本文主要是介绍全球10米土地覆盖产品(ESA)数据集2020和2021年,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
全球10米土地覆盖产品(ESA)来源于欧空局,是基于哨兵一号、哨兵二号数据制作的2020年的10m分辨率的全球土地覆盖数据。土地利用数据一共分为11类,分别是:林地、灌木、草地、耕地、建筑、裸地/稀疏植被区、雪和冰、开阔水域、草本湿地、红树林、苔藓。经验证,数据精度达到74.4%。前言 – 人工智能教程
欧洲空间局的全球10米土地覆盖产品(ESA's Global Land Cover)是一种高分辨率土地覆盖数据集,采用多源遥感数据和机器学习算法生成。这个数据集提供了全球每个地方在特定时间的土地覆盖类型信息,包括树林、草地、农田、城市、水域等。这个数据集对于环境监测、自然资源管理、气候变化研究等方面十分有用。前言 – 人工智能教程
全球10米土地覆盖数据在以下方面具有重要作用:
1. 环境监测:该数据集可用于监测土地利用变化、森林覆盖率变化和自然保护区的扩张,以帮助开展环境监测和保护工作。
2. 自然资源管理:该数据集可用于协助管理自然资源,如农业、林业、水资源等。这有助于制定农业政策、合理管理林区、划定保护区域以及管理水资源。
3. 气候变化研究:土地覆盖与气候变化是密切相关的。该数据集可用于检测气候变化、制定减缓策略和适应措施,并评估这些措施的效果。
4. 城市规划:由于全球城市化进程加速,对城市规划的需求也增加了。该数据集可用于城市规划和土地利用规划,以制定高效城市化和公平城市化的政策。
5. 地球科学:全球10米土地覆盖数据对于地球科学研究也具有重要意义,如土地地貌、岩性、土地退化、地震地质等方面的研究。
数据集ID:
ESA/WORLD_COVER_2020
时间范围: 2020年-2020年
范围: 全球
来源: ESA WorldCover project 2020
复制代码段:
var images = pie.ImageCollection("ESA/WORLD_COVER_2020")
波段
| 名称 | 类型 | 无效值 | 空间分辨率(m) | 描述信息 |
|---|---|---|---|---|
| B1 | Byte | 0 | 10m | 全球10米土地覆盖产品(ESA),类别信息见下表 |
| 类别 | 代码 |
|---|---|
| Tree Cover | 10 |
| Shrubland | 20 |
| Grassland | 30 |
| Cropland | 40 |
| Built-up | 50 |
| Bare/sparse vegetation | 60 |
| Snow and ice | 70 |
| Permanent water bodies | 80 |
| Herbaceous wetland | 90 |
| Mangroves | 95 |
| Moss and lichen | 100 |
代码:
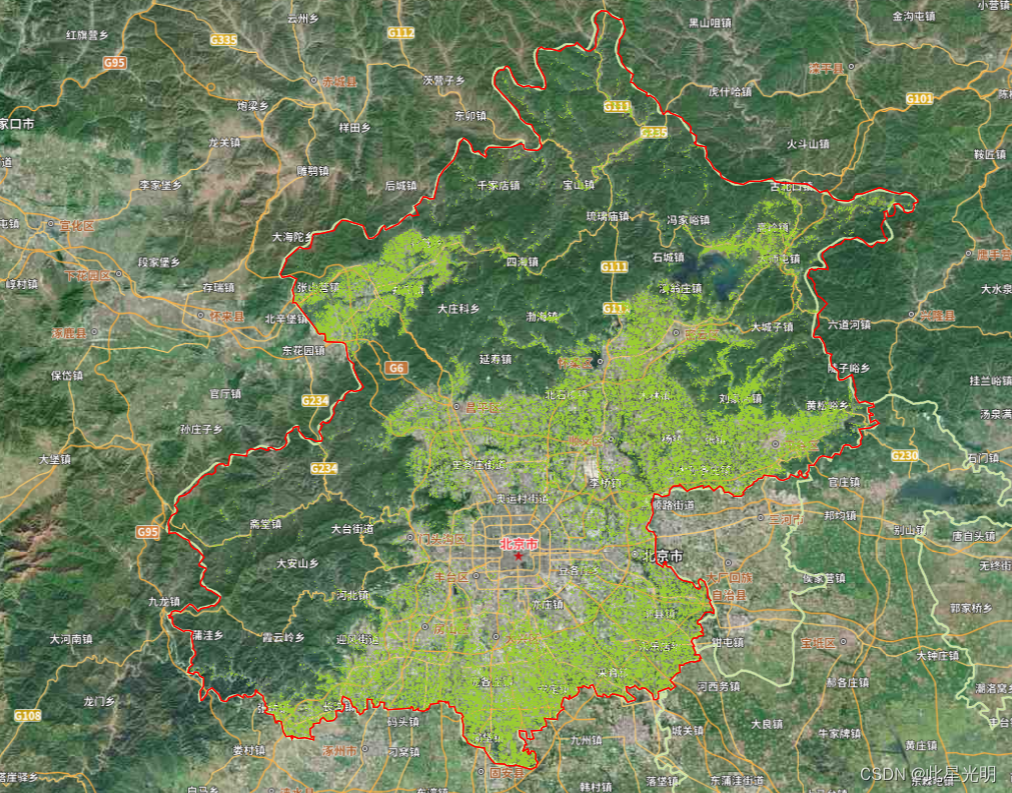
/*** @File : 全球10米土地覆盖产品(ESA)* @Time : 2021/11/26* @Author : pieadmin* @Version : 1.0* @Contact : 400-890-0662* @License : (C)Copyright 航天宏图信息技术股份有限公司* @Desc : 加载全球10米土地覆盖产品(ESA)数据集*///加载显示北京市矢量边界数据
var bj = pie.FeatureCollection("NGCC/CHINA_CITY_BOUNDARY").filter(pie.Filter.eq("name", "北京市")).first().geometry();
Map.centerObject(bj, 9);
Map.addLayer(bj, {color: "ff0000ff", fillColor: "00000000", width: 1}, "北京市");//加载显示全球10米土地覆盖产品(ESA)数据集并筛选耕地
var img = pie.ImageCollection('ESA/WORLD_COVER_2020')
var img = pie.ImageCollection('ESA/WORLD_COVER_2021').select("B1").filterBounds(bj).mean().clip(bj).eq(40);
var visParam = {min: 0,max: 1,palette: ['000000','9acd32']
};
//加载显示耕地
Map.addLayer(img.updateMask(img.eq(1)),visParam, "crop")文章引用:
Zanaga,D.,Van De Kerchove,R.,De Keersmaecker,W.,Souverijns,N.,Brockmann,C.,Quast,R.,Wevers,J.,Grosu,A.,Paccini,A.,Vergnaud,S.,Cartus,O.,Santoro,M.,Fritz,S.Georgieva,I.,Lesiv,M.,Carter,S.,Herold,M.,Li,Linlin,Tsendbazar,N.E.,Ramoino,F.,Arino,O.,2021.ESA WorldCover 10 m 2020 v100.https://doi.org/10.5281/zenodo.5571936
这篇关于全球10米土地覆盖产品(ESA)数据集2020和2021年的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







