本文主要是介绍mysql 进行数据全库备份使用mysqldump,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
mysql数据库提供了一个很好用的工具mysqldump用以备份数据库,下面将使用mysqldump命令进行备份所有数据库以及指定数据库
一、mysqldump一次性备份所有数据库数据
/usr/local/mysql/bin/mysqldump -u用户名 -p密码 --all-databases > /保存路径/文件名.sql

注意:以上命令直接在控制台输入即可,无须登录进入数据库操作界面
以上命令执行后,你就可以在对应路径下,找到你的备份sql文件了
二、mysqldump 一次性备份指定的多个数据库数据
/usr/local/mysql/bin/mysqldump -u用户名 -p密码 --databases 数据库1 数据库2... > 保存路径/文件名.sql
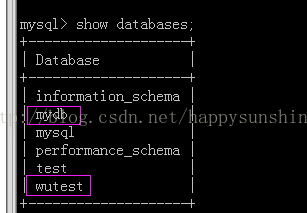

注意:使用以上两种方式备份的数据库,会将数据库的创建语句一起进行了备份。因此,还原时,无须先创建数据库再进行还原。有一些远程连接数据库的工具,
也提供了备份的功能,但备份的sql文件中,不一定备份了数据库创建语句,因此,还原时,要保存数据库已经创建了,否则还原不了。
三、使用source 命令恢复数据库
使用source 命令,需要先登录数据库,在数据库操作界面调用该指令进行还原,语法如下
source 路径/文件名.sql
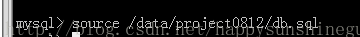
以上就是使用mysqldump进行整库备份以及还原的过程
这篇关于mysql 进行数据全库备份使用mysqldump的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









