本文主要是介绍CVPR-2016-SINT:Siamese Instance Search for Tracking阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SINT阅读笔记
- 一、 动机
- 二、 贡献
- 三、 主要内容
- 四、 实验结果
- 五、 结论
论文地址: https://arxiv.org/pdf/1605.05863.pdf
论文代码地址: https://github.com/taotaoorange/SINT
一、 动机
建议学习匹配机制,而不是明确地为特定的行为建模
二、 贡献
① 建议从外部视频数据中学习一个用于跟踪的通用匹配函数,以稳健地处理一个对象在视频序列中可能经历的常见外观变化。学习到的函数可以不需要任何调整,直接应用到新的跟踪视频中。这些视频中的目标对象是之前没有看到过的目标对象。
② 在学习到的泛型匹配函数的基础上,提出了一种跟踪器,该跟踪器达到了最先进的跟踪性能。所提出的跟踪器与最先进的跟踪器有根本的不同。不使用模型更新,不使用遮挡检测,不使用跟踪器的组合,不使用几何匹配等。在每一帧中,跟踪器通过学习到的匹配函数,简单地找到与第一个帧中目标的初始补丁最匹配的候选补丁。
③ 为了学习匹配函数,专门为跟踪而设计了孪生网络。
④ 在没有任何漂移的情况下,提出的跟踪器有能力对长期消失的目标对象重新跟踪,因为其始终和第一帧的模板对比。
三、 主要内容
算法结构图:

SINT简单地将第一帧中目标的初始patch与新帧中的候选patch进行匹配,并通过学习匹配函数返回最相似的patch。匹配函数在一个丰富的视频数据集上学习一次。一旦它被学习,它就会被应用到以前看不见的目标对象的新视频中,而不需要任何调整。候选框的选择采用半径采样策略。更具体地说,就是围绕前一帧的预测位置,在不同半径的圆上均匀采样位置。搜索半径设置为第一帧中初始框的较长轴。同时,为了处理尺度变化,在每个采样点产生多个不同尺度的候选框(√2/2,1,√2)。
深受VGGNet启发的网络架构:

“conv”、“maxpool”、“roipool”和“fc”分别代表卷积层、最大池化层、感兴趣区域池化层和完全连接层。方括号中的数字是内核大小、输出数量和步长。完全连接的层有4096个单元。
网络架构:
作者设计并比较了两种不同的网络架构,一种是类似于AlexNet的小型网络架构,另一种是深受VGGNet启发的深度网络架构(上图)。这种架构可以兼容AlexNet和VGGNet。通过这种方式,可以使用imagenet预训练的AlexNet和VGGNet来初始化网络的权值,以避免从头开始训练(从头训练可能会导致过拟合)。另外,两个卷积网络分支共享参数,减少过拟合的危险。
最大池化层:
为了实现精确定位,设计的网络的最大池层非常少。对于类似AlexNet的小网络,不包括任何max pooling层,而对于类似VGGNet的大网络,只在早期阶段有两个max pooling层。因为最大池化只保留了来自局部邻近的最强激活以作为后续层的输入,激活的空间分辨率会大大降低,但最大池化层还有一个优点就是它引入了局部变形的不变性。
感兴趣区域池化层:
区域池化层能快速处理多个重叠区域。作者将感兴趣区域池化层合并到网络中,以便在一个帧中快速处理多个区域以进行跟踪,减少计算开销。
规范化层:
建议在损失层之前添加ℓ2规范化层。所述规范化层被应用于每一个被馈送到所述损失层并具有保持所述特征方向的特性的层激活,同时迫使来自不同尺度的特征位于同一单位上。这样就避免网络输出和损失函数受到所生成特征规模的严重影响。
以孪生网络为算法骨架的原因:
学习一个对各种扭曲都具有鲁棒性的匹配函数,需要一个对数据对(xj, xk)进行操作的模型,孪生网络体系结构被成功地证明在数据对上工作得很好。
损失公式:
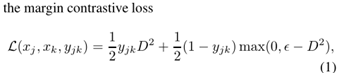
D = ||f(xj)−f(xk)||2是归一化表示的欧式距离
yjk∈{0,1}表示xj 与xk是否为同一对象
ε是描绘不同对象的对应满足的最小距离边界。
选择与原始目标最匹配的候选框:

四、 实验结果
训练时,总共从ALOV数据集中采样了60000对帧,每对帧有128对boxs。验证时,我们收集了2000对帧,和训练一样,每一对帧包含128对boxs。
使用ImageNet预先训练好的网络参数对Siamese网络进行微调。初始微调学习率为0.001,权重衰减参数为0.001。学习速率每隔2个周期下降10倍。当验证损失不再减少时,停止调优。
网络结构设计选择实验依据:

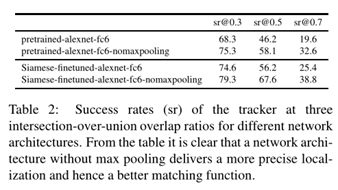
在OTB中评估跟踪性能:

(SINT+:SINT的变体,使用了光流自适应候选采样策略)
五、 结论
本文提出了孪生实例搜索跟踪器SINT。它跟踪目标,简单地将第一帧中的初始目标与新帧中的候选目标进行匹配,并通过学习匹配函数返回最相似的一个。特别注意训练视频和任何用于评估的视频之间绝对没有重叠。也就是说,不对跟踪目标做任何预学习。一旦学习,匹配函数被使用,没有任何调整,以跟踪任意以前不可见的目标。
这篇关于CVPR-2016-SINT:Siamese Instance Search for Tracking阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








