本文主要是介绍FCOS难点记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
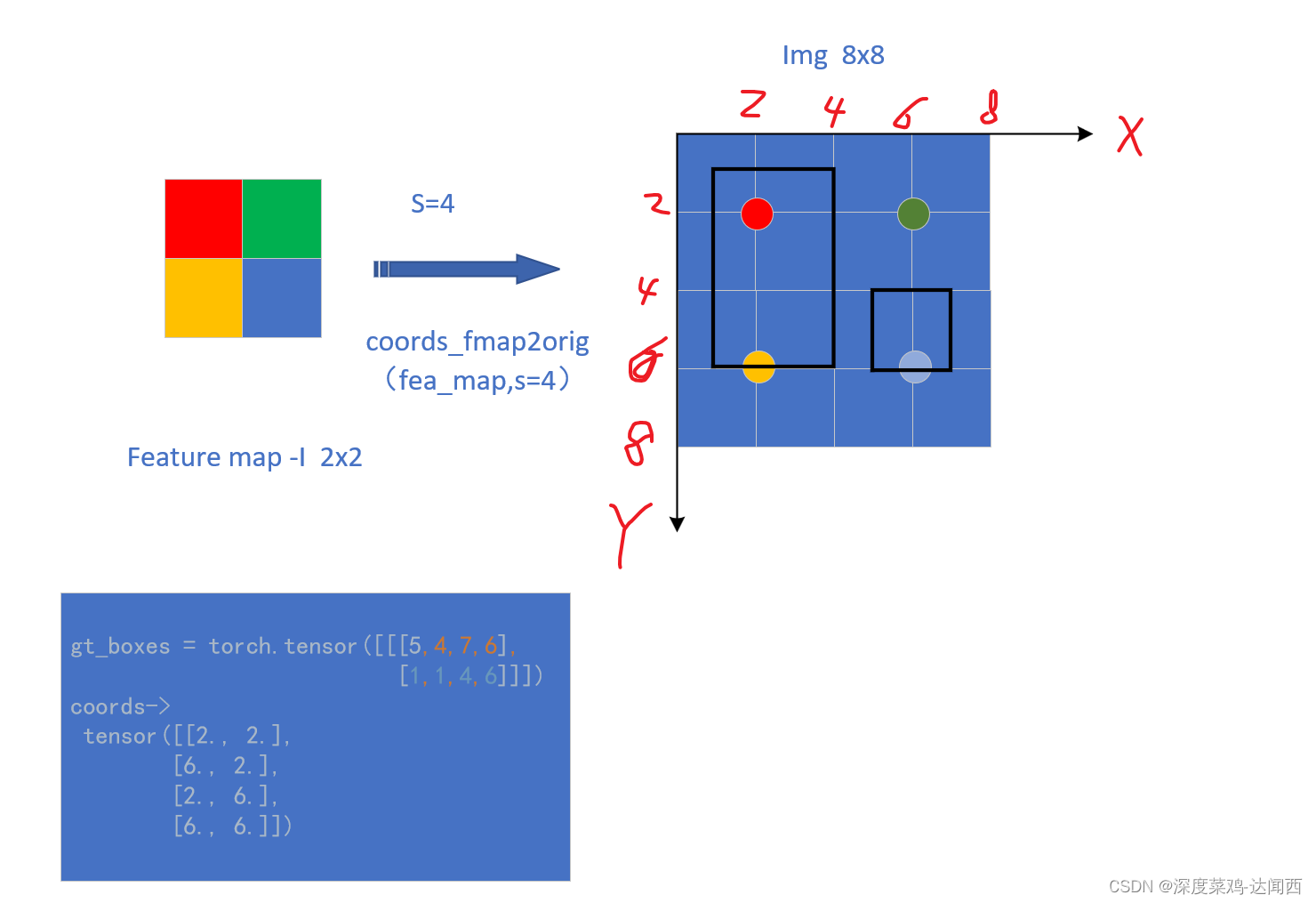
FCOS 中有计算 特征图(Feature map中的每个特征点到gt_box的左、上、右、下的距离)
1、特征点到gt_box框的 左、上、右、下距离计算
x = coords[:, 0] # h*w,2 即 第一列y = coords[:, 1] l_off = x[None, :, None] - gt_boxes[..., 0][:, None, :] # [1,h*w,1]-[batch_size,1,m]-->[batch_size,h*w,m]t_off = y[None, :, None] - gt_boxes[..., 1][:, None, :]r_off = gt_boxes[..., 2][:, None, :] - x[None, :, None]b_off = gt_boxes[..., 3][:, None, :] - y[None, :, None]ltrb_off = torch.stack([l_off, t_off, r_off, b_off], dim=-1) # [batch_size,h*w,m,4]areas = (ltrb_off[..., 0] + ltrb_off[..., 2]) * (ltrb_off[..., 1] + ltrb_off[..., 3]) # [batch_size,h*w,m]off_min = torch.min(ltrb_off, dim=-1)[0] # [batch_size,h*w,m]off_max = torch.max(ltrb_off, dim=-1)[0] # [batch_size,h*w,m]
根据上边的画的图可以看出,假设对应的 feature map 大小为 2x2,stride=4,原始图片为8x8。将特征图中的每个特征点映射回去,可以得到相应的 4个(h*w个)坐标。对应图中的 红色a,绿色b,黄色c和蓝色d的点。
print(x,"\n",y,x.shape)
'''
tensor([2., 6., 2., 6.])
tensor([2., 2., 6., 6.]) torch.Size([4])
'''print(x[None,:,None]) # [1,4,1]
'''
tensor([[[2.],[6.],[2.],[6.]]])
'''print(gt_boxes) # [1,2,4] batch=1, 两个框,每个框左上角和右下角坐标
'''
tensor([[[5, 4, 7, 6],[1, 1, 4, 6]]])
'''print(gt_boxes[...,0],gt_boxes[...,0][:,None,:])
'''
tensor([[5, 1]]) tensor([[[5, 1]]])
'''
l_off = [2,2]-[5,1]=[-3,1] 以此类推print(l_off,"\n", l_off.shape)'''
**第一列代表,所有的点abcd横坐标与第一个框的左边偏移量。第二列代表到第二个框的偏移量**
tensor([[[-3., 1.],[ 1., 5.],[-3., 1.],[ 1., 5.]]]) torch.Size([1, 4, 2])'''print(ltrb_off)
'''
第一列代表,所有的投影点abcd,到两个框的左边偏移量。第一行第二行分别代表两个框。
tensor([[[[-3., -2., 5., 4.], # a 点到第一个框的左边、上边、右边、下边的偏移[ 1., 1., 2., 4.]], # a 点到第二框的左边、上边、右边、下边的偏移[[ 1., -2., 1., 4.], # b 点到第一个框的左边、上边、右边、下边的偏移[ 5., 1., -2., 4.]],[[-3., 2., 5., 0.],[ 1., 5., 2., 0.]],[[ 1., 2., 1., 0.],[ 5., 5., -2., 0.]]]]) torch.Size([1, 4, 2, 4]) #[batch_size,h*w,m,4]
'''print(ltrb_off[...,0])
'''tensor([[[-3., 1.],[ 1., 5.],[-3., 1.],[ 1., 5.]]]) torch.Size([1, 4, 2])
'''print(areas)
'''
areas: tensor([[[ 4., 15.],[ 4., 15.],[ 4., 15.],[ 4., 15.]]])
'''torch.return_types.min(
values=tensor([[[-3., 1.],[-2., -2.],[-3., 0.],[ 0., -2.]]]),
indices=tensor([[[0, 0],[1, 2],[0, 3],[3, 2]]])) torch.return_types.max(
values=tensor([[[5., 4.],[4., 5.],[5., 5.],[2., 5.]]]),
indices=tensor([[[2, 3],[3, 0],[2, 1],[1, 0]]]))2、确定该特征点在哪一个框内,是否在该FPN特征层进行尺寸判断并进行后续预测
off_min = torch.min(ltrb_off, dim=-1)[0] # [batch_size,h*w,m] # off_min 找出所有 特征点 到 每个框的 四条边 最小的距离
off_max = torch.max(ltrb_off, dim=-1)[0] # [batch_size,h*w,m] #off_max 找出所有 特征点 到 每个框的 四条边 最大的距离mask_in_gtboxes = off_min > 0
mask_in_level = (off_max > limit_range[0]) & (off_max <= limit_range[1]) # 锁定在这个limit range上的所有的特征的点
print("ltrf_off",ltrb_off)
print("off_min",off_min,"\n","off_max",off_max)
print("mask_in_gtboxes-->",mask_in_gtboxes)
print("mask_in_level-->",mask_in_level)'''
ltrf_off tensor([[[[-3., -2., 5., 4.], # a 点到第一个框的左边、上边、右边、下边的偏移[ 1., 1., 2., 4.]], # a 点到第二个框的左边、上边、右边、下边的偏移[[ 1., -2., 1., 4.], # b 点到第一个框的左边、上边、右边、下边的偏移[ 5., 1., -2., 4.]],[[-3., 2., 5., 0.],[ 1., 5., 2., 0.]],[[ 1., 2., 1., 0.],[ 5., 5., -2., 0.]]]])off_min
tensor([[[-3., 1.], # a点到第一个框最小距离-3, a点到第二个框的最小偏移距离 1[-2., -2.], #b点到第一个框最小距离-2, b点到第二个框的最小偏移距离 -2[-3., 0.], # c点到第一个框最小距离-3, a点到第二个框的最小偏移距离 0[ 0., -2.]]]) # d点到第一个框最小距离0, a点到第二个框的最小偏移距离 -2off_max tensor([[[5., 4.],[4., 5.],[5., 5.],[2., 5.]]])mask_in_gtboxes--> # 判断了 特征点是否在框内
tensor([[[False, True], # a点到第一个框四边最小偏移距离小于0,所以,a点不属于第一个框,为false;以此类推。[False, False],[False, False],[False, False]]]) # [batch,h*w,m]mask_in_level--> # 锁定在这个limit range上的所有的特征的点
tensor([[[True, True], # 锁定了a 在这个level中[True, True], # 锁定了b[True, True], # 锁定了c[True, True]]])# 锁定了d 都在这个FPN级别上 [batch,h*w,m]
'''
3、特征点是否在框中心的范围内,用来判断是否为正样本
radiu = stride * sample_radiu_ratio # 4*1.15 = 4.6gt_center_x = (gt_boxes[..., 0] + gt_boxes[..., 2]) / 2gt_center_y = (gt_boxes[..., 1] + gt_boxes[..., 3]) / 2c_l_off = x[None, :, None] - gt_center_x[:, None, :] # [1,h*w,1]-[batch_size,1,m]-->[batch_size,h*w,m]c_t_off = y[None, :, None] - gt_center_y[:, None, :]c_r_off = gt_center_x[:, None, :] - x[None, :, None]c_b_off = gt_center_y[:, None, :] - y[None, :, None]c_ltrb_off = torch.stack([c_l_off, c_t_off, c_r_off, c_b_off], dim=-1) # [batch_size,h*w,m,4]c_off_max = torch.max(c_ltrb_off, dim=-1)[0]mask_center = c_off_max < radiu
print("c_ltrb_off",c_ltrb_off)
print("c_off_max",c_off_max)
print("mask_center",mask_center)'''
c_ltrb_off
tensor([[[[-4.0000, -3.0000, 4.0000, 3.0000], # 同上边一样,a到 第一个框 小的中心框四边 的距离[-0.5000, -1.5000, 0.5000, 1.5000]], # a到 第二个框 小的中心框四边 的距离[[ 0.0000, -3.0000, 0.0000, 3.0000], # b到 第一个框 小的中心框四边 的距离[ 3.5000, -1.5000, -3.5000, 1.5000]], # # b到 第二个框 小的中心框四边 的距离[[-4.0000, 1.0000, 4.0000, -1.0000],[-0.5000, 2.5000, 0.5000, -2.5000]],[[ 0.0000, 1.0000, 0.0000, -1.0000],[ 3.5000, 2.5000, -3.5000, -2.5000]]]])c_off_max tensor([[[4.0000, 1.5000], # 找到a特征点到第一个框中心框和第二个框的中心框的 最大距离[3.0000, 3.5000],[4.0000, 2.5000],[1.0000, 3.5000]]]) # [batch,h*w,m] 4个特征点(a,b,c,d) x 框的个数2个(第一个框,第二个框)mask_center tensor([[[True, True], # 判断是否在这个框里中心点里边 正样本[True, True],[True, True],[True, True]]]) ## [batch,h*w,m]
'''3、制定mask,根据上边的 gt_box、fpn_level、mask_center
‘’’
mask_pos 是三个约束条件的交集,分别是特征点在gt中,特征点在level中,以及特征点距离Gt中的center小于指定的范围
‘’’
mask_pos = mask_in_gtboxes & mask_in_level & mask_center # [batch_size,h*w,m]areas[~mask_pos] = 99999999
areas_min_ind = torch.min(areas, dim=-1)[1] # [batch_size,h*w]
mask_pos = mask_in_gtboxes & mask_in_level & mask_center # [batch_size,h*w,m]
print("pre_areas:",areas)
areas[~mask_pos] = 99999999
areas_min_ind = torch.min(areas, dim=-1)[1] # [batch_size,h*w] # 返回索引,注意和上边的区别,上边返回值,比大小
# torch.max() or torch.min() dim=0 找列,dim=1 找行
print("mask_pos-->",mask_pos)
print("post_ares",areas)
print("areas_min_ind",areas_min_ind)'''
mask_in_gtboxes-->
tensor([[[False, True],[False, False],[False, False],[False, False]]])
mask_in_level-->
tensor([[[True, True],[True, True],[True, True],[True, True]]])
mask_center
tensor([[[True, True],[True, True],[True, True],[True, True]]])mask_pos-->
tensor([[[False, True], # 只有a点在第二个框在这个fpn这个level, 同时满足这三个条件[False, False],[False, False],[False, False]]])post_ares
tensor([[[1.0000e+08, 1.5000e+01],[1.0000e+08, 1.0000e+08],[1.0000e+08, 1.0000e+08],[1.0000e+08, 1.0000e+08]]]) # #[batch_size,h*w,m] 将 满足要求的 保持面积不面,其他设置为很大的值areas_min_ind tensor([[1, 0, 0, 0]]) # [batch_size,h*w] min[1]返回的是对应的indices 找到最小的面积,返回索引。'''4、

reg_targets = ltrb_off[torch.zeros_like(areas, dtype=torch.bool)
.scatter_(-1, areas_min_ind.unsqueeze(dim=-1), 1)] # [batch_size*h*w,4]
reg_targets = torch.reshape(reg_targets, (batch_size, -1, 4)) # [batch_size,h*w,4]
scatter_的用法:参考 https://blog.csdn.net/weixin_43496455/article/details/103870889
scatter(dim, index, src)将src中数据根据index中的索引按照dim的方向进行填充。dim=0
'''
areas:
tensor([[[ 4., 15.],[ 4., 15.],[ 4., 15.],[ 4., 15.]]]) [1,4,2]
扩展维度之后 [1,4] --> torch.Size([1, 4, 1]) ===> [[[1,0,0,0]]]
torch.zeros_like(areas, dtype=torch.bool)
tensor([[[False, False],[False, False],[False, False],[False, False]]])after scatter_-->
tensor([[[False, True],[ True, False],[ True, False],[ True, False]]]) # [1,4,2]ltrf_off
tensor([[[[-3., -2., 5., 4.], # a 点到第一个框的左边、上边、右边、下边的偏移[ 1., 1., 2., 4.]], # a 点到第二个框的左边、上边、右边、下边的偏移[[ 1., -2., 1., 4.], # b 点到第一个框的左边、上边、右边、下边的偏移[ 5., 1., -2., 4.]],[[-3., 2., 5., 0.],[ 1., 5., 2., 0.]],[[ 1., 2., 1., 0.],[ 5., 5., -2., 0.]]]])reg_targets1
tensor([[ 1., 1., 2., 4.], # a 点 第二个框[ 1., -2., 1., 4.], # b 点 第一个框[-3., 2., 5., 0.], # c 点 第一个框[ 1., 2., 1., 0.]])# d 点 第一个框# torch.Size([4, 4])reg_targets2 tensor([[[ 1., 1., 2., 4.],[ 1., -2., 1., 4.],[-3., 2., 5., 0.],[ 1., 2., 1., 0.]]]) # torch.Size([1, 4, 4])
'''
这篇关于FCOS难点记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







