本文主要是介绍关于数据打印的详细探讨:如何才能打印得更整齐,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、话题引入
打印时一般有两种方式来使输出整齐规范,一个是限制位宽%-8s这样的,另一种使用制表符\t。
由于制表符\t是根据其前输出来补位的,而实际打印时数据长度往往不一,无法打印整齐。
制表符的补位规则
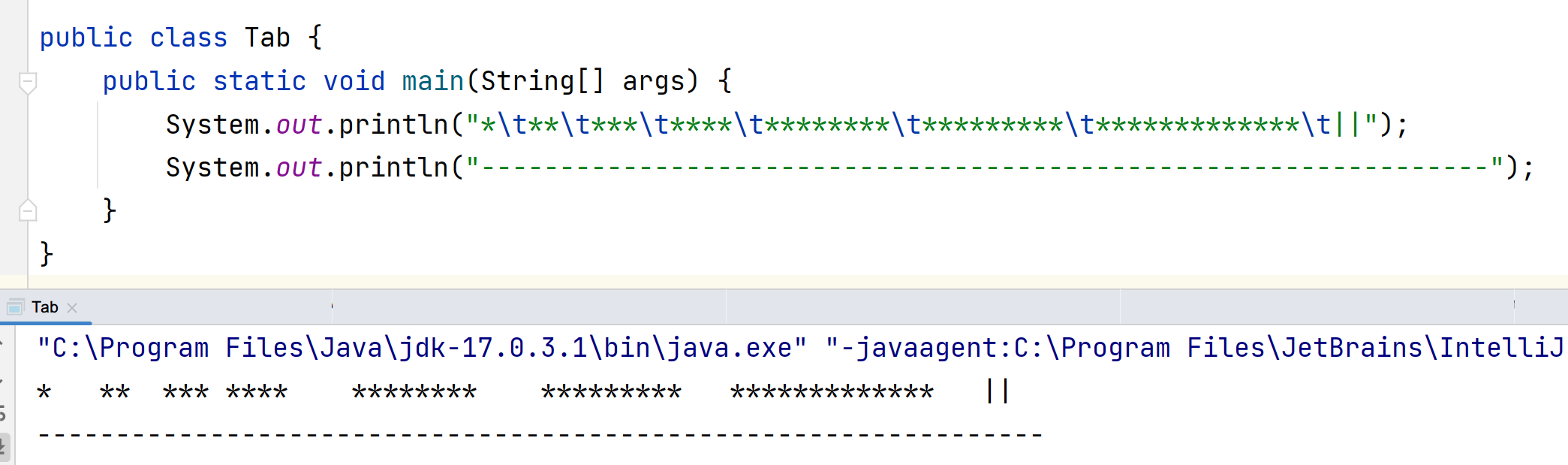
上网查询的话会发现都是说8位,但实际测试发现是4位,4n-3 到4n-1补到4n,4n到4n+3补到4(n+1)。(n是自然数).
制表符将输出区分成4格4格的区域,而\t就是跳到下一个4格开始的地方。
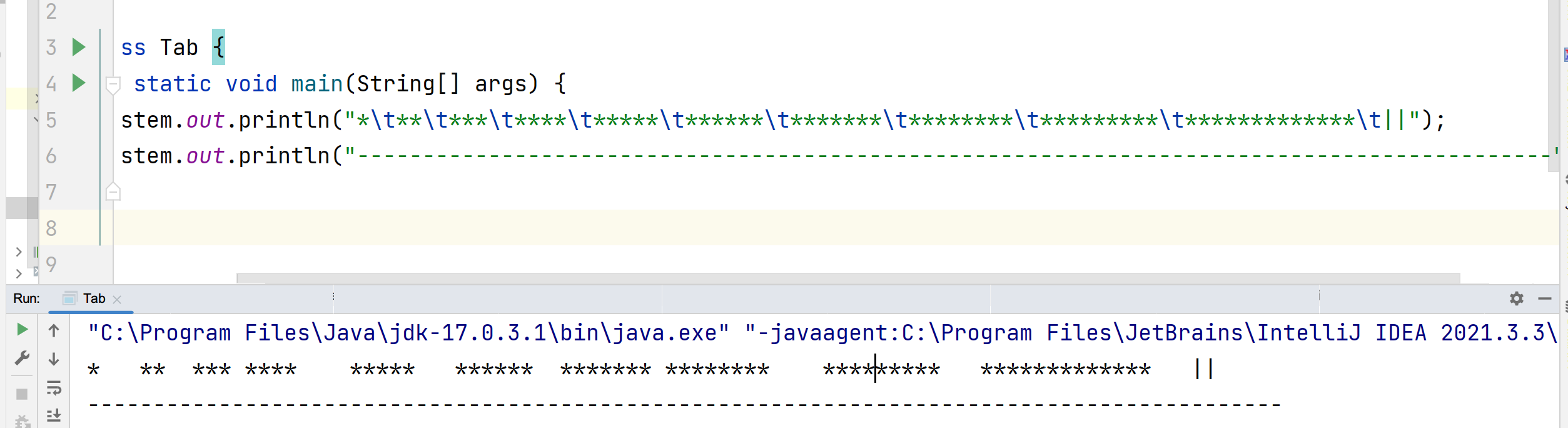
而使用限制位宽的方式又有如下的问题
我们发现都是限制位宽为4,两者打印宽度根本不一样,并且两者的宽度都不是4格。原因可以想到应该是中文也被认为是一个位宽但是实际宽度却不是一个空格导致的。
两者均不能得到我们想要的输出效果,所以到底要怎样输出整齐呢?
二、问题解决
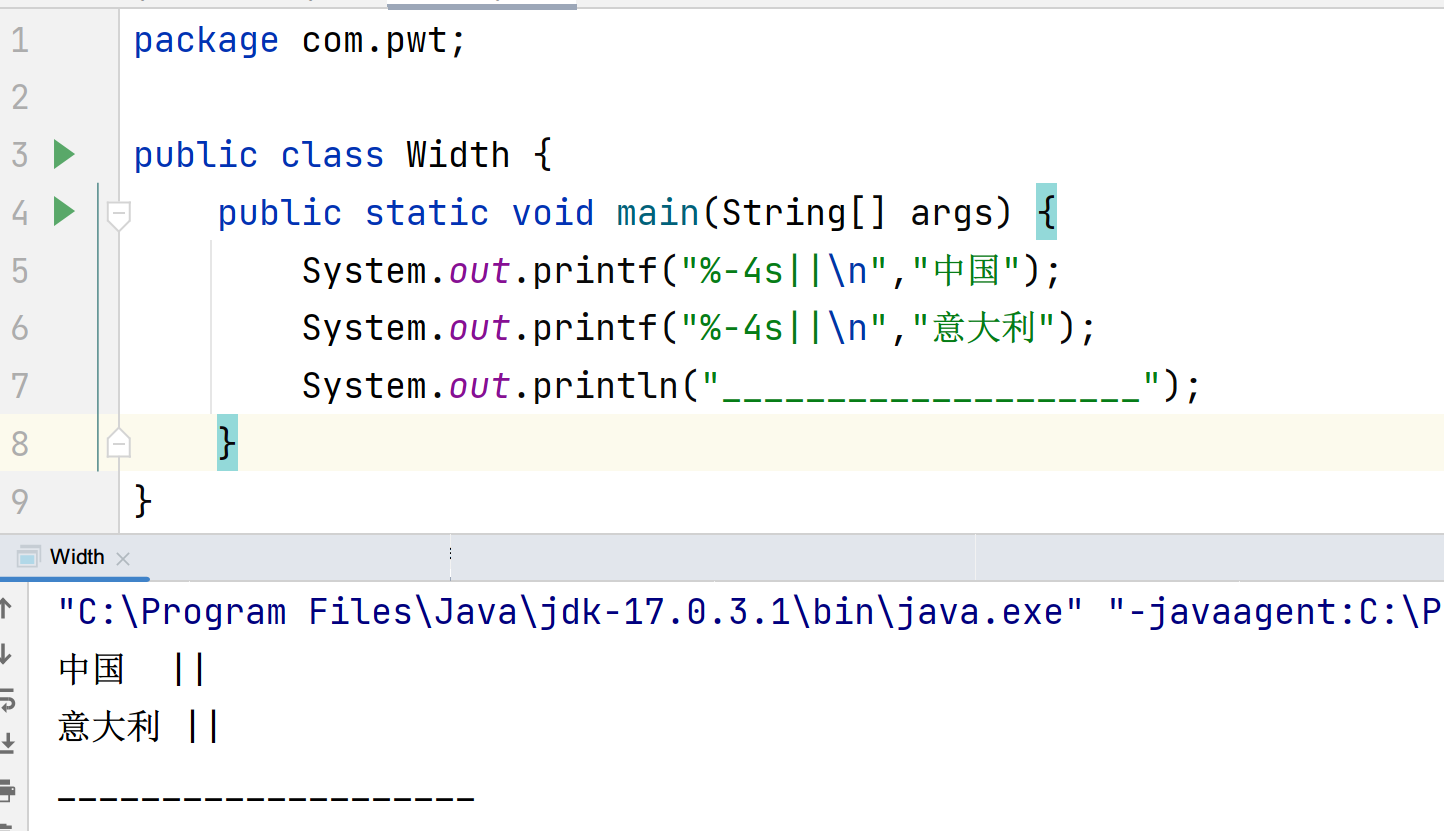
经过尝试,发现限制位宽后接一个制表符,中文的位宽跟实际宽度好像就对应起来了,可以认为是位宽按照实际宽度计算。
两者打印整齐了,并且正好是8格空格。
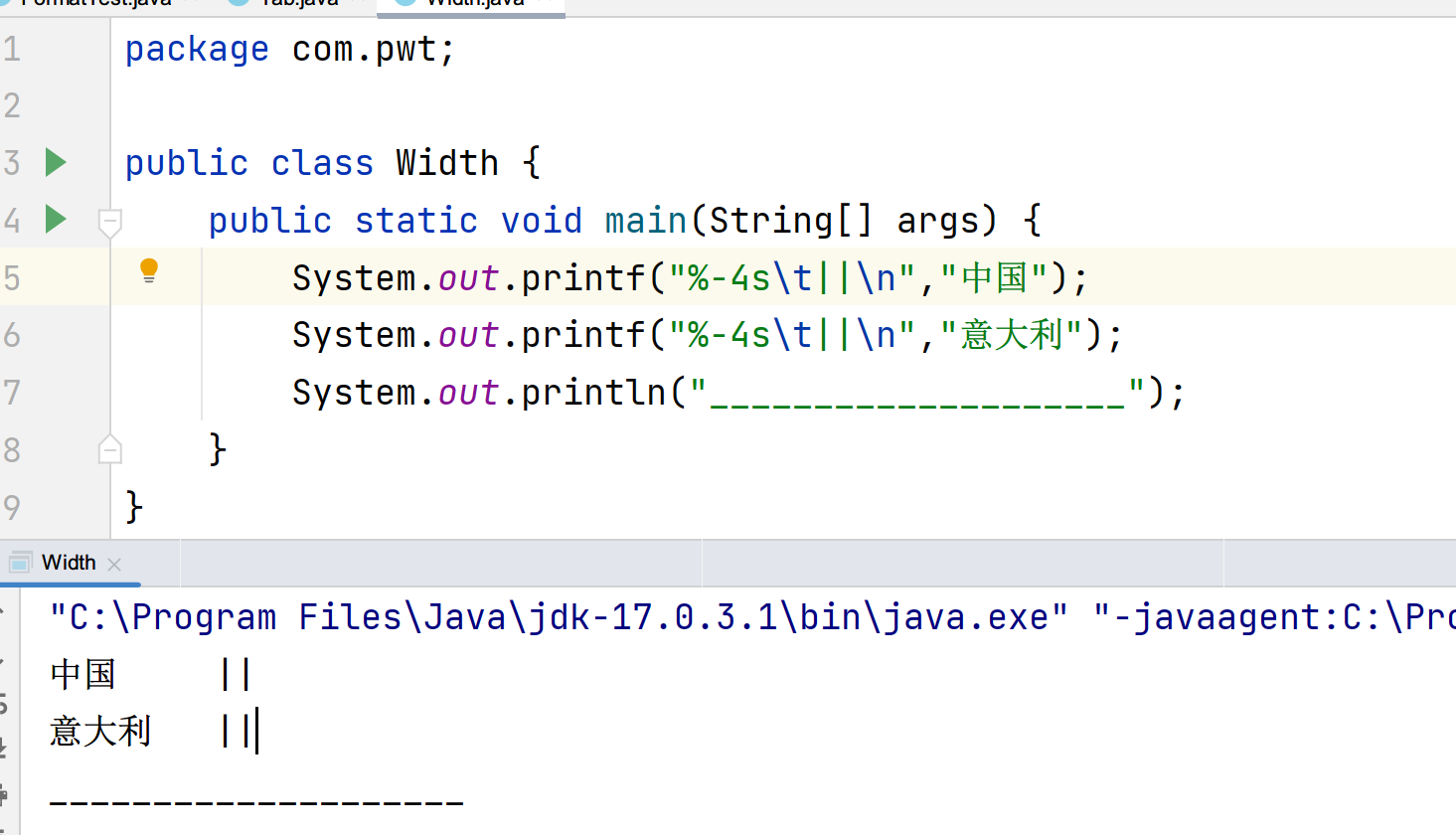
但这只解决了位宽的问题,灵活的制表符是我们打印时要考虑的另一个问题
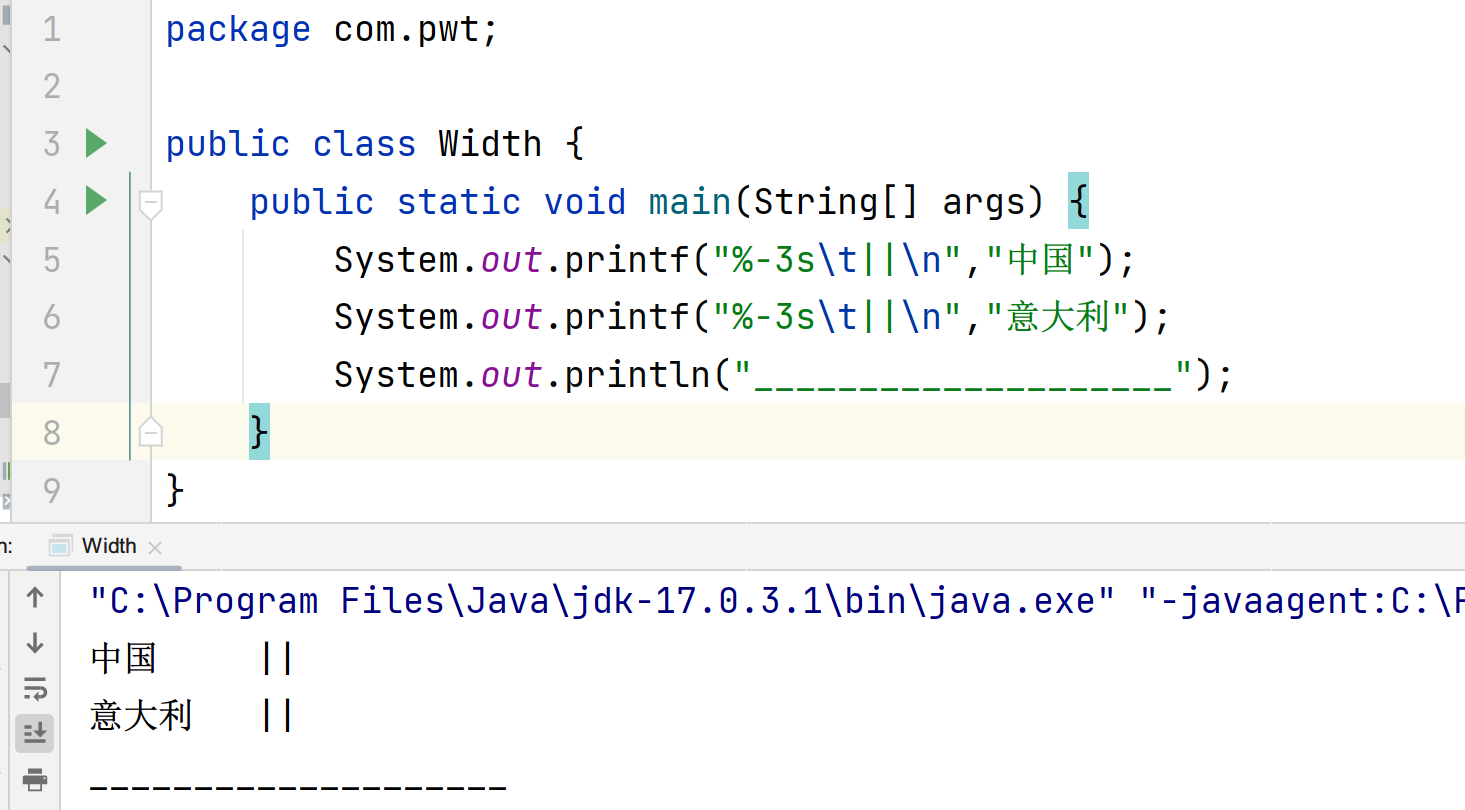
中国和意大利都超过了3格,而限制位宽当打印超过限制的会按照实际宽度打印,所以意大利5格\t就补到8格,但是中国就很奇怪,中国只有3格多一点点,加\t却补到了8格,难道是3格多一点点被认为是4格?
我们接着测试

这次将位宽限制至2,意大利仍然没问题,但我们却发现中国\t变成了4格(严格的4格,不多不少),那么上面3格多一点点被认为是4格的猜测是错误的。
那么另一种可能是3格加制表符\t补到8格(我以前就是这么认为的,网上都是说8位的规则),但这与我们最开始对制表符规则实践得到的结果不符(知道为什么我说灵活的制表符了吧(+_+) )
接着再尝试修改限制位宽数
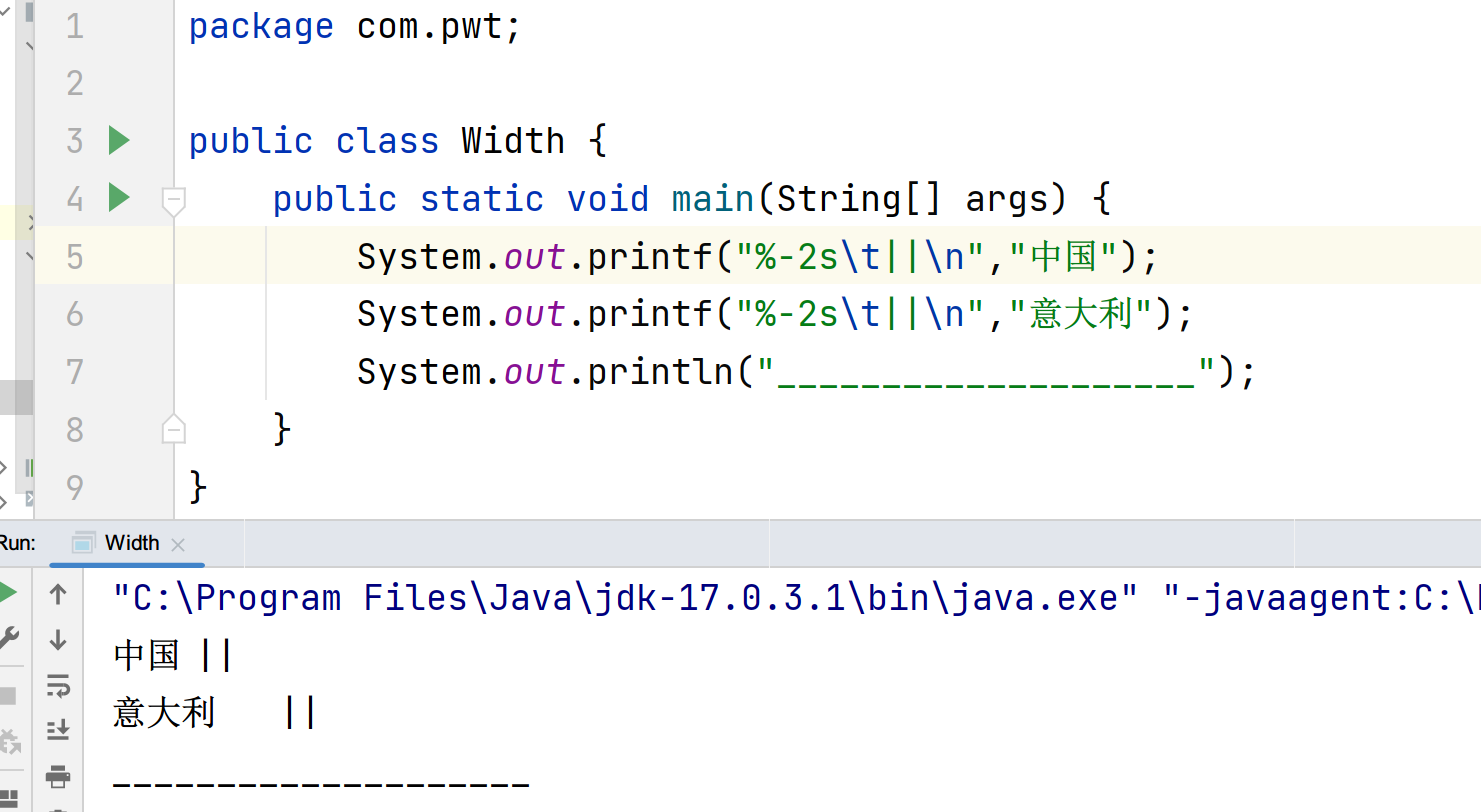
又出现了一个预料之外的情况,按照位宽和制表符规则,意大利应该是8格啊,这里却是12格。(%-5s时还是8格)
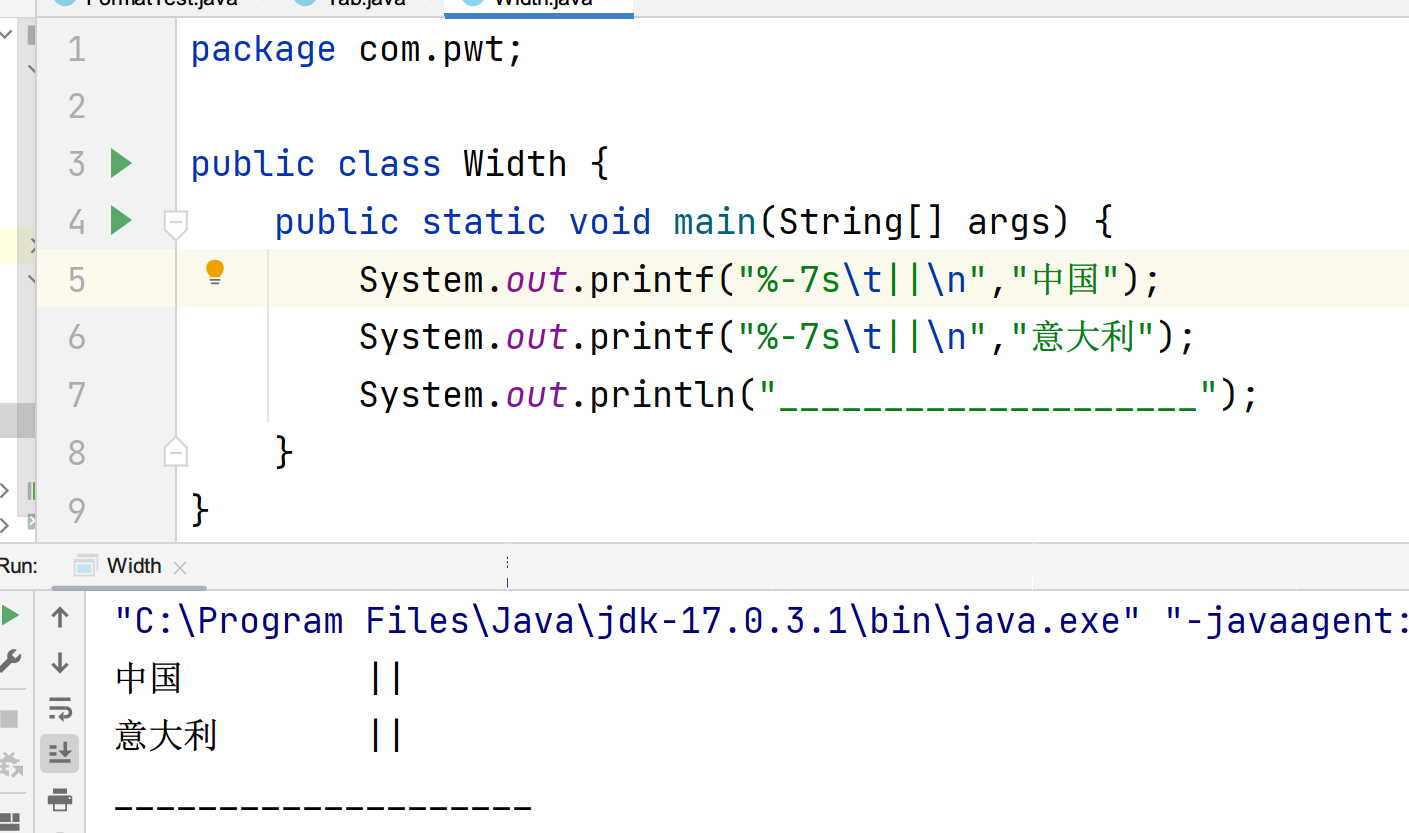
接着改成7,结果连中国都变成了12格。
如果接着测试,8,9都是12格,到10时,意大利变成了16格。11时中国也变成了16格。
到这里我仍然看不出来这到底是遵循了什么规则,但至少可以证明使用\t后位宽计算按照实际宽度是错误的。
也就是说位宽计算时中文仍然被认为是一个位宽。
那么出现上面这些情况就可以解释了。
%-2s时,中国刚好是两个位宽,不补,然后制表符按照中国实际宽度补,3格多一点会补到4格;意大利超过了两个位宽按照实际宽度打印,不会补格数,制表符按照5格来补,补到8格。
%-3时,中国算两个,那么需要补1个空格,中国实际宽度是3格多一点点,那么加上空格是4格多一点点,那么制表符就补到8格。意大利跟%-2s时情况一样。
注意到意大利实际5格,那么补3格将到8格,因此%-6s时限制位宽补3格,制表符补到12格。而%-7s时中国加上5个空格也到达了8格多,补到12格。
三、总结
最后也没找到完美解决的方法,但限制位宽加制表符是相对来说比较整齐的方法。实际上我想了一个方案,就是根据实际宽度不同来补不同数目\t。那么我需要找一个能够计算字符串打印长度的方法。这涉及到图形界面的知识,如果我们学到了图形界面,肯定不再使用控制台输出,而且图形绘制里可以指定坐标打印,还能控制字体大小,所以找一个计算控制台字符串打印长度的方法意义不大。(我寻找了但是没找到,实在没办法就放弃了)
这篇关于关于数据打印的详细探讨:如何才能打印得更整齐的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






