本文主要是介绍动物园查询动物,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
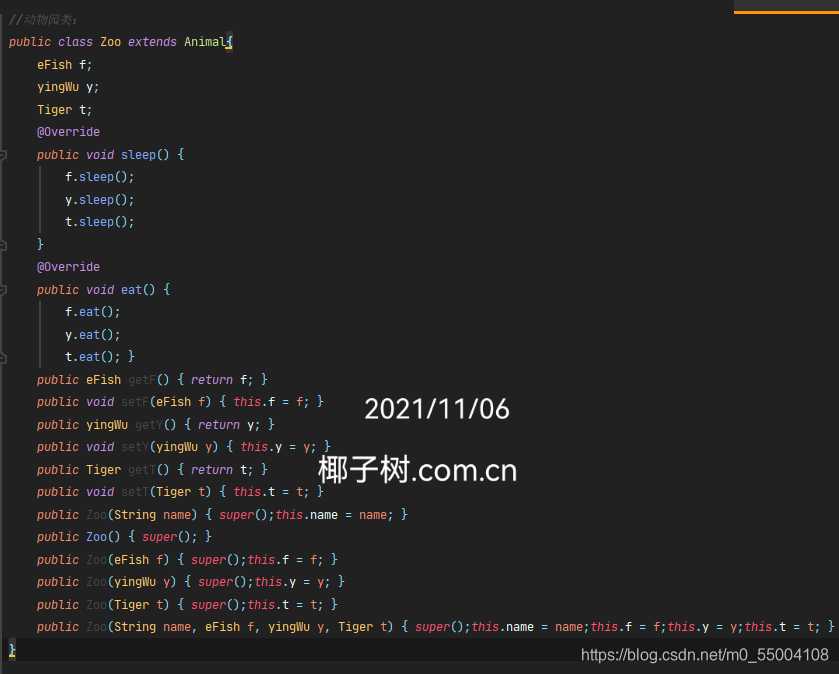
写一个动物类,有名字、简介属性,有一个睡觉行为;有若干个子类鳄鱼、老虎、鹦鹉;所有动物都有吃饭行为,只是吃的东西不同;鹦鹉睡觉要在树上;老虎每天要吃N次饭;鳄鱼还有一个游泳行为。
写一个动物园类,该类有一个添加动物行为,可以把某个动物加入动物园。写一个测试类,在主方法中生成动物园对象,代表有一个动物园出现了。此时出现欢迎信息,欢迎来到XXX动物园。接下来,输入某个动物名称,会显示该动物的简介,睡觉行为、吃饭行为。如果动物园没有该动物,提示用户没有

这篇关于动物园查询动物的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







