Y_holder,logits=full_connect_last)
loss = tf.reduce_mean(cross_entry)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train = optimizer.minimize(loss)
每次投入64个样本,每一百次训练后放入测试集测试结果,循环5000次。

| Label | Precision | Recall | F1 | Support | |
|---|---|---|---|---|---|
| 0 | 体育 | 0.9850 | 0.998986 | 0.991944 | 1000 |
| 1 | 娱乐 | 0.9750 | 0.970149 | 0.972569 | 1000 |
| 2 | 家居 | 0.8630 | 0.977350 | 0.916622 | 1000 |
| 3 | 房产 | 0.9920 | 0.998993 | 0.995484 | 1000 |
| 4 | 教育 | 0.9230 | 0.938008 | 0.930444 | 1000 |
| 5 | 时尚 | 0.9830 | 0.926484 | 0.953906 | 1000 |
| 6 | 时政 | 0.9330 | 0.948171 | 0.940524 | 1000 |
| 7 | 游戏 | 0.9750 | 0.977934 | 0.976465 | 1000 |
| 8 | 科技 | 0.9600 | 0.986639 | 0.973137 | 1000 |
| 9 | 财经 | 0.9960 | 0.878307 | 0.933458 | 1000 |
| 10 | 总体 | 0.9585 | 0.960102 | 0.958455 | 10000 |
结论:和原作者95.35%的分类结果基本吻合。从分类结果来看,家居、教育、时政的分类结果一般,家居会误分类入时尚和财经类,教育会误分类入时政和财经类,时政会误分类教育和财经。(或许可能是这三种文章的内容较短,而这里基于所有文章同样长度来做训练,导致了预测不佳的情况。)
6、自我改进
6.1 改进的内容
- 利用文本数据先对词汇进行预训练(success)
- 调整激活函数的种类(Failed)
- 加入BatchNormalization层(Failed,why?)
- 调整权重初始化的方法:
- MSRA初始化(Failed)
- Xavier初始化(success)
- dropout的调整(调试几次还是0.2最好)
6.2 思维导图

6.3 结果展示

| Label | Precision | Recall | F1 | Support | |
|---|---|---|---|---|---|
| 0 | 体育 | 0.997003 | 0.998 | 0.997501 | 1000 |
| 1 | 娱乐 | 0.996894 | 0.963 | 0.979654 | 1000 |
| 2 | 家居 | 0.974895 | 0.932 | 0.952965 | 1000 |
| 3 | 房产 | 0.982000 | 0.982 | 0.982000 | 1000 |
| 4 | 教育 | 0.965139 | 0.969 | 0.967066 | 1000 |
| 5 | 时尚 | 0.946616 | 0.993 | 0.969253 | 1000 |
| 6 | 时政 | 0.987526 | 0.950 | 0.968400 | 1000 |
| 7 | 游戏 | 0.969756 | 0.994 | 0.981728 | 1000 |
| 8 | 科技 | 0.963366 | 0.973 | 0.968159 | 1000 |
| 9 | 财经 | 0.969815 | 0.996 | 0.982733 | 1000 |
| 999 | 总体 | 0.975301 | 0.975 | 0.974946 | 10000 |
结论:
现阶段通过多次调整的最优结果是word2vec预训练+Xavier+CNN,准确率达到了97.5%提升了1.7%,其实1.2%是由于词汇表的预训练得来的,剩下的是调整初始化权重得来的。
6.4 后续调整
- word2vec的预训练比较粗糙,里面很多参数和算法没有详细理解,另外如果能用最新的BERT或者GPT.2模型进行预训练应该会得到更为出色的结果
- 换textcnn、RNN等模型调试结果(但我浏览了网上大牛的文章基本的说法是,对于这类文本分类提升的效果不是很明显主要还是超参数的设置)
- 调整mini_batch的大小
- 调整正则化参数的大小
- 调整神经元的数量
- 能否引入attention机制
- ……
这篇关于THUCNews学习(CNN模型)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








