本文主要是介绍SINT(Siamese Instance Search for Trancking)阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
理解有误,欢迎指正,转载请注明出处!
这是发表在CVPR2016上的一遍用深度学习做跟踪方向的文章,文章利用孪生网将跟踪问题与图像的匹配问题联系到一起。
论文链接
代码链接
-
文章的核心思想:
通过Siam网络学习一个匹配函数。在得到第一帧目标信息之后,接下来的每一帧的候选框都和第一帧目标框进行匹配度计算,得分最高的候选框即为该帧中目标。(好处:目标被遮挡之后不用担心无法找回,因为网络不更新,那么遮挡物并不会影响到网络性能; 目标丢失后也不会担心找不到,因为网络不更新) -
先来看一下这篇论文的整体框图:
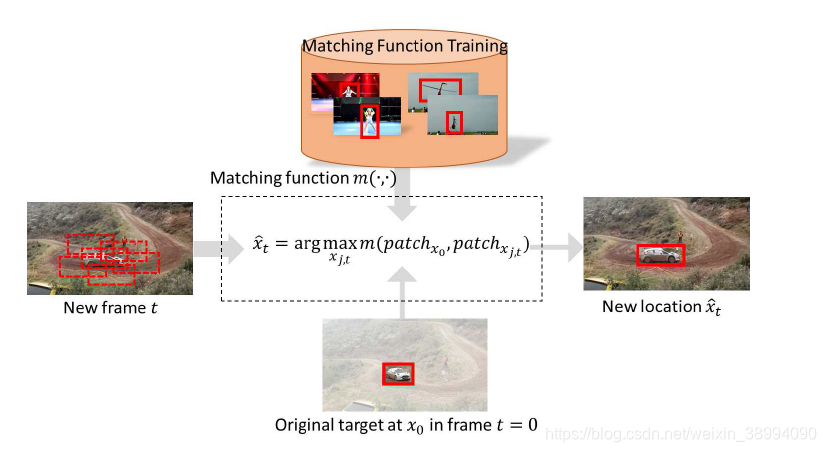
图解析:跟踪器只使用了一个学习的匹配函数,利用大量的外部视频学习了一个先验的匹配函数(Matching function),在跟踪的过程中,初始目标(patch x0)不再变化,对视频序列中的每一个 Frame t 以及通过半径采样策略选出的候选框patch x(j,k) (表示帧 t 中的第 j 个候选框)送入到CNN网络中,根据评估函数,找到得分最高的那个候选框即为下一帧目标的位置。 -
上图让我们对这篇文章的思路有了大体的了解,下面来聚焦几个具体的问题:
- 学习一个先验的匹配函数,用了哪些样本?
答:论文中提到,在学习的过程中关注广义的目标外形的变化,意思是目标的范围要足够大,足够广,考虑到算法的鲁棒性,希望训练的样本不是针对某一类特定的目标,也不是关注目标变化中的某一类特定的属性(例如形变、光照变化中),这样是为了当跟踪情况下没有训练集中的目标,匹配函数依然能很好的工作。 - 利用半径采样策略选出候选框,上述所说的半径采样策略是什么?
答:这个地方参考了样本采样方法
我理解的采样策略:为了解决尺度问题,作者引入了图像的缩放尺度[ √2/2 , 1 ,√2 ],对于每一个尺寸的图像,采样变动的是坐标,而非长和宽。
半径采样策略,作者借鉴了这篇论文S. Hare, A. Saffari, and P. H. Torr. Struck: Structured output tracking with kernels. In ICCV, 2011。半径采样策略是为了找出跟踪问题中目标在下一帧图像的位置。通过极坐标采样方式在每个boundingbox周围得到sample框,boundingbox是上一帧的准确位置,sample是在当前帧中选取的候选框16 x 5=80个,然后在这80个框中选取匹配函数得分最高的框作为当前帧的位置,以此类推再找下一帧的确定位置。
采样的框主要是对目标框的平移和放缩,半径采样策略选取上一帧目标框的长轴作为半径,半径分 nr 步从里到外延伸,分 nt 步从0开始旋转(论文中取nr=5,nt=16),所以每次旋转角度2*pi/nt,每步走的像素:radius/nr. 于是乎for ir in 1:nr ,for it in 0:nt-1,迭代80次,根据公式
for ir = 1 : nr %遍历从里到外延伸的步数 phase = mod(ir, 2) * tstep / 2; %mod取余,也就是半径为偶数步时,phase为0;半径为奇数步时,phase为单位旋转角度的一半for it = 0 : nt - 1 %遍历圆周旋转的步数,从0开始,到15dx = ir * rstep * cos(it * tstep + phase); %x坐标增量=第几步*单位步长*cos(第几个旋转角*单位旋转角度+phase)dy = ir * rstep * sin(it * tstep + phase); s.x = boundingBox.x + dx; %得到移动后的移动窗口的x坐标s.y = boundingBox.y + dy; %得到移动后的移动窗口的y坐标s.w = boundingBox.w;s.h = boundingBox.h; %移动窗口的高度和宽度保持不变index = index + 1;samples{index} = s; %记录移动后的移动窗口信息,也就是此时这个样本的位置 end
-
算法实现细节
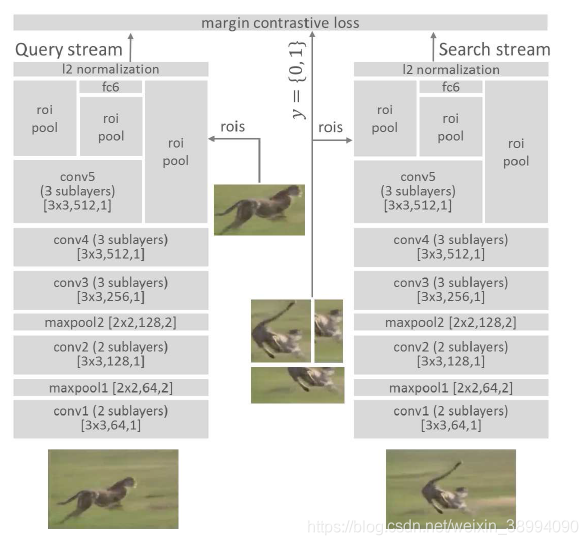
图解析:网络模型分为两路。
跟踪的时候:
左侧 “query stream”,输入第一帧的图像以及 bounding box,右侧 “search stream”,输入第 t 帧以及半径采样策略得到的candidate box
训练的时候:
query stream 输入:训练数据集中的一个视频序列A中的任何一个图片的grounding bounding box
search stream输入:随机选取一个视频序列A中的与query stream不同的任何一个图片的bounding box。(在提供的训练集中,每一帧图像都有其目标所在的真实位置,只需计算两帧图像的IoU,用途如下)
Y{0,1} : 若输入的两个 box 的覆盖率>0.7 即为正样本, y=1 ; 若覆盖率 < 0.5 即为负样本,y=0。
损失函数设计:L(xj,xk,yj,k)=1/2yj,kD2 + 1/2(1-yj,k)max(0,@-D2),其中超参数@。 -
算法实现步骤
1、获取ALOV数据集,并进行预处理,(至于做了什么预处理,容我读完代码再更新)
2、搭建上图所示的网络架构(引入ROI Pooling)
3、在训练数据中获取 patch 块, (X1,X2,Y),开始训练网络,获得最终的模型,即所谓的相似度函数,也即匹配函数。
4、使用预训练好的模型进行跟踪,X1是第一帧以及bounding box,X2是当前帧以及 candidate box(好多个),X1,X2 通过卷积走到网络的 roi 层,再对bounding box 以及candidate box 进行匹配算法,相似度最高的即为目标。 -
论文中还提到了深度学习 的这个网络的设计一些问题,此处参考了[1]
1、对pooling层的改进:减少原本网络结构的pooling层数。作者解释的原因是pooling会降低图像的空间分辨率,这个分辨率对分类任务来说影响不大,但是类似定位、目标跟踪这样的任务对分辨率还是有一定要求的,但同时又为了保证pooling带来的消除高频小噪声的好处,所以,对pooling层要适当减少。具体为VGG只包含两个pooling层,Alexnet不再包含pooling层。
2、对fast-Rcnn的借鉴:由于单个处理多个candidate regions耗时耗力,因此采用region pooling layer来快速处理多个重叠区域,每一分支的输入为全图加上一系列bounding box,前几层网络先处理整幅图像,然后ROI层把特定区域的特征图转换为固定长度的表达,再送往网络的高层。
3、多层特征综合考虑:网络层越深,表达越抽象,低层特征对类内差异更敏感,高层特征对类间差异更敏感。在跟踪任务里是高层特征好,还是低层特征好,难以定论,所以高层和低层的特征都采用,将多层的输出特征直接馈送到损失层 。
4、正则项约束:激活函数采用RELU,但是这样输出的幅度就会没有限制,幅度的大小会影响损失函数的大小,所以在损失函数前加一个l2范数层来限制幅度。
5、损失函数的设计:正样本对尽量离得近,负样本对离得远。
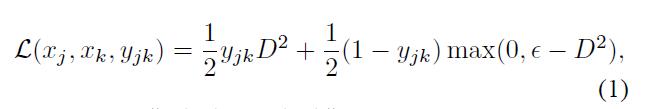
-
算法特点
1、模型一旦训练完成,在跟踪的过程中不需要更新模型,(因为要快!)
2、匹配函数的训练不需要指定特定类别的目标,即离线训练之后的模型在应用于跟踪的时候,可以跟踪训练过程中没有见过的目标。(说是鲁棒性强)
3、速度问题:如果在当前的帧中每提取一个样本(一帧中可以提取多个样本)就和第一帧图片计算一次匹配度是很费时的,作者参考Fast-Rnn思想,从一幅大的图片经过 CNN 后的输出特征图中寻找想要的小patch的特征部分,从而在前面几层只需要一次的CNN 的前向计算即可,最后根据给定的 bounding box regions选取 n 个feature map 在后面几层进行传播计算。(即这个做法是降低了候选样本的个数)我理解的是 feature map 不是 CNN 得到的,而是跟随着 X2 输入到网络中的,也即在进行前向传播之前,已经通过半径采样策略得到了candidate box. -
论文的创新点----将跟踪问题转化为图像匹配的问题,并且引入了深度学习。
-
思考
1、论文中说到的半径采样策略,还提到了生成初始框的三个放缩样本 [ √2/2 , 1 ,√2 ] ,我理解的这样candidate box 获取会有 3 x 80 = 240 个,具体我看一下代码再解释。
2、还有一个位置精度的问题,与作者减少pooling层数有关系,传统的 CNN 中,pooling操作的目的是降低特征维度,但是这又会降低定位的准确度,作者给出了解释:CNN中引入pooling主要是为了解决物体分类问题,在物体分类任务中,物体的外形会发生很大的改变,这样pooling操作可以在一定程度上对目标变形具有特征值不变性,但是在跟踪问题中,在一个视频序列中即使目标外形发生改变也始终跟踪同一个目标,所以在一定程度上减少polling操作会对匹配精度有很大的影响。所以,最终作者去掉了AlexNet中所有pooling操作,仅仅保留VGGNet中前两个pooling操作,因为在浅层感受野较小,保留pooling操作对抵抗噪声的鲁棒性有益。 -
参考
[1] https://blog.csdn.net/mtc_Ningning/article/details/52814480
[2] https://cloud.tencent.com/developer/news/281788
[3] https://blog.csdn.net/aiqiu_gogogo/article/details/79225555
这篇关于SINT(Siamese Instance Search for Trancking)阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






