本文主要是介绍Reids系列-Redis持久化与备份 【5】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- Reids系列-Redis持久化与备份 【5】
- Redis 持久化机制
- Reids持久化流程
- `RDB`持久化原理及配置
- `RDB` 快照持久化方式
- RDB 快照持久化优点
- `RDB` 快照持久化缺点
- 执行命令触发RDB持久化备份
- `AOF`持久化原理及配置
- `AOF` 快照持久化备份方式
- AOF文件重写
- `RDB` 与 `AOF` 的对比选择
- 数据备份与恢复
- 数据恢复
个人主页: 【⭐️个人主页】
需要您的【💖 点赞+关注】支持 💯
Reids系列-Redis持久化与备份 【5】
RDB快照持久化 【默认方式】AOF增量日志持久化【实时】
Redis 持久化机制
Reids持久化流程

持久化数据:就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了防止系统故障而将数据备份到一个远程位置。

Redis 的持久化方式有 RDB 和 AOF 两种
RDB持久化原理及配置
Redis 可以通过创建快照来获得存储在内存里面的数据。创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本( Redis 主从结构,主要用来提高 Redis 性能),还可以将快照留在原地以便重启服务器的时候使用
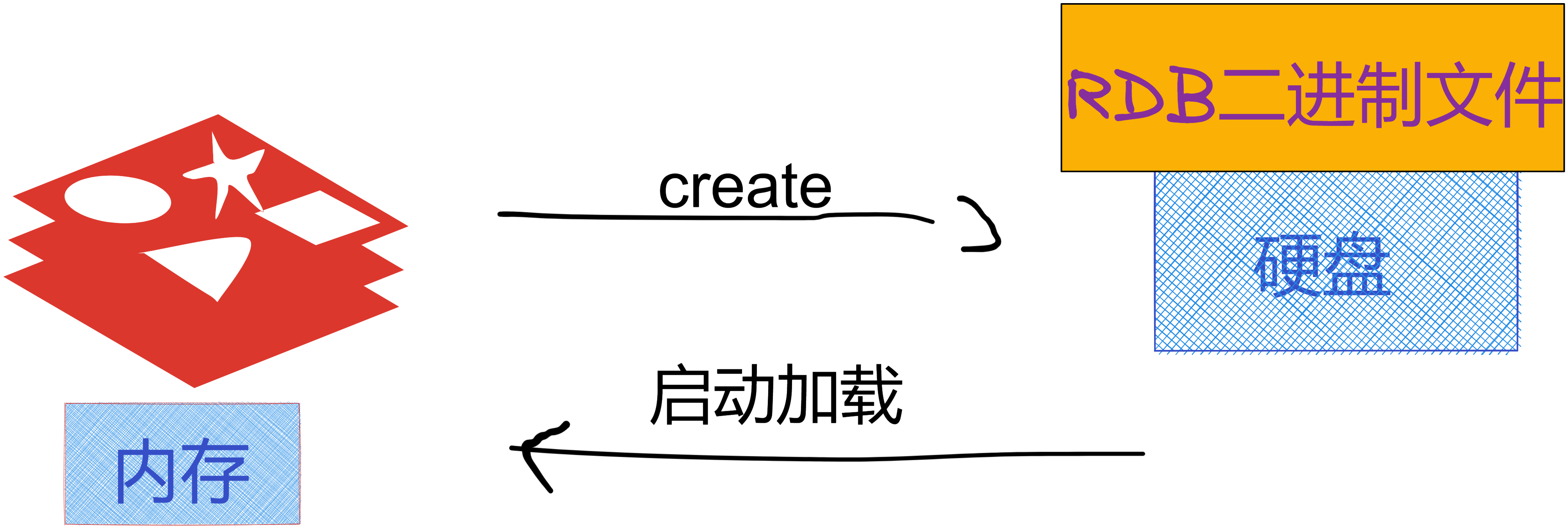
RDB 快照持久化方式
快照持久化是 Redis 默认采用的持久化方式,在 redis.conf 配置文件中默认有此如下配置 redis.conf
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""save 900 1
save 300 10
save 60 10000
# By default Redis will stop accepting writes if RDB snapshots are enabledRDB 快照持久化优点
-
文件小,适合做备份
RDB 是一个非常紧凑的文件,它保存了某个时间点的数据集,非常适用于数据集的备份,比如你可以在每个小时保存一下过去 24 小时内的数据,同时每天保存过去 30 天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集
-
适合灾难恢复
RDB 是一个紧凑的单一文件,很方便传送到另一个远端数据中心或者亚马逊的 S3 (可能加密),非常适用于灾难恢复
-
与 AOF 相比,在恢复大的数据集的时候,RDB 方式会更快一些
RDB 快照持久化缺点
- 耗时、耗性能
- 不可控、丢失数据
执行命令触发RDB持久化备份
save【不建议使用】save命令是一个同步操作,执行该命令后,RDB持久化是在主进程中进行的,这样会阻塞当前redis服务,直到RDB持久化完成后,客户端才能正常连接redis服务。
bgsave【推荐】bgsave命令是对save命令的一个优化,是一个异步操作。执行该命令后,redis主进程会通过fork操作创建一个子进程,RDB持久化是由子进程操作,完成后自动结束。这个过程中,主进程不阻塞,可以继续接收客户端的访问。
因此,redis内部所有涉及RDB持久化的操作都是采用的bgsave方式,save命令基本已经废弃。

shutdown
这种触发方式比较简单,只需要在客户端执行shutdown命令即可:flushallflushall命令是清空redis内存中的数据,并且同时清空dump.rdb文件。所以这个命令就相当于删库跑路,此处只是说明该命令会触发rdb,实际使用中千万不要执行。
如果之前没有dump.rdb文件,则执行flushall命令后,会生成一个dump.rdb文件:
AOF持久化原理及配置
与快照 RDB 持久化相比,AOF 持久化的实时性更好,因此已成为主流的持久化方案。默认情况下 Redis 没有开启 AOF 方式的持久化,可以通过 appendonly 参数开启
############################## APPEND ONLY MODE ################################ By default Redis asynchronously dumps the dataset on disk. This mode is
# good enough in many applications, but an issue with the Redis process or
# a power outage may result into a few minutes of writes lost (depending on
# the configured save points).
#
# The Append Only File is an alternative persistence mode that provides
# much better durability. For instance using the default data fsync policy
# (see later in the config file) Redis can lose just one second of writes in a
# dramatic event like a server power outage, or a single write if something
# wrong with the Redis process itself happens, but the operating system is
# still running correctly.
#
# AOF and RDB persistence can be enabled at the same time without problems.
# If the AOF is enabled on startup Redis will load the AOF, that is the file
# with the better durability guarantees.
#
# Please check http://redis.io/topics/persistence for more information.
appendonly no
开启 AOF持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入硬盘中的 AOF 文件。AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 dir 参数设置的,默认的文件名是 appendonly.aof
AOF 快照持久化备份方式
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式,它们分别是
appendfsync always客户端对redis服务器的每次写操作都写入AOF日志文件。这种方式是最安全的方式,但每次写操作都进行一次磁盘IO,非常影响redis的性能,所以一般不使用这种方式。
appendfsync everysec【默认】每秒刷新一次缓冲区中的数据到AOF文件。这种方式是redis默认使用的策略,是考虑数据完整性和性能的这种方案,理论上,这种方式最多只会丢失1秒内的数据。
appendfsync noredis服务器不负责将数据写入到AOF文件中,而是直接交给操作系统去判断什么时候写入。这种方式是最快的一种策略,但丢失数据的可能性非常大,因此也是
不推荐使用的
为了兼顾数据和写入性能,用户可以考虑 appendfsync everysec 选项(AOF 默认使用) ,让 Redis 每秒同步一次 AOF 文件,Redis 性能几乎没受到任何影响。
而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度
AOF文件重写
既然AOF是通过日志追加的方式来存储redis的写指令,那么当我们对同一个key做多次写操作时,就会产生大量针对同一个key操作的日志指令,导致AOF文件会变得非常大,恢复数据的时候会变得非常慢。因此,redis提供了重写机制来解决这个问题。redis通过重写AOF文件,保存的只是恢复数据的最小指令集。
我们可以通过下面命令手动触发重写:bgrewriteaof。
也可以通过配置文件自动触发重写:
# :当文件的大小达到原先文件大小(上次重写后的文件大小,如果没有重写过,那就是redis服务启动时的文件大小)的两倍。
auto-aof-rewrite-percentage 100
# :文件重写的最小文件大小,即当AOF文件低于64mb时,不会触发重写。
auto-aof-rewrite-min-size 64mb # 只有这两个指标同时满足的时候才会发生重写。
RDB 与 AOF 的对比选择
| - 指标 - | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 文件大小 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 丢数据 | 根据策略决定 |
数据备份与恢复
数据恢复
1、RDB数据恢复
Redis启动后会读取RDB快照文件,将数据从硬盘载入到内存,根据数据量大小与结构和服务器性能不同,通常将一个记录一千万个字符串类型键、大小为1GB的快照文件载入到内存中需花费20~30秒钟。
2、AOF数据恢复
重新启动Redis后 ,Redis会使用AOF文件来恢复数据,因为AOF方式的持久化可能丢失的数据更少,可以在redis.conf中通过appendonly参数开启Redis AOF全持久化模式。
这篇关于Reids系列-Redis持久化与备份 【5】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







