本文主要是介绍论文阅读(一)TransReID: Transformer-based Object Re-Identification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
养成每天读文献的习惯,随手一记,欢迎大家讨论指正~
论文代码地址:https://github. com/heshuting555/TransReID
一、解决的问题
1.CNN由于感受野有限,缺乏长距离依赖,引入attention机制并没有解决长距离依赖问题,基于attention的方法倾向于关注大的连续的区域,很难提取多个有判别力的部分,如图1所示:

2.CNN中下采样操作(如strided convolution和池化)会降低特征图分辨率,可能会丢失有用的细节信息,如图2所示,基于CNN的方法丢失了背包的细节部分

二、模块框架
首先介绍Transformer baseline的框架,如下图所示

首先将图片分为N个块(可以是重叠的,也可以是不重叠的,图中显示的是不重叠的),计算公式如下:
H,W分别是图片的高和宽,P是块的大小。文章采用的是重叠的patch块,公式如下:
S为步长大小,步长小于等于块的大小P,可以观察到的是步长越小,分的块越多,所需的计算成本越大。
输入序列embedding表示如下:
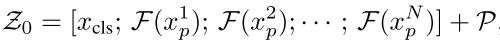
首先将N个块经过线性层投影到与P(位置向量)相同的维度,再附加上一个可学习的cls token,将这N+1个块都加上position embedding,经过 个transformer层得到特征表示,将输出的cls token作为全局特征表示
,并计算ID loss和Triplet loss。
注意,由于ReID任务的图像分辨率可能与图像分类中的原始分辨率不同,在ImageNet上预先训练的位置嵌入不能直接加载,且在计算loss时使用了训练技巧BNNeck。(关于BNNeck的详细内容请看这篇文章:TeddyZhang:行人重识别:Baseline and Tricks)
接下来介绍JPM和SIE模块,框架图如下:
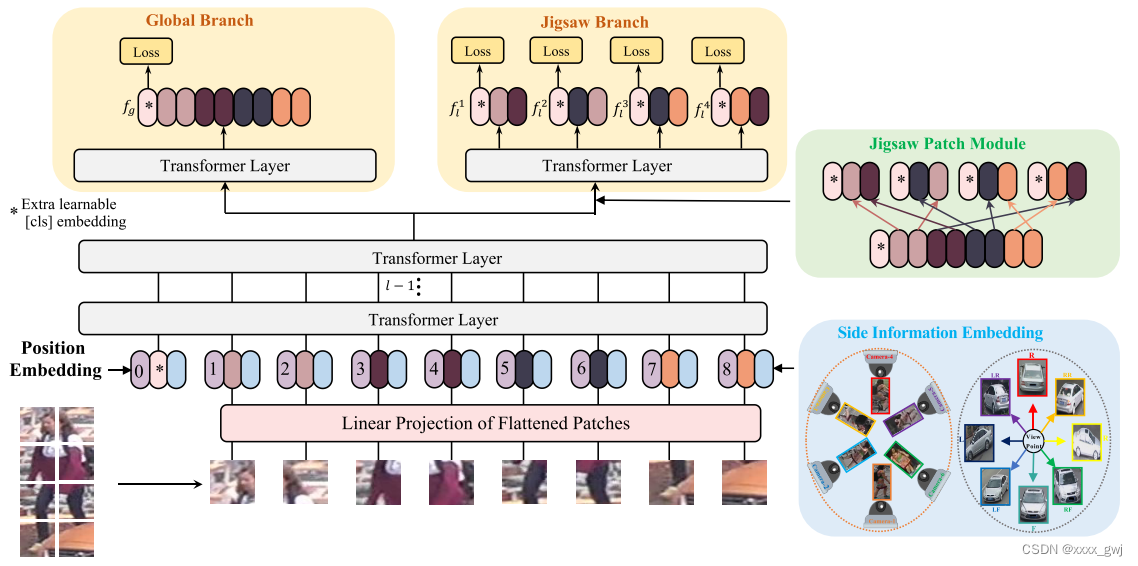
JPM模块旨在通过移位和洗牌操作增加扰动,从而增强模型鲁棒性,SIE将非视觉信息(如摄像机ID和视角)通过可学习的嵌入编码进输入嵌入。
JPM模块的具体做法如下:
假设transformer总共有 l 层,将 l−1 层的patch进行移位和shuffle操作。首先经过m次移位操作将前m个patch移到最后面(cls token不参与移位操作),表示如下:
![]()
然后将移位后的patch进行shuffle操作,得到如下表示:
![]()
将洗牌后的patch分为 k 组,每组附加一个共享的cls token。将 k 组嵌入经过一个transformer层得到JPM最终的输出,如下图所示:
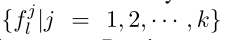
下面介绍SIE模块,由于特征容易受到摄像头、视角的影响,提出了将非可视信息以可学习的嵌入的形式附加到输入嵌入上。假设有 个摄像头和
个视角,则摄像头嵌入
表示为
,视角嵌入
表示为
。如何将这两种信息进行整合呢?由于相加可能会导致相互抵消,采用如下方式:
,最终输入嵌入表示为下式:
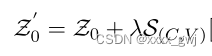
三、损失计算
计算ID loss(交叉熵损失)和Triplet loss(soft margin)
Triplet公式如下,其中 {a,p,n} 分别代表锚点,正样本和负样本,
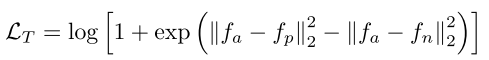
总的loss为全局特征和JPM模块后的分组特征分别计算ID loss和Triplet loss,公式如下:
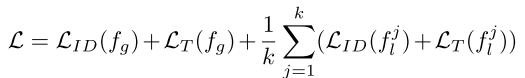
这篇关于论文阅读(一)TransReID: Transformer-based Object Re-Identification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







